Optimize SegmentsCostCache#12419
Conversation
| private final long intervalEndMillis; | ||
| @Nullable | ||
| private final Chronology intervalChronology; | ||
| private final Interval interval; |
There was a problem hiding this comment.
The comment above mentions that interval is not stored, on purpose, in order to reduce heap usage of SegmentId. Presumably that refers to heap usage on Coordinators and Brokers for clusters that have a large number of segments.
Is it important for performance that the interval be cached?
There was a problem hiding this comment.
The impact when using the current approach is insignificant, and this change can be avoided
|
Very interesting! What's the bottom line? Can we expect Coordinator runs to speed up for clusters with large numbers of segments, and if so by how much? |
@gianm Yes, we can expect a speedup but we might have to run proper benchmarks / collect metrics on a large cluster to get a good idea. Could you also please share any insights to estimate a ballpark performance change? |
If this work is inspired by a real world scenario, you could build a performance test or benchmark similar to that scenario. IMO that's the best way to approach this kind of thing, because otherwise it can be tough to make sure you're attacking an actual bottleneck. |
Or maybe you've already done enough performance testing (you do have some numbers in the original description) and the issue is just that I don't understand how much of a difference we can expect. For example, you said that SegmentsCostCache sped up from 39807ms to 189ms with 100k random segments. How does this relate to the expected overall time that Coordinator run would take for that setup? |
The cost in a "stable" state will reduce significantly. The bottleneck is startup with a large number of segments or when there are several segments waiting to be loaded / dropped. I do have an approach in mind and will try to run a benchmark simulating these scenarios |
|
Closing this PR. New changes in #13254 |
Goal
SegmentsCostCacheequivalent to the default cost strategy for all segments - across the cache.CachingCostBalancerStrategyTLDR;
The current default cost strategy requires a summation across all segments each time and can be slow to compute costs.
SegmentsCostCacheaimed to make it faster using the idea of buckets but was not identical.It has now been made equivalent to the above strategy as part of this PR, and is significantly faster than the orignal cost.
SegmentsCostCacheV3is a new implementation introduced in this PR which is several times faster.Time to insert 100k random segments across multiple buckets and build cache:
SegmentsCostCache :
39807 milliseconds-> O(N ^ 2)SegmentsCostCacheV3 :
189 milliseconds-> O(NlogN)The complexity for default cost computation is O(N)
Caching cost improves it by a constant factor determined by the segment interval distribution.
The new caching cost reduces the complexity from O(N) to O(logN) for computeCost operations.
Time to compute joint cost across all (100k) segments (averaged over 1k runs):
Default strategy:
28757 microseconds-> O (N)SegmentsCostCache:
8728 microseconds-> O(N) / pruning constantSegmentsCostCacheV3:
13 microseconds-> O(logN)For a cluster with a large number of segments, the bottleneck was computing cost across all segments present.
The time to compute this now is insignificant, and the new bottleneck is computing the cost across all segments in a load / drop state
NOTE:The performance the overall CachingCostBalancerStrategy is unlikely to be as much faster as these numbers reflect.
This is because we still need to fetch and compute the cost across all segments to be loaded and dropped as well.
If there are N segments in total and M segments in load / drop state for a given server:
O(N)CachingCostBalancerStrategyisO(logN + M ^ 2). It also currently has a few inaccuracies.O(logN + M)by fixing the existing bugs / redundancies.Description
#2972 proposes a cost function for Segment balancing.
The pairwise cost function of two segments decreases with an increase in their intervals' "distance".
The overall cost for a target segment is the sum of its pairwise cost across all segments present.
The idea of computing using buckets was introduced in
SegmentsCostCache.Subsets of segments are stored in "buckets" around a specified interval to to avoid unnecessary computations with negligible contribution as distance between segments increases.
Buckets also store certain precomputed sums to reduce calculations when segments are added or removed.
Make SegmentsCostCache's cost function identical to original function (DONE)
The cost returned by SegmentsCostCache was "almost" proportional to CostBalancerStrategy.
Consider segment set with intervals: { [1, 10], [3, 5] }
If we were to try to compute the cost wrt a segment with interval [7, 15], the previous code would have computed the cost for the pair ([1, 10], [7, 15]) incorrectly.
This is because once a value on its left doesn't overlap, all the elements further before are assumed to not overlap either, which is incorrect. (when segments of various interval lengths are present)
This has been rectified.
With these changes, the costs computed differ by a constant multiplication factor of [(24 / ln(2)) ^ 2] or ~ 1198.868
This can be proven :)
It's easy to use the same units for half life and other constants in both classes and compare the cost computation side by side to see that they are proportional.
Tests have been added to verify the equivalence.
Fix CachingCostBalancerStrategy (TODO)
The overall cost = cost across all segments + cost across segments to be loaded - cost across segments to be dropped
computeCostdoesn't subtract the cost across dropping segments, and this needs to be fixed.New approach (DONE)
Old caching code:
The cost corresponding to a target segment with all the segments in a bucket can be computed by iterating the set of segments whose intervals overlap with it, and computing the sum of their pairwise costs. Iterating through the list of overlapping intervals is still O(N), even if less by a constant factor.
New caching code: (See
SegmentsCostCacheV3)We still utilize the idea of buckets but use a few mathematical properties to make cost computation faster
The cost function is of the form:
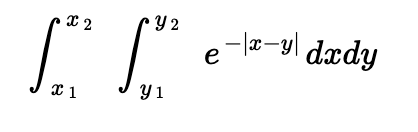
Where <x1, x2> is the interval of the segment in the bucket, and <y1, y2> is the interval of the segment whose cost is being computed.
The integral from {x1 -> x2} can be computed as {x1 -> end } - {x2 -> end} as follows:
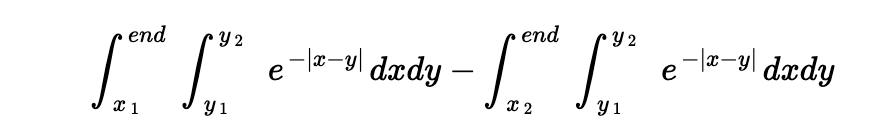
Where end is the bucket's interval's end. This property facilitates us to expand and group the summation of the function across a bucket in a manner which can utilize prefix sums of the natural exponents for the overall function.
Each of the six cases for alignment of <x, end>, <y1, y2> has a different reduced form for the integral and the sum over all these cases gives the overall cost.
Both segment addition / removal become an O(1) operation.
Bucket building remains to be O(NlogN) due to sorting
Cost computation over a bucket of size N becomes an O(logN) operation
NOTE:
The purpose of bucketing for the new approach is different from that for the old caching one.
The old approach had a slow update time when segments were added / removed to a bucket, and an appropriate size for buckets was a required tradeoff.
The new approach has a negligible update time, and could have ideally stored all segments in a single bucket.
However, the end of the bucket's reference interval plays a key role in calculation, and a high value can lead to double overflows.
So, we still need to bucket intervals by time. However, we are now allowed to use a higher value (provided there is no overflow) than before, and that improves the overall cost computation time even further
Scope for future work
Since the number of loading / unloading segments (M) can be high at times, the cost complexity O(M + logN) is not ideal.
The current CachingCostStrategy can only compute cost after building which is a costly operation of O(NlogN).
Introduce new APIs that return only the difference set of loading / dropping segments after a CachingCostStrategy has been initialized.
A new implementation which supports cost computation without an offline build would utilize the above APIs and compute the cost.
(Achievable with a Treap with lazy propogation which supports O(logN) insert / remove / range update / range queries)
The above changes would mean that the first cost computation is O(M). Subsequent cost computations would only be O(logN + logM).
This PR has: