Unnest changes for moving the filter on right side of correlate to inside the unnest datasource#13934
Conversation
…inside the unnest cursors. Added tests for scenarios such as 1. filter on unnested column which involves a left filter rewrite 2. filter on unnested virtual column which pushes the filter to the right only and involves no rewrite 3. not filters 4. SQL functions applied on top of unnested column 5. null present in first row of the column to be unnested
…ate the filter inside the data source
…of project before the filter on top of uncollect
…h the project LITERAL path
…ating a new or on input dimension with the entire filter appearing post unnest also
 imply-cheddar
left a comment
imply-cheddar
left a comment
There was a problem hiding this comment.
I think there are some logic bugs still. Likely, we need a data set that has more rows and matches/skips various different rows based on different conditions.
| final Set<String> requiredColumns = filter.getRequiredColumns(); | ||
|
|
||
| // Run filter post-correlate if it refers to any virtual columns. | ||
| // Run filter post-unnest if it refers to any virtual columns. |
There was a problem hiding this comment.
Make this
// Run filter post-unnest if it refers to any virtual columns. This is a conservative judgement call
// that perhaps forces the code to use a ValueMatcher where an index would've been available,
// which can have real performance implications. This is an interim choice made to value correctness
// over performance. When we need to optimize this performance, we should be able to
// create a VirtualColumnDatasource that contains all of the virtual columns, in which case the query
// itself would stop carrying them and everything should be able to be pushed down.
| if (unnestFilter instanceof AndFilter) { | ||
| for (Filter filter : ((AndFilter) unnestFilter).getFilters()) { | ||
| filterSplitter.addPostFilterWithPreFilterIfRewritePossible(filter); | ||
| } | ||
| } else { | ||
| filterSplitter.add(queryFilter); | ||
| filterSplitter.addPostFilterWithPreFilterIfRewritePossible(unnestFilter); | ||
| } |
There was a problem hiding this comment.
Is there a specific reason that we are breaking up the unnestFilter here? Or is this a reflection of a C&P of the logic for the normal filters?
There was a problem hiding this comment.
We break it up in the case of AND so that we can find out if one of them can be added to the pre filters through re-write. Adding to pre-filters takes place inside addPostFilterWithPreFilterIfRewritePossible method
There was a problem hiding this comment.
This can be made without breaking up, refactored
| * Allows subquery elimination. | ||
| * | ||
| * @see CorrelateFilterRTransposeRule similar, but for right-hand side filters | ||
| * @see DruidFilterUnnestRule similar, but for right-hand side filters |
There was a problem hiding this comment.
Is this comment legitimate?
There was a problem hiding this comment.
The filter unnest rule does handle the filters on the right which is the top of uncollect though
There was a problem hiding this comment.
Sorry, is this comment telling me that I should expect the DruidFilterUnnestRule to be the same code as this? I'm not sure why this is telling me to see that other one?
There was a problem hiding this comment.
I think I removed it
| if (unnestFilter != null) { | ||
| return virtualColumn.equals(that.virtualColumn) && unnestFilter.equals(that.unnestFilter) | ||
| && base.equals(that.base); | ||
| } else { | ||
| return virtualColumn.equals(that.virtualColumn) && base.equals(that.base); | ||
| } |
There was a problem hiding this comment.
This is an odd equals implementation. If the current object's unnestFilter is null, then the that object can have any unnest filter it wants?
Generally speaking, I suggest letting IntelliJ generate your equals and hashCode. (I'm assuming that perhaps you adjusted it yourself?)
| List<Filter> preFilterList = new ArrayList<>(); | ||
| List<Filter> postFilterList = new ArrayList<>(); |
There was a problem hiding this comment.
The preFilterList, postFilterList here is very confusing and easy to mix up with the filterSplitter... I'm not sure how to separate it exactly, but I almost thought that these were getting AND'd together because I confused them with the FilterSplitter filters.
| for (Filter filter : ((OrFilter) queryFilter).getFilters()) { | ||
| if (filter.getRequiredColumns().contains(outputColumnName)) { | ||
| final Filter newFilter = rewriteFilterOnUnnestColumnIfPossible(filter, inputColumn, inputColumnCapabilites); | ||
| if (newFilter != null) { |
There was a problem hiding this comment.
you are doing an if/else with a negative condition. Please invert it. If you are doing an if/else please always make the condition carry as few negations as possible.
| // any rows that do not match this filter at all. | ||
| preFilters.add(newFilter); | ||
| preFilterList.add(newFilter); | ||
| postFilterList.add(newFilter); |
There was a problem hiding this comment.
postFilter should be the original filter, I think?
There was a problem hiding this comment.
This has been refactored with comments
| preFilterList.add(newFilter); | ||
| postFilterList.add(newFilter); | ||
| } else { | ||
| postFilterList.add(filter); |
There was a problem hiding this comment.
If it's not re-writable, then I don't think the OR can be pushed down at all. If you only pushdown the things that don't refer to the output of the unnest, you run the risk of not including some rows that should've been included. It should be relatively easy to test for this. If there's a query with an MV_TO_STRING(unnested_dim, 'a') = 'b' OR other_dim = 'a', I don't think it'll believe that it can remap it. If it pushes down the other_dim = a without attempting to push down the first part of the OR, it will not include a row where nested_dim is ["b"] and other_dim is "c".
There was a problem hiding this comment.
Added test cases to mimic all the different cases
| } | ||
| } | ||
| } | ||
| if (!preFilterList.isEmpty()) { |
There was a problem hiding this comment.
Anotehr if/else on negative logic. Keep it positive please.
| } | ||
|
|
||
| if (!postFilterList.isEmpty()) { | ||
| AndFilter andFilter = new AndFilter(postFilterList); |
There was a problem hiding this comment.
Why are these AND'd? Didn't they come from an OR?
|
Simplified the code for adding filters, added comments on how the rewriting is done and changed some variable names to make things easier to read |
| public void test_unnest_adapters_with_no_base_filter_active_unnest_filter() | ||
| { | ||
|
|
||
| Sequence<Cursor> cursorSequence = UNNEST_STORAGE_ADAPTER2.makeCursors( | ||
| null, | ||
| UNNEST_STORAGE_ADAPTER2.getInterval(), | ||
| VirtualColumns.EMPTY, | ||
| Granularities.ALL, | ||
| false, | ||
| null | ||
| ); | ||
|
|
||
| cursorSequence.accumulate(null, (accumulated, cursor) -> { | ||
| ColumnSelectorFactory factory = cursor.getColumnSelectorFactory(); | ||
|
|
||
| DimensionSelector dimSelector = factory.makeDimensionSelector(DefaultDimensionSpec.of(OUTPUT_COLUMN_NAME)); | ||
| int count = 0; | ||
| while (!cursor.isDone()) { | ||
| Object dimSelectorVal = dimSelector.getObject(); | ||
| if (dimSelectorVal == null) { | ||
| Assert.assertNull(dimSelectorVal); | ||
| } | ||
| cursor.advance(); | ||
| count++; | ||
| } | ||
| Assert.assertEquals(1, count); | ||
| Filter unnestFilter = new SelectorDimFilter(OUTPUT_COLUMN_NAME, "1", null).toFilter(); | ||
| VirtualColumn vc = new ExpressionVirtualColumn( | ||
| OUTPUT_COLUMN_NAME, | ||
| "\"" + COLUMNNAME + "\"", | ||
| null, | ||
| ExprMacroTable.nil() | ||
| ); | ||
| final String inputColumn = UNNEST_STORAGE_ADAPTER2.getUnnestInputIfDirectAccess(vc); | ||
| Pair<Filter, Filter> filterPair = UNNEST_STORAGE_ADAPTER2.computeBaseAndPostUnnestFilters( | ||
| null, | ||
| unnestFilter, | ||
| VirtualColumns.EMPTY, | ||
| inputColumn, | ||
| INCREMENTAL_INDEX_STORAGE_ADAPTER.getColumnCapabilities(inputColumn) | ||
| ); | ||
| SelectorFilter left = ((SelectorFilter) filterPair.lhs); | ||
| SelectorFilter right = ((SelectorFilter) filterPair.rhs); | ||
| Assert.assertEquals(inputColumn, left.getDimension()); | ||
| Assert.assertEquals(OUTPUT_COLUMN_NAME, right.getDimension()); | ||
| Assert.assertEquals(right.getValue(), left.getValue()); | ||
| return null; | ||
| }); | ||
| } | ||
|
|
There was a problem hiding this comment.
The structuring of this test for the purposes of validating that the filters are being managed properly seems a bit off. All of the decisioning of what should be pushed down and what shouldn't will have been done when you call makeCursors and you should be able to see it from there.
Specifically, we want to validate that it chose to push down specific filters and that it attached other filters to a PostJoinCursor.
You can have a TestStorageAdapter that exists just to have makeCursor called on it. You can store the values that were called and then return a Sequence<Cursor> where the Cursor objects are also just empty implementations.
Then, in the test, you can ask your TestStorageAdapter for which filters it was called with and validate that it's the ones you expect to be pushed down. You then take the cursors and validate that they are PostJoinCursor objects, then reach in and grab their filters (or it might need to be the ValueMatchers) and ensure that those filters are what you expect.
There was a problem hiding this comment.
My goal is to see if the lhs and rhs of filter splitter are correct because those are the parts that gets pushed down or to the PostJoinCursor and this kind of does that. I can also validate that the cursor I get after makeCursor is actually a PostJoinCursor. Atm we do not have a method on the cursor to get the filter passed to it so I was calling the method which modifies the filters to validate. Thanks for the feedback, I'll try to refactor the tests based on the suggestions
There was a problem hiding this comment.
Yeah, this test is calling the methods that the implementation should call. Essentially trying to mimic the actual implementation and making sure that it does the right thing. That's a fine test, if you assume that the base implementation will never change outside of these methods. But as soon as someone changes the implementation outside of one of these methods, the tests will no longer validate what we want to validate.
It's better to focus on testing the contract of the object. The contract in this case is that it is given some filters on makeCursors and some of those should be rewritten and passed down (to a delegate makeCursors call) and some of them should be placed on the return cursor for filtering. If you write the test to validate that contract, then it will be a cleaner test that is more helpful in the face of code changes. Fwiw, there are two reasons to have tests
- To give you confidence that the changes you are making work
- To give everybody on the project confidence that their changes work
Goal 2 is infinitely more important than number 1 and is best served by testing to contract and not implementation as much as possible.
There was a problem hiding this comment.
Makes sense, I'm working on the refactoring
| final Project rightP = call.rel(0); | ||
| final SqlKind rightProjectKind = rightP.getChildExps().get(0).getKind(); | ||
| final DruidUnnestRel unnestDatasourceRel = call.rel(1); | ||
|
|
||
| if (rightP.getProjects().size() == 1 && (rightProjectKind == SqlKind.CAST || rightProjectKind == SqlKind.LITERAL)) { | ||
| call.transformTo(unnestDatasourceRel); | ||
| } |
There was a problem hiding this comment.
Should we do the check of whether or not this actually does a rewrite in the matches call instead of the onMatch call?
There was a problem hiding this comment.
Yes, will followup on this, will add the matches code
There was a problem hiding this comment.
Added the matches part along with new examples
| public void testUnnestWithMultipleOrFiltersOnUnnestedColumnsAndOnOriginalColumn() | ||
| { | ||
| skipVectorize(); | ||
| cannotVectorize(); | ||
| testQuery( | ||
| "SELECT d3 FROM druid.numfoo, UNNEST(MV_TO_ARRAY(dim3)) as unnested (d3) where d3='b' or dim3='d' ", | ||
| QUERY_CONTEXT_UNNEST, | ||
| ImmutableList.of( | ||
| Druids.newScanQueryBuilder() | ||
| .dataSource(UnnestDataSource.create( | ||
| new TableDataSource(CalciteTests.DATASOURCE3), | ||
| expressionVirtualColumn("j0.unnest", "\"dim3\"", ColumnType.STRING), | ||
| null | ||
| )) | ||
| .intervals(querySegmentSpec(Filtration.eternity())) | ||
| .resultFormat(ScanQuery.ResultFormat.RESULT_FORMAT_COMPACTED_LIST) | ||
| .filters( | ||
| or( | ||
| selector("j0.unnest", "b", null), | ||
| selector("dim3", "d", null) | ||
| ) | ||
| ) | ||
| .legacy(false) | ||
| .context(QUERY_CONTEXT_UNNEST) | ||
| .columns(ImmutableList.of("j0.unnest")) | ||
| .build() | ||
| ), | ||
| ImmutableList.of( | ||
| new Object[]{"b"}, | ||
| new Object[]{"b"}, | ||
| new Object[]{"d"} | ||
| ) | ||
| ); | ||
| } |
There was a problem hiding this comment.
This test has got me wondering what will happen if you run
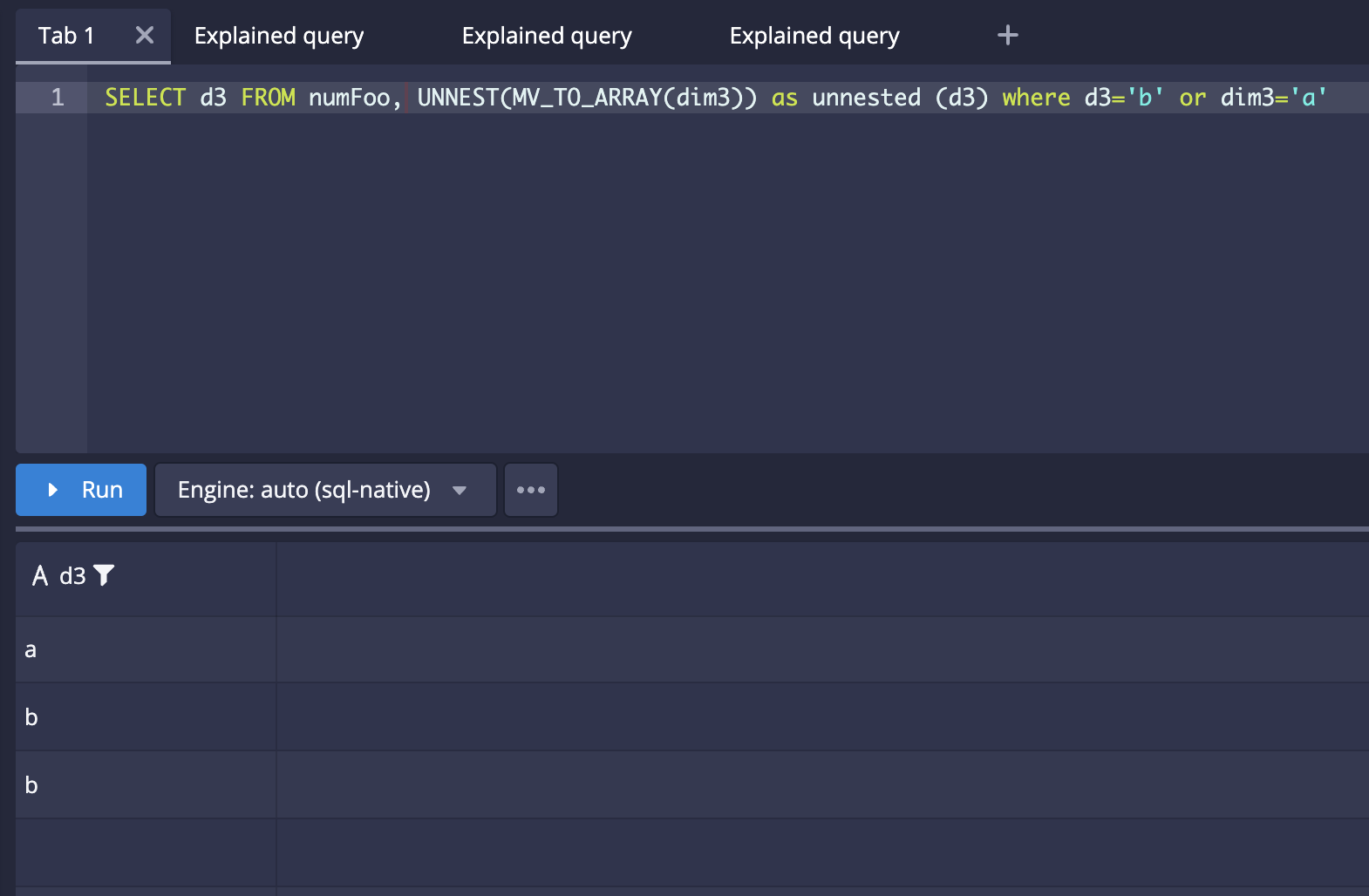
"SELECT d3 FROM druid.numfoo, UNNEST(MV_TO_ARRAY(dim3)) as unnested (d3) where d3='b' or dim3='a' "
Instead. I expect that it should match all of the ["a", "b"] rows and thus be 4 results of a, b, a, b. But I'm curious.
There was a problem hiding this comment.
Should be the rows that are a and b. The table has 3 such rows, so would be 3 results a,b,b.
There was a problem hiding this comment.
Oh, I thought there were 2 rows with ["a", "b"], my bad... Does it work the same if you invert it? If you say dim3='b' OR d3 = 'a'?
Btw, you might as well add these as tests as well. They might not be testing any new corners, but anything that's like "I wonder what happens if" is worth including.
…he base cursor while using unnest with or and regular filters
Addresses the following:
This PR has: