remove unnecessary lock in ForegroundCachePopulator leading to a lot of contention#8116
Conversation
|
Pretty flamegraph, what did you use to capture/generate it? |
This was sampled and the flame graph generated with swiss java knife sample: flame graph: which spits out that html page you can interact with. The flame graph generation can also apparently work with VisualVM and flight recorder output as well, but I haven't tried it (just encountered this tool this week). |
| @@ -36,7 +36,6 @@ public class ForegroundCachePopulator implements CachePopulator | |||
| { | |||
There was a problem hiding this comment.
Please provide concurrent access documentation for this class (or for CachePopulator in general, and make ForegroundCachePopulator's Javadoc just refer to its superclass's Javadoc), and/or describe the concurrent control or data flow.
In particular, this passage from the PR description:
since CachePopulator is shared by all processing threads but the lock covers bytes and json generator that are tied to a specific segment which should only be happening in a single thread.
is not obvious, but it's not reflected anywhere in the code itself.
There was a problem hiding this comment.
I think there isn't so much concurrent access to document anymore since all concurrency primitives have been removed from ForegroundCachePopulator, which I think previously qualified for the excessive thread safety section. I have tried to update the javadocs of CachePopulator to describe it's usage and how the sequence is consumed, so hopefully at least I've left it better than I found it.
| @@ -76,20 +75,18 @@ public <T, CacheType> Sequence<T> wrap( | |||
| sequence, | |||
| input -> { | |||
| if (!tooBig.get()) { | |||
There was a problem hiding this comment.
Please justify the use of AtomicBoolean in a comment, or use a MutableBoolean if concurrency is not required.
There was a problem hiding this comment.
Oops good catch, yeah this is probably not required, will change 👍
| |`druid.historical.cache.useCache`|true, false|Enable the cache on the Historical.|false| | ||
| |`druid.historical.cache.populateCache`|true, false|Populate the cache on the Historical.|false| | ||
| |`druid.historical.cache.unCacheable`|All druid query types|All query types to not cache.|["groupBy", "select"]| | ||
| |`druid.historical.cache.numBackgroundThreads`|If greater than 0, cache will be populated in the background thread pool of the configured size|0| |
There was a problem hiding this comment.
I thought there was some reason that background cache population wasn't documented. IIRC it was broken somehow (something about generating corrupt / incorrect cached data). But unfortunately I can't remember what was wrong or if it has been fixed yet.
If it turns out that the feature does work now, I believe it still does have one serious flaw — no load shedding means it can lead to your JVM running OOM.
IMO, if we think the feature is still broken (in the sense that it corrupts caches), let's not document it.
If we think the feature works but has this potential OOM issue, then I think it's OK to document it, but the docs should call out the potential for OOMs due to lack of load shedding.
There was a problem hiding this comment.
I did a bit of searching and came across some stuff, but nothing conclusive. This comment, in an issue about missing documentation, indicates what you are suggesting. But there also exists #3943 which purports to fix thread safety issues with the background cache and is more recent than the discussion in that issue. Issue #4199, which I found linked to #3943 and indicates that the problem wasn't visible with cache disabled, but ultimately seemed related to aggregator thread safety since it was marked resolved by #4304, so whether or not this is broken might tie into that? (So #3956, #4304, #5148 (comment), proposal #8031, and many other related discussions.)
Maybe if we document the setting as experimental and mention the potential for oom it would be ok to document? That would be my preference over leaving it undocumented unless it is truly broken always, but I haven't been able to fully determine that yet.
There was a problem hiding this comment.
Due to the controversy about how to word the doc for background cache population, I'd suggest breaking that out into its own PR and leaving this one to only include the lock-removal fix for foreground cache population. These two things are only tangentially related. In the other PR, we could discuss:
- Whether or not we are going to document background caching at this time (given the above thread).
- What exactly the docs should say.
| * background. Used if config "druid.*.cache.numBackgroundThreads" is greater than 0. If maximum cache entry size, | ||
| * specified by config "druid.*.cache.maxEntrySize", is exceeded, this {@link CachePopulator} implementation will | ||
| * be a bit less efficient than {@link ForegroundCachePopulator} which can stop retaining values early, in exchange | ||
| * for interacting with the {@link Cache} in a background thread. |
There was a problem hiding this comment.
I'd include a warning, too, about the lack of load shedding.
| * {@link CachePopulator} implementation that populates a cache on the same thread that is processing the | ||
| * {@link Sequence}. Used if config "druid.*.cache.numBackgroundThreads" is 0 (the default). This {@link CachePopulator} | ||
| * should be more efficient than {@link BackgroundCachePopulator} if maximum cache entry size, specified by config | ||
| * "druid.*.cache.maxEntrySize", is exceeded. |
There was a problem hiding this comment.
I'd add that typically, the thread processing this sequence (and hence populating the cache) is either:
- a processing thread (if historical/task)
- an http thread (if broker)
| sequence, | ||
| input -> { | ||
| if (!tooBig.get()) { | ||
| synchronized (lock) { |
There was a problem hiding this comment.
This lock removal is the core change happening, and it looks good to me. The lock seems to have been pointless, since the only thing worth protecting is the ByteArrayOutputStream, and that's only being accessed by a single thread (the thread that walks the Sequence).
| |`druid.realtime.cache.useCache`|true, false|Enable the cache on the realtime.|false| | ||
| |`druid.realtime.cache.populateCache`|true, false|Populate the cache on the realtime.|false| | ||
| |`druid.realtime.cache.unCacheable`|All druid query types|All query types to not cache.|`["groupBy", "select"]`| | ||
| |`druid.realtime.cache.numBackgroundThreads`|If greater than 0, cache will be populated in the background thread pool of the configured size. By default cache is populated in the foreground, which can more efficiently handle reaching `maxEntrySize` than when done in the background. Note that there is no load shedding for background cache population, so it can also lead to out of memory scenarios depending on background threadpool utilization.|0| |
There was a problem hiding this comment.
What does it mean for cache "to be populated in the background" and "to be populated in the foreground"? Could you please add a new doc page explaining these concepts and refer to it from all these configuration parameter descriptions?
There was a problem hiding this comment.
It doesn't seem to me that maxEntrySize has any relation to background/foreground. It's a size of one entry, how can the verb "reach" be applied to it?
There was a problem hiding this comment.
"Note that there is no load shedding for background cache population, so it can also lead to out of memory scenarios depending on background threadpool utilization." - I didn't understand this. Please reword.
There was a problem hiding this comment.
What does it mean for cache "to be populated in the background" and "to be populated in the foreground"? Could you please add a new doc page explaining these concepts and refer to it from all these configuration parameter descriptions?
IMO it's better to try to use the space here in this page to explain the concepts that a user needs to understand. It doesn't seem complicated enough that a new page is needed.
It doesn't seem to me that maxEntrySize has any relation to background/foreground. It's a size of one entry, how can the verb "reach" be applied to it?
Each cache entry can be potentially built from multiple objects, and can potentially be built up incrementally. Imagine a cache entry that is derived from a Sequence<Row> of 100 rows, and maxEntrySize is "reached" after the first 40 rows.
Please reword.
Here is my attempt:
If equal to zero, query cache is populated synchronously using the same thread that generated the cacheable data in the first place. This will generally be the query processing pool on data processes (like Historicals) or the HTTP server thread pool on Brokers. If greater than 0, query cache will be populated asynchronously using a thread pool of this size. The thread pool will be dedicated to query cache population, and will not be used for any other purpose. Note that if cacheable data is generated faster than it can be written to the cache, background population can lead the JVM to run out of memory.
I removed the bit about maxEntrySize since I think it's too inside-baseball (it's referring to the foreground populator being able to 'notice' an oversized entry earlier, which is somewhat more efficient, but it doesn't seem worth mentioning in user-facing docs).
By the way, as mentioned in #8116 (comment), it might be a good idea to split the doc changes off into their own PR. They're only tangentially related to the patch's original purpose.
There was a problem hiding this comment.
Oh man, glad this little PR could spawn such good discussion, thanks for weighing in on this @gianm 👍
By the way, as mentioned in #8116 (comment), it might be a good idea to split the doc changes off into their own PR. They're only tangentially related to the patch's original purpose.
I will retain the documentation i've added for maxEntrySize since it's pretty straightforward, but drop the foreground/background stuff in favor of doing that however #8125 is resolved.
There was a problem hiding this comment.
IMO it's better to try to use the space here in this page to explain the concepts that a user needs to understand. It doesn't seem complicated enough that a new page is needed.
The problem is that these docs are repeated at multiple places. I support moving doc updates into a separate PR, though.
There was a problem hiding this comment.
There is also already this caching doc page which might be appropriate for such future docs?
There was a problem hiding this comment.
I think there's a lot of value in having a single page with all config options; could make sense to play with moving these to their own header within configuration/index.md and then having the original sections linking into them.
There was a problem hiding this comment.
Ah, totally agree it should be on config page no matter what; config page should be exhaustive 👍
| |`druid.realtime.cache.populateCache`|true, false|Populate the cache on the realtime.|false| | ||
| |`druid.realtime.cache.unCacheable`|All druid query types|All query types to not cache.|`["groupBy", "select"]`| | ||
| |`druid.realtime.cache.numBackgroundThreads`|If greater than 0, cache will be populated in the background thread pool of the configured size. By default cache is populated in the foreground, which can more efficiently handle reaching `maxEntrySize` than when done in the background. Note that there is no load shedding for background cache population, so it can also lead to out of memory scenarios depending on background threadpool utilization.|0| | ||
| |`druid.realtime.cache.maxEntrySize`|Maximum cache entry size in bytes.|1_000_000| |
There was a problem hiding this comment.
This description (or the more general description on the common page) should explain what happens if the serialized form of a query result is bigger than this size. I suppose it is "the result is not recorded in the cache; XXX/put/oversized metric is incremented" (I don't know what should go into XXX, this question should be researched.)
There was a problem hiding this comment.
What happens is "the result is not recorded in the cache; cache */put/oversized metrics are incremented."
The */put/oversized syntax would match how they are described in metrics.md, so I think that'd be the right way to write it in user-facing docs. The * could be query/cache/delta or query/cache/total, also mentioned in metrics.md.
| * {@link CachePopulator} implementation that uses a {@link ExecutorService} thread pool to populate a cache in the | ||
| * background. Used if config "druid.*.cache.numBackgroundThreads" is greater than 0. If maximum cache entry size, | ||
| * specified by config "druid.*.cache.maxEntrySize", is exceeded, this {@link CachePopulator} implementation will | ||
| * be a bit less efficient than {@link ForegroundCachePopulator} which can stop retaining values early, in exchange |
There was a problem hiding this comment.
I don't understand the relation with maxEntrySize, again, and what does "can stop retaining values early" mean. Please reword.
There was a problem hiding this comment.
This comment has some details - #8116 (comment)
I do think it's too inside-baseball for user-facing docs, and maybe even for javadocs. It's referring to the fact that the foreground populator avoids some work, relative to the background populator, in the case that maxEntrySize is exceeded. In particular, when building a cache entry from a Sequence<T>, the background populator will run cacheFn on all T first, and then when they're all done it will start serializing them one by one. At that point, if maxEntrySize is exceeded, it will throw the rest away and exit early without populating the cache. But it still went through the effort of computing cacheFn on the Ts that it threw away. The foreground populator, on the other hand, does not do that.
|
This PR inspired me to create this issue: #8125. |
|
I have not had a chance to setup benchmarks for cache population to compare the before and after, but sampling a query locally with the same tool the original report was collected with does produce a nicer looking results with regards to the I only had the example wiki data handy, so test was done with the same query repeated 3 times over a 5 second window with before: after: I do think that having benchmarks in place for cache population sounds useful, so hopefully I can carve out some time to add those in a future PR or something. |
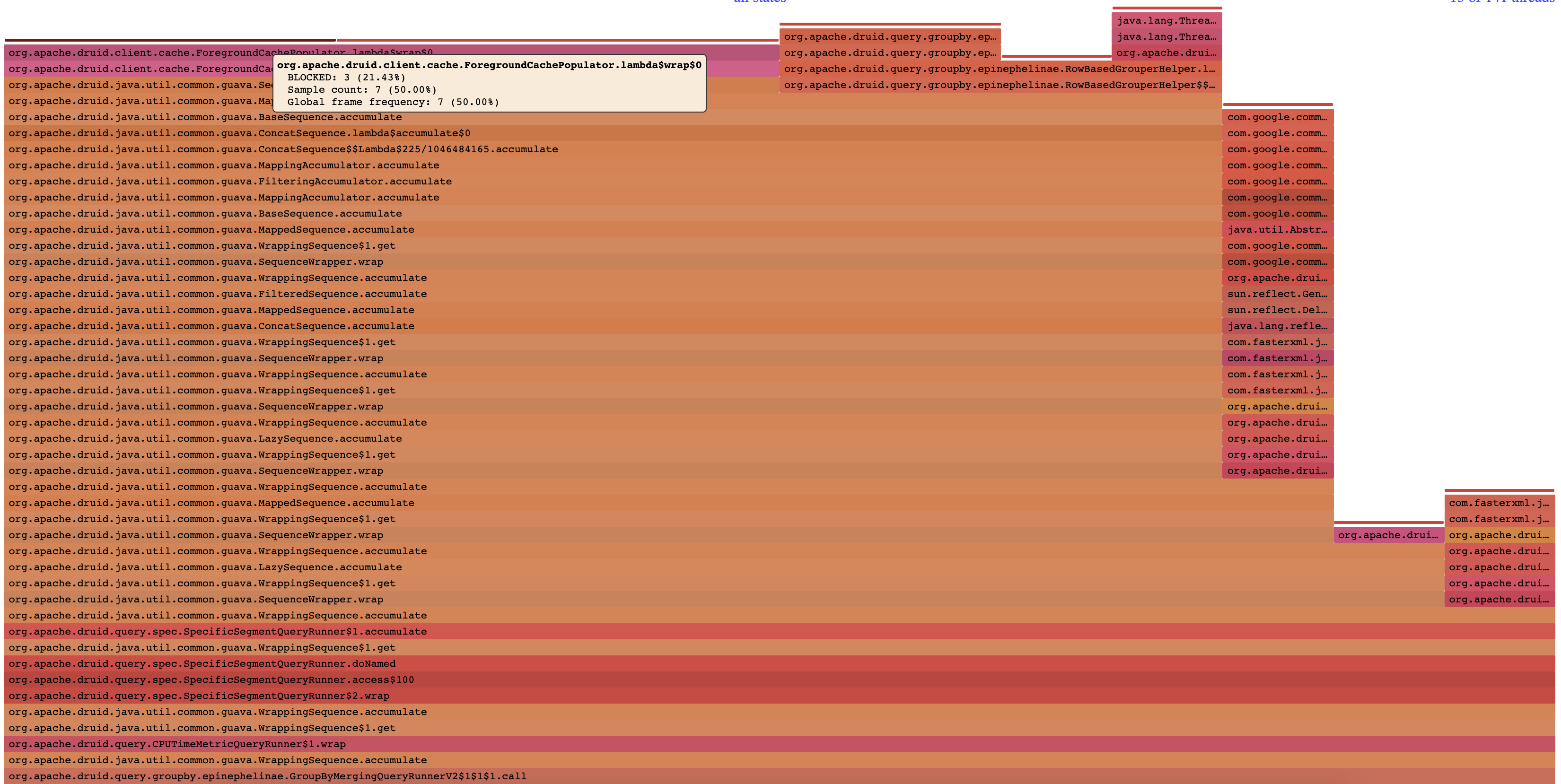
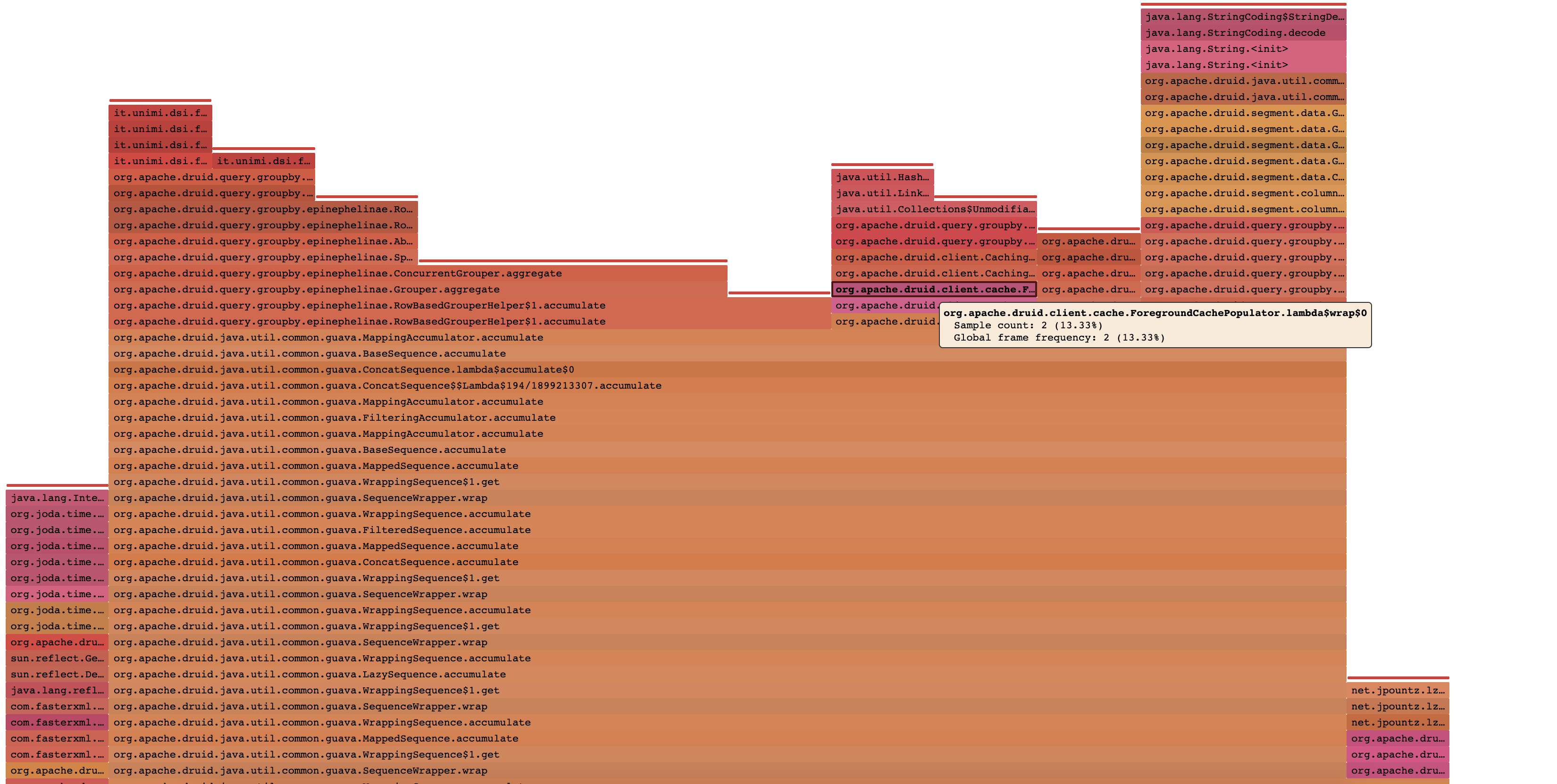
|
Thanks for review all! |
…of contention (apache#8116) * remove unecessary lock in ForegroundCachePopulator leading to a lot of contention * mutableboolean, javadocs,document some cache configs that were missing * more doc stuff * adjustments * remove background documentation
Description
This PR adds a performance improvement to
ForegroundTaskRunner, removing a synchronized block that appears to be unnecessary, sinceCachePopulatoris shared by all processing threads but the lock covers bytes and json generator that are tied to a specific segment which should only be happening in a single thread.Observed a lot of time being spent in
ForegroundCachePopulator, displayed in the following flame graph:I don't have direct access to the cluster where these observations were made, so I don't have measurements for the fix, I will see if I can get some equivalent measurements done locally and update this ticket.
This PR has: