[SUPPORT] Schema evolution fails due to NPE with hoodie.schema.on.read.enable turned on #7283
Description
Tips before filing an issue
-
Have you gone through our FAQs?
-
Join the mailing list to engage in conversations and get faster support at dev-subscribe@hudi.apache.org.
-
If you have triaged this as a bug, then file an issue directly.
Describe the problem you faced
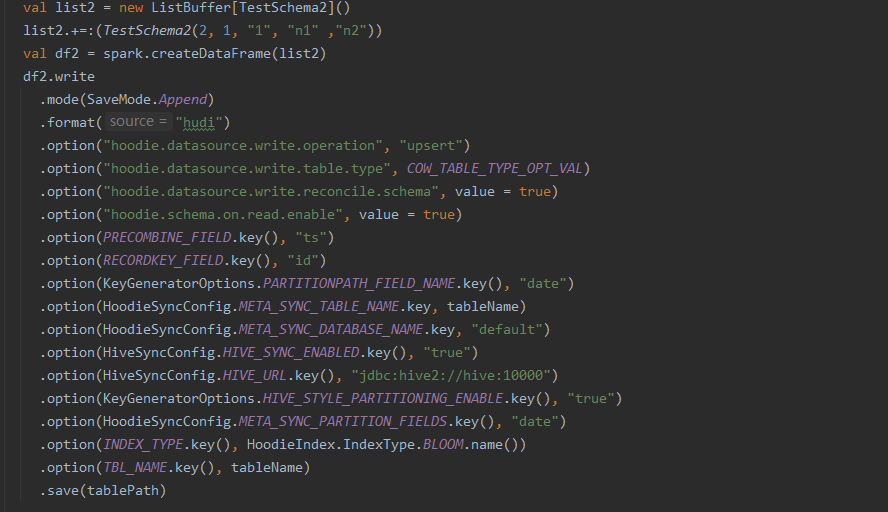
first, If I use spark ddl to change the field data type or other ddl, and then I use spark df to add a new filed, then will throw a NullPointerException
Environment Description
-
Hudi version :0.11.1
-
Spark version :3.2.2
-
Hive version :3.1.3
-
Hadoop version :3.3.2
-
Storage (HDFS/S3/GCS..) :hdfs
Additional context




Stacktrace
14608 [Executor task launch worker for task 0.0 in stage 25.0 (TID 32)] ERROR org.apache.spark.executor.Executor - Exception in task 0.0 in stage 25.0 (TID 32)
org.apache.hudi.exception.HoodieUpsertException: Error upserting bucketType UPDATE for partition :0
at org.apache.hudi.table.action.commit.BaseSparkCommitActionExecutor.handleUpsertPartition(BaseSparkCommitActionExecutor.java:329)
at org.apache.hudi.table.action.commit.BaseSparkCommitActionExecutor.lambda$mapPartitionsAsRDD$a3ab3c4$1(BaseSparkCommitActionExecutor.java:244)
at org.apache.spark.api.java.JavaRDDLike.$anonfun$mapPartitionsWithIndex$1(JavaRDDLike.scala:102)
at org.apache.spark.api.java.JavaRDDLike.$anonfun$mapPartitionsWithIndex$1$adapted(JavaRDDLike.scala:102)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsWithIndex$2(RDD.scala:915)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsWithIndex$2$adapted(RDD.scala:915)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.$anonfun$getOrCompute$1(RDD.scala:386)
at org.apache.spark.storage.BlockManager.$anonfun$doPutIterator$1(BlockManager.scala:1498)
at org.apache.spark.storage.BlockManager.org$apache$spark$storage$BlockManager$$doPut(BlockManager.scala:1408)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1472)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:1295)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:384)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:335)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:131)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:506)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1462)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:509)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)
Caused by: java.lang.NullPointerException
at org.apache.hudi.internal.schema.visitor.NameToIDVisitor.beforeField(NameToIDVisitor.java:42)
at org.apache.hudi.internal.schema.InternalSchemaBuilder.visit(InternalSchemaBuilder.java:87)
at org.apache.hudi.internal.schema.InternalSchemaBuilder.buildNameToId(InternalSchemaBuilder.java:68)
at org.apache.hudi.internal.schema.InternalSchemaBuilder.buildIdToName(InternalSchemaBuilder.java:56)
at org.apache.hudi.internal.schema.InternalSchema.(InternalSchema.java:72)
at org.apache.hudi.internal.schema.InternalSchema.(InternalSchema.java:62)
at org.apache.hudi.internal.schema.utils.AvroSchemaEvolutionUtils.evolveSchemaFromNewAvroSchema(AvroSchemaEvolutionUtils.java:95)
at org.apache.hudi.table.action.commit.HoodieMergeHelper.runMerge(HoodieMergeHelper.java:103)
at org.apache.hudi.table.action.commit.BaseSparkCommitActionExecutor.handleUpdateInternal(BaseSparkCommitActionExecutor.java:358)
at org.apache.hudi.table.action.commit.BaseSparkCommitActionExecutor.handleUpdate(BaseSparkCommitActionExecutor.java:349)
at org.apache.hudi.table.action.commit.BaseSparkCommitActionExecutor.handleUpsertPartition(BaseSparkCommitActionExecutor.java:322)
... 28 more
14608 [Executor task launch worker for task 1.0 in stage 25.0 (TID 33)] ERROR org.apache.spark.executor.Executor - Exception in task 1.0 in stage 25.0 (TID 33)
org.apache.hudi.exception.HoodieUpsertException: Error upserting bucketType UPDATE for partition :1
at org.apache.hudi.table.action.commit.BaseSparkCommitActionExecutor.handleUpsertPartition(BaseSparkCommitActionExecutor.java:329)
at org.apache.hudi.table.action.commit.BaseSparkCommitActionExecutor.lambda$mapPartitionsAsRDD$a3ab3c4$1(BaseSparkCommitActionExecutor.java:244)
at org.apache.spark.api.java.JavaRDDLike.$anonfun$mapPartitionsWithIndex$1(JavaRDDLike.scala:102)
at org.apache.spark.api.java.JavaRDDLike.$anonfun$mapPartitionsWithIndex$1$adapted(JavaRDDLike.scala:102)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsWithIndex$2(RDD.scala:915)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsWithIndex$2$adapted(RDD.scala:915)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.$anonfun$getOrCompute$1(RDD.scala:386)
at org.apache.spark.storage.BlockManager.$anonfun$doPutIterator$1(BlockManager.scala:1498)
at org.apache.spark.storage.BlockManager.org$apache$spark$storage$BlockManager$$doPut(BlockManager.scala:1408)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1472)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:1295)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:384)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:335)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:131)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:506)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1462)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:509)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)
Caused by: java.lang.NullPointerException
at org.apache.hudi.internal.schema.visitor.NameToIDVisitor.beforeField(NameToIDVisitor.java:42)
at org.apache.hudi.internal.schema.InternalSchemaBuilder.visit(InternalSchemaBuilder.java:87)
at org.apache.hudi.internal.schema.InternalSchemaBuilder.buildNameToId(InternalSchemaBuilder.java:68)
at org.apache.hudi.internal.schema.InternalSchemaBuilder.buildIdToName(InternalSchemaBuilder.java:56)
at org.apache.hudi.internal.schema.InternalSchema.(InternalSchema.java:72)
at org.apache.hudi.internal.schema.InternalSchema.(InternalSchema.java:62)
at org.apache.hudi.internal.schema.utils.AvroSchemaEvolutionUtils.evolveSchemaFromNewAvroSchema(AvroSchemaEvolutionUtils.java:95)
at org.apache.hudi.table.action.commit.HoodieMergeHelper.runMerge(HoodieMergeHelper.java:103)
at org.apache.hudi.table.action.commit.BaseSparkCommitActionExecutor.handleUpdateInternal(BaseSparkCommitActionExecutor.java:358)
at org.apache.hudi.table.action.commit.BaseSparkCommitActionExecutor.handleUpdate(BaseSparkCommitActionExecutor.java:349)
at org.apache.hudi.table.action.commit.BaseSparkCommitActionExecutor.handleUpsertPartition(BaseSparkCommitActionExecutor.java:322)
... 28 more
Metadata
Metadata
Assignees
Type
Projects
Status