KAFKA-13629: Use faster algorithm for ByteUtils sizeOfXxx algorithm#11721
KAFKA-13629: Use faster algorithm for ByteUtils sizeOfXxx algorithm#11721ijuma merged 9 commits intoapache:trunkfrom
Conversation
|
Thanks for the PR. Can you please share the results for the micro-benchmark as well as any improvement you observed in real workloads? |
|
Overall, this results in ~6% reduction in CPU cycles in the Before flamegraph (see highlighted section) - starting from Before flamegraph (see highlighted) - zoomed in to the After flamegraph (highlight turned on, but not showing up in any samples) For the provided JMH microbenchmark, the new approach is ~3.4x better. |
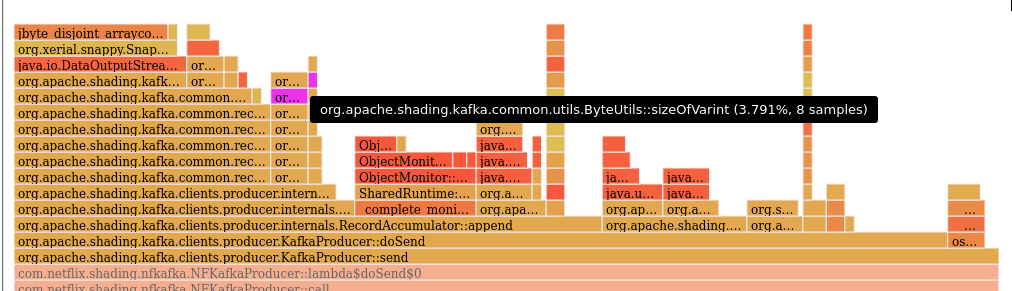
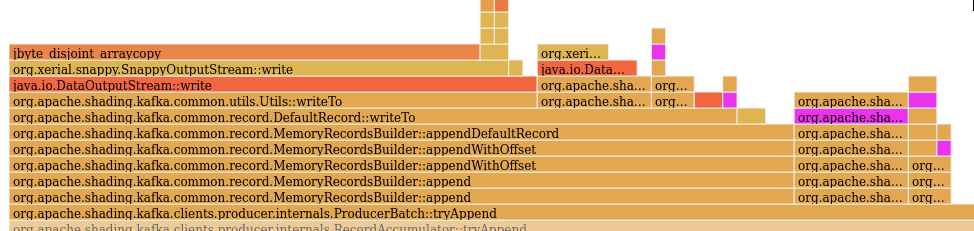
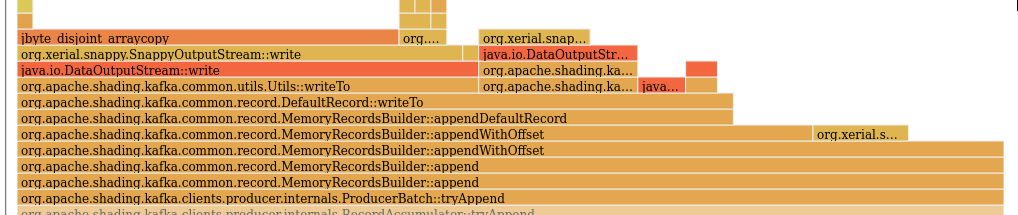
| } | ||
| return bytes; | ||
| int leadingZeros = Integer.numberOfLeadingZeros(value); | ||
| return LEADING_ZEROS_TO_U_VARINT_SIZE[leadingZeros]; |
There was a problem hiding this comment.
I wonder if doing
return (38 - leadingZeros) / 7 + leadingZeros / 32;
would be faster than the lookup.
There was a problem hiding this comment.
- updated with a bit of extra investigation
Good suggestion, I added a benchmark in 87d4b19. Although, it looks like the div, even when compiled down to shift operations, is not as quick.
Digging a little further I discovered that the length of the bitshift asm result in less loop unroll, so, I created a separate test that tests only a single element in bc1afab. Here the benefit does not seem as great but then when I investigate perfasm result the lookup based approach spends most of its time in the blackhole and only a fraction in lzcnt/cmp/mov.
The results are here:
Benchmark Mode Cnt Score Error Units
ByteUtilsBenchmark.testSizeOfUnsignedVarintMathOne thrpt 10 424743.573 ± 3404.300 ops/ms
ByteUtilsBenchmark.testSizeOfUnsignedVarintOne thrpt 10 602155.871 ± 3100.966 ops/ms
ByteUtilsBenchmark.testSizeOfUnsignedVarintOriginalOne thrpt 10 451803.982 ± 647.814 ops/ms
Looking at -prof perfasm, the math edition does use lzcnt and does compile down to bitshifts, they just turn out relatively expensive. (This is on a 5950X).
The key to note is that the math-based one requires an lzcnt followed by some integer math and bitshifts, whilst the lookup requires an lzcnt and only a cmp/mov.
There was a problem hiding this comment.
Interesting. It's unfortunate that the second operation is a div in Java (I'm new to Java, so maybe there is a way to express it differently, but I couldn't think of one), in C++ I would've just done:
return (38 - leadingZeros) / 7 + (leadingZeros == 32);
which would just do cmp and add carryover bit, which is cheaper than div. Maybe the compiler would be smart enough to translate ((leadingZeros == 32) ? 1 : 0) into math expression rather than do a branch?
In these benchmarks, the lookup table is likely cached in L1 cache (hot loop that hits the same small amount of data), so memory access in the benchmark is likely cheaper than on average. It's probably hard to do a proper model and I'm not sure if it's worth it.
In any case, thanks for doing this comprehensive research, good stuff!
There was a problem hiding this comment.
Yes, I agree - the arithmetic / bitshift looks intuitively quicker since it requires no loads. Looking at the compiler output from JDK11, it does get compiled down to a sequence of operations that are reasonably clean (no DIV), just that there are a lot of instructions. Perhaps there is a slight advantage in different use-cases, but, in my case this fix takes the function completely out of the profiler results so it solves the problem.
Out of interest sake, here is the sequence of operations according to perfasm on JDK11.
││ 0x00007f26e04797b7: mov 0x10(%r12,%r10,8),%r10d
0.05% ││ 0x00007f26e04797bc: lzcnt %r10d,%r11d ;*invokestatic numberOfLeadingZeros {reexecute=0 rethrow=0 return_oop=0}
││ ; - org.apache.kafka.jmh.util.ByteUtilsBenchmark::testSizeOfUnsignedVarintMathOne@6 (line 76)
││ ; - org.apache.kafka.jmh.util.jmh_generated.ByteUtilsBenchmark_testSizeOfUnsignedVarintMathOne_jmhTest::testSizeOfUnsignedVarintMathOne_thrpt_jmhStub@17 (line 119)
0.03% ││ 0x00007f26e04797c1: mov $0x26,%r8d
0.01% ││ 0x00007f26e04797c7: sub %r11d,%r8d ;*isub {reexecute=0 rethrow=0 return_oop=0}
││ ; - org.apache.kafka.jmh.util.ByteUtilsBenchmark::testSizeOfUnsignedVarintMathOne@13 (line 77)
││ ; - org.apache.kafka.jmh.util.jmh_generated.ByteUtilsBenchmark_testSizeOfUnsignedVarintMathOne_jmhTest::testSizeOfUnsignedVarintMathOne_thrpt_jmhStub@17 (line 119)
0.49% ││ 0x00007f26e04797ca: mov %r11d,%r9d
0.36% ││ 0x00007f26e04797cd: sar $0x1f,%r9d
0.02% ││ 0x00007f26e04797d1: movsxd %r8d,%r10
0.77% ││ 0x00007f26e04797d4: shr $0x1b,%r9d
7.24% ││ 0x00007f26e04797d8: add %r11d,%r9d
0.78% ││ 0x00007f26e04797db: imulq $0x92492493,%r10,%r10
0.05% ││ 0x00007f26e04797e2: sar $0x5,%r9d
2.24% ││ 0x00007f26e04797e6: sar $0x20,%r10
9.93% ││ 0x00007f26e04797ea: movsxd %r9d,%r11
0.12% ││ 0x00007f26e04797ed: mov %r10d,%r10d
││ 0x00007f26e04797f0: add %r8d,%r10d
6.30% ││ 0x00007f26e04797f3: sar $0x1f,%r8d
2.53% ││ 0x00007f26e04797f7: sar $0x2,%r10d
6.21% ││ 0x00007f26e04797fb: movsxd %r8d,%r8
││ 0x00007f26e04797fe: movsxd %r10d,%rdx
7.25% ││ 0x00007f26e0479801: sub %r8,%rdx
7.01% ││ 0x00007f26e0479804: add %r11,%rdx ;*i2l {reexecute=0 rethrow=0 return_oop=0}
││ ; - org.apache.kafka.jmh.util.ByteUtilsBenchmark::testSizeOfUnsignedVarintMathOne@22 (line 77)
││ ; - org.apache.kafka.jmh.util.jmh_generated.ByteUtilsBenchmark_testSizeOfUnsignedVarintMathOne_jmhTest::testSizeOfUnsignedVarintMathOne_thrpt_jmhStub@17 (line 119)
8.11% ││ 0x00007f26e0479807: mov (%rsp),%rsi
Lookup table:
│ 0x00007fde904792a7: mov 0x10(%r12,%r10,8),%r10d
1.42% │ 0x00007fde904792ac: lzcnt %r10d,%r10d ;*invokestatic numberOfLeadingZeros {reexecute=0 rethrow=0 return_oop=0}
│ ; - org.apache.kafka.common.utils.ByteUtils::sizeOfUnsignedVarint@1 (line 420)
│ ; - org.apache.kafka.jmh.util.ByteUtilsBenchmark::testSizeOfUnsignedVarintOne@6 (line 61)
│ ; - org.apache.kafka.jmh.util.jmh_generated.ByteUtilsBenchmark_testSizeOfUnsignedVarintOne_jmhTest::testSizeOfUnsignedVarintOne_thrpt_jmhStub@17 (line 119)
1.26% │ 0x00007fde904792b1: cmp $0x21,%r10d
2.65% │ 0x00007fde904792b5: jnb 0x7fde90479332
0.02% │ 0x00007fde904792b7: mov %r8,0x40(%rsp)
0.02% │ 0x00007fde904792bc: movabs $0xfe434bf0,%r11 ; {oop([I{0x00000000fe434bf0})}
1.68% │ 0x00007fde904792c6: movsxd 0x10(%r11,%r10,4),%rdx ;*i2l {reexecute=0 rethrow=0 return_oop=0}
│ ; - org.apache.kafka.jmh.util.ByteUtilsBenchmark::testSizeOfUnsignedVarintOne@9 (line 61)
│ ; - org.apache.kafka.jmh.util.jmh_generated.ByteUtilsBenchmark_testSizeOfUnsignedVarintOne_jmhTest::testSizeOfUnsignedVarintOne_thrpt_jmhStub@17 (line 119)
37.64% │ 0x00007fde904792cb: mov (%rsp),%rsi
It may be that the code in yours is faster when dropped into a full application. On the other hand, a single load dependency is something that can be easily predicted and pipelined...
Perhaps there are a more direct series of shift operations that would be better suited?
There was a problem hiding this comment.
That does seem like a lot of instructions, some of them don't seem to be needed in this case where we deal with small unsigned integers (e.g. movsxd %r8d,%r8 is extending the sign to 64 bits, but we don't need it). Java doesn't seem to support unsigned, so not sure if there is a way to hint the compiler that we don't need instructions that only matter for signed arithmetic. Maybe using long would help at least to eliminate the need to do movsxd.
There was a problem hiding this comment.
@artemlivshits i've updated the implementation in f040109.
There was a problem hiding this comment.
Sorry to chime in late here, but I'm wondering if a lookup table may still be faster. You can see these two instructions in your lookup table implementation above,
1.26% │ 0x00007fde904792b1: cmp $0x21,%r10d
2.65% │ 0x00007fde904792b5: jnb 0x7fde90479332
this is comparing if the calculated number (leading zeroes) fits within the size-33 array. Does Java have the concept of a 256 sized array, and uint8 numbers?
In my Go implementation (which uses bits.Len, i.e., the opposite of leading zeroes, here: https://github.com/twmb/franz-go/blob/0a23cca3f4ee9d69b6cb2e70aab1c8e012b901ad/pkg/kbin/primitives.go#L76-L87), using a size-256 string and a uint8 allows for no bounds check, resulting in even fewer instructions and shaving a fraction of a nanosecond of time in comparison to the pure math version.
In this benchmark,
func BenchmarkUvarintLen(b *testing.B) {
z := 0
for i := 0; i < b.N; i++ {
z += UvarintLen(uint32(i))
}
b.Log(z)
}Comparing the existing code to this code:
func UvarintLen(u uint32) int {
lz := bits.LeadingZeros32(u)
return (((38 - lz) * 0b10010010010010011) >> 19) + (lz >> 5)}Top is math version, bottom is lookup table:
BenchmarkUvarintLen-8 1000000000 1.179 ns/op
BenchmarkUvarintLen-8 1000000000 0.7811 ns/op
There was a problem hiding this comment.
I like your approach here, and it's something that should be possible, but, I don't see it being applied, the below still includes the cmp/jump
final static byte[] LEADING_ZEROS_TO_U_VARINT_SIZE = new byte[4096];
Byte is -127 to +128 in Java, so 4096 should be plenty.
byte leadingZeros = (byte) Integer.numberOfLeadingZeros(inputInt);
return LEADING_ZEROS_TO_U_VARINT_SIZE[leadingZeros];
There was a problem hiding this comment.
Ah bummer, but interesting! Fun between languages :)
|
Thanks for the detailed analysis! Note that JMH 1.34 (https://mail.openjdk.java.net/pipermail/jmh-dev/2021-December/003406.html) has support for much cheaper blackholes if executed with Java 17 or later. On that note, which Java version are you using in your experiments? |
|
Good spot on jmh 1.34, TIL! Here's a result from a re-run With
|
 ijuma
left a comment
ijuma
left a comment
There was a problem hiding this comment.
Thanks for the PR, this looks good to me overall. I left a few minor comments that we should address before merging.
| // return (38 - leadingZeros) / 7 + leadingZeros / 32; | ||
| int leadingZerosBelow38DividedBy7 = ((38 - leadingZeros) * 0b10010010010010011) >>> 19; | ||
| return leadingZerosBelow38DividedBy7 + (leadingZeros >>> 5); | ||
| } |
There was a problem hiding this comment.
Why do we need this here since it matches the default implementation?
|
|
||
| @Test | ||
| public void testSizeOfUnsignedVarintMath() { | ||
| for (int i = 0; i < Integer.MAX_VALUE; i++) { |
There was a problem hiding this comment.
Is this too slow for a unit test? Similar question for other tests that do a large range of values.
There was a problem hiding this comment.
The tests I have now run in ~0.6 seconds.
| /** | ||
| * The old well-known implementation for sizeOfUnsignedVarint | ||
| */ | ||
| private static int oldSizeOfUnsignedVarint(int value) { |
There was a problem hiding this comment.
Maybe we can call this simpleSizeOfUnsignedVarint or something like that?
There was a problem hiding this comment.
I nested these inside the test case, which I think is cleaner.
| @Fork(3) | ||
| @Warmup(iterations = 5, time = 1) | ||
| @Measurement(iterations = 10, time = 1) | ||
| public int testSizeOfUnsignedVarintOriginal() { |
There was a problem hiding this comment.
Maybe we can say Simple instead of Original (or whatever name we agree for the test, we should use it here too for consistency).
ijuma
left a comment
There was a problem hiding this comment.
Thanks for the updates, looks like spotBugs is not happy. While fixing that, maybe you can also tackle the two minor nits below. We can hopefully merge after that.
|
|
||
| // Similar logic is applied to allow for 64bit input -> 1-9byte output. | ||
|
|
||
| // return (70 - leadingZeros) / 7 + leadingZeros / 64; |
There was a problem hiding this comment.
Nit: not sure we need the empty lines between comments here, seems pretty readable without them.
| @Benchmark | ||
| @Fork(3) | ||
| @Warmup(iterations = 5, time = 1) | ||
| @Measurement(iterations = 10, time = 1) |
There was a problem hiding this comment.
Should we have these at class level since they're the same for every benchmark?
|
I've addressed comments, I'll wait and see what spotbugs says this time. Locally, it's all clear, on CI it shows up issues with code not related to this PR. |
|
I had misread spotbugs output and used the CI spotbugs steps, fixed it now =) |
|
I updated the PR description to include the JMH results I got with JDK 17.0.2 and compiler blackhole mode. |
|
@jasonk000 , thanks for the good improvement! I learned a lot from the PR! Also updated the JIRA status. Thank you. |
Replace loop with a branch-free implementation.
Include:
JMH results with JDK 17.0.2 and
compilerblackhole mode are 2.8-3.4 faster withthe new implementation. In a real application, a 6% reduction in CPU cycles was
observed in the
send()path via flamegraphs.Committer Checklist (excluded from commit message)