KAFKA-9628 Replace Produce request/response with automated protocol#9401
KAFKA-9628 Replace Produce request/response with automated protocol#9401hachikuji merged 15 commits intoapache:trunkfrom
Conversation
|
@hachikuji Could you please take a look? |
 hachikuji
left a comment
hachikuji
left a comment
There was a problem hiding this comment.
Thanks for the patch. Left a few small comments.
|
@chia7712 One thing that would be useful is running the producer-performance test, just to make sure the the performance is inline. Might be worth checking flame graphs as well. |
2191f02 to
0ef9fdf
Compare
The cost of conversion is tiny in whole IO path. It seems to me JMH is more suitable for this patch. There are two new JMH for request and response. It benchmark the construction, toStruct and hot method. The result is attached to "description". @hachikuji Please take a look, thanks! |
643fc46 to
2bdede5
Compare
|
@chia7712 @hachikuji for the ProduceResponse handling, is this the overall broker side regression since you need both the construction and toStruct? Could you please also provide an analysis of the garbage generation using |
2bdede5 to
018acc9
Compare
|
@lbradstreet Thanks for your response.
you are right and it seems to me the solution to fix regression is that server should use automatic protocol response rather than wrapped response. However, it may make a big patch so it would be better to address in another PR. (BTW, fetch protocol has similar issue https://github.com/apache/kafka/blob/trunk/clients/src/main/java/org/apache/kafka/common/requests/FetchResponse.java#L281)
construction regression:
toStruct improvement:
We can reduce the regression (in construction) by replacing steam APIs by for-loop. However, I prefer stream Apis since it is more readable and the true solution is to use auto-generated protocols on server-side. |
hachikuji
left a comment
There was a problem hiding this comment.
This is looking pretty good. Left a few more comments.
There was a problem hiding this comment.
Not required, but this would be easier to follow up if we had some helpers.
There was a problem hiding this comment.
Pardon me. why it is not required?
There was a problem hiding this comment.
Oh, I was just emphasizing that it is a matter of taste. It's up to you if you agree or not.
018acc9 to
dc53d0b
Compare
|
Can we summarize the regression here for a real world workload? |
322e57e to
cdac803
Compare
@ijuma I have attached benchmark result to description. I will loop more benchmark later. |
|
For what it's worth, I think we'll get back whatever we lose here by taking |
|
@hachikuji @ijuma @lbradstreet Could you take a look? There are some follow-ups which can get back the performance we lose here and I'd like to work on them as soon as possible :) |
There was a problem hiding this comment.
I wonder if we could avoid all of this by requesting the Sender to create TopicProduceData directly. It seems that the Sender creates partitionRecords right before calling the builder: https://github.com/apache/kafka/blob/trunk/clients/src/main/java/org/apache/kafka/clients/producer/internals/Sender.java#L734. So we may be able to directly construct the expect data structure there.
There was a problem hiding this comment.
nice suggestion.
Could I address this in follow-up? I had filed jira (KAFKA-10696 ~ KAFKA-10698) to have Sender use auto-generated protocol directly.
There was a problem hiding this comment.
oh. The jira I created does not cover this issue. open a new ticket (https://issues.apache.org/jira/browse/KAFKA-10709)
There was a problem hiding this comment.
It seems that we could create ProduceResponseData based on data. This avoids the cost of the group-by operation and the cost of constructing partitionSizes. That should bring the benchmark inline with what we had before. Would this work?
There was a problem hiding this comment.
I used data to generate ProduceResponseData. However, the data may be null when create ProduceResponseData. That is to say, it require if-else to handle null data in getErrorResponse. It seems to me that is a bit ugly so not sure whether it is worth doing that.
There was a problem hiding this comment.
As we care of performances here, I wonder if we should try not using the stream api here.
Another trick would be to turn TopicProduceResponse in the ProduceResponse schema into a map by setting "mapKey": true for the topic name. This would allow to iterate over responses, get or create TopicProduceResponse for the topic, and add the PartitionProduceResponse into it.
It may be worth trying different implementation to compare their performances.
There was a problem hiding this comment.
It may be worth trying different implementation to compare their performances.
As we all care for performance, I'm ok to say goodbye to stream api :)
There was a problem hiding this comment.
I have addressed your suggestion and it does improve the performance.
cdac803 to
1011ec3
Compare
1b7cc44 to
1e36d8a
Compare
|
The last commit borrows some improvement from #9563. |
|
@hachikuji @ijuma @lbradstreet @dajac I have updated the perf result. The regression is reduced by last commit. Please take a look. |
|
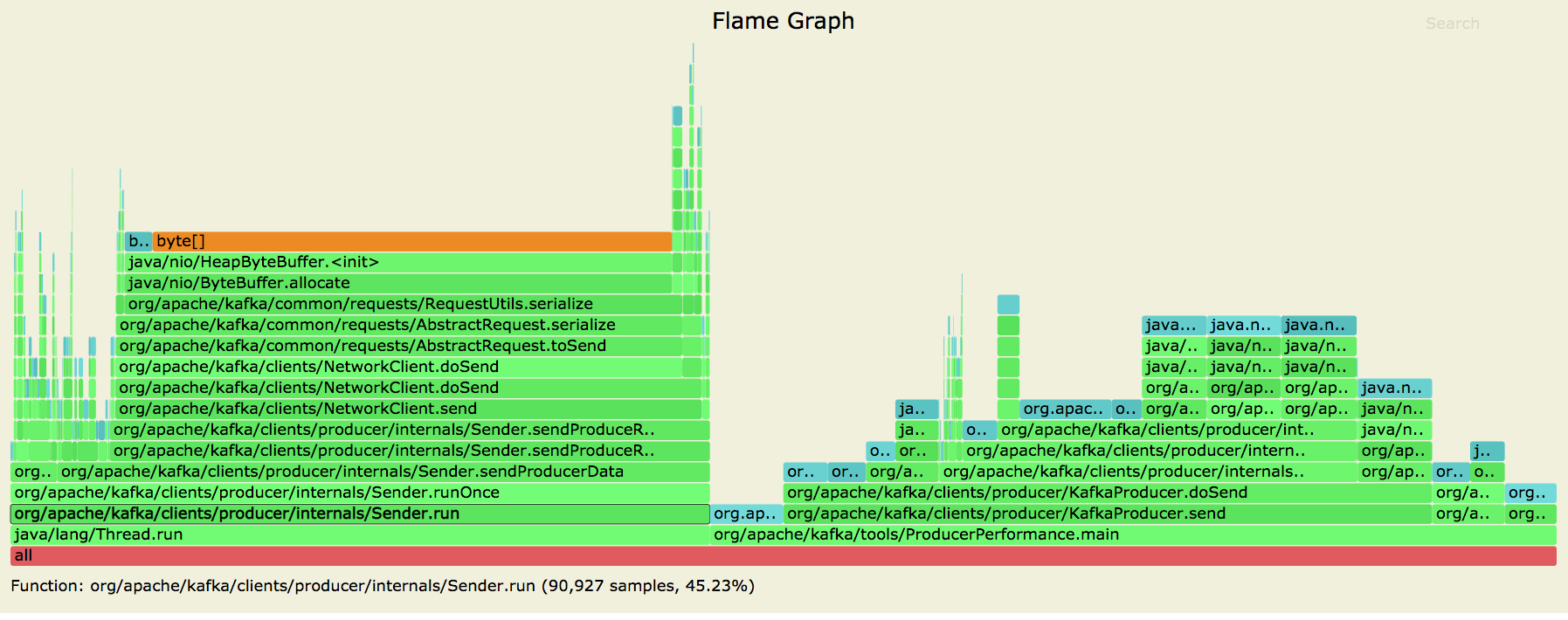
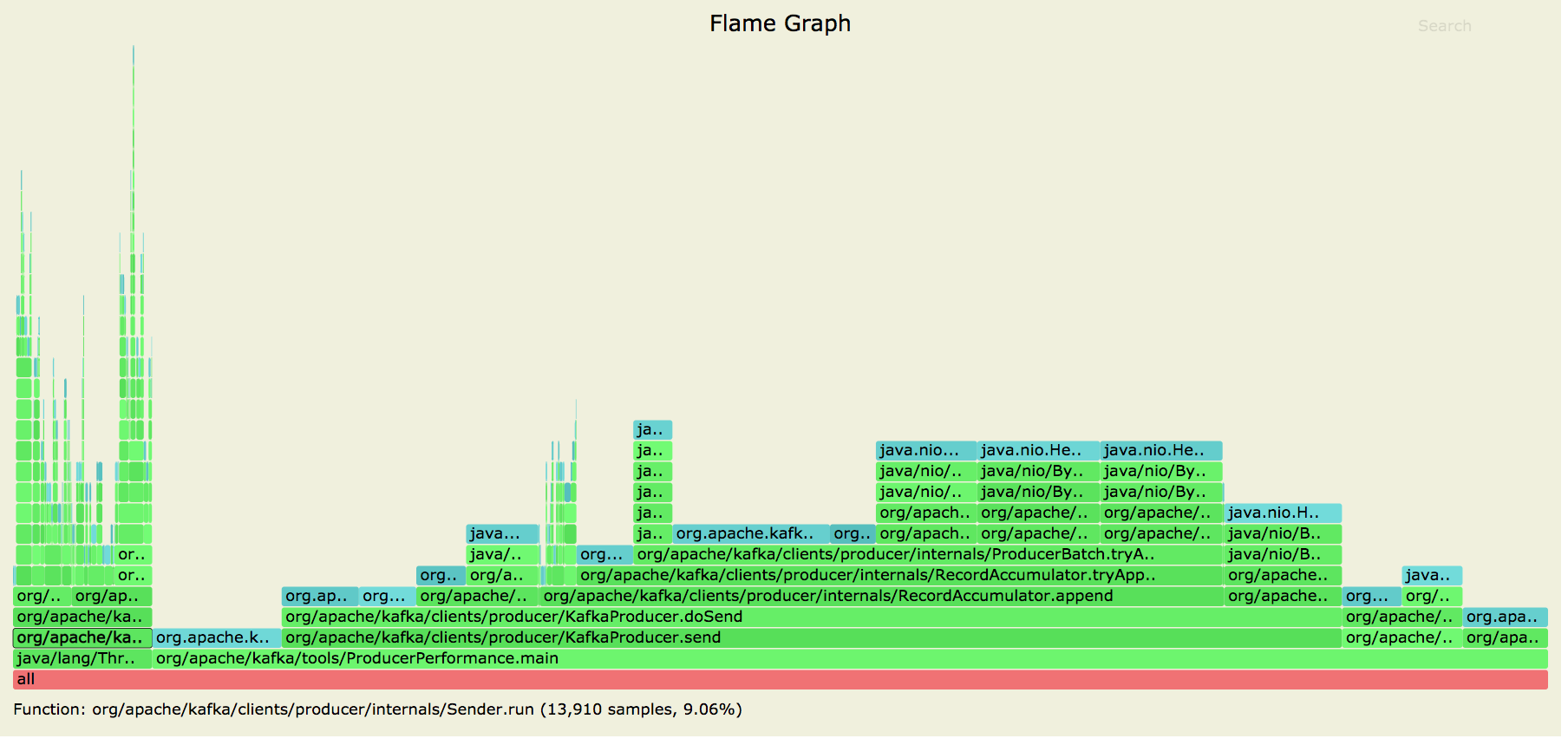
Posting allocation flame graphs from the producer before and after this patch:
So we succeeded in getting rid of the extra allocations in the network layer! I generated these graphs using the producer performance test writing to a topic with 10 partitions on a cluster with a single broker. |
2e4a7c2 to
3226967
Compare
 dajac
left a comment
dajac
left a comment
There was a problem hiding this comment.
LGTM, pending Jenkins. Thanks for the PR!
There was a problem hiding this comment.
I don't think it should be ignorable. Transactional requests require this in order to authorize.
There was a problem hiding this comment.
It seems to me ignorable should be true in order to keep behavior consistency. With "ignore=false", setting value to TransactionalId can cause UnsupportedVersionException if the version is small than 3. The previous code (https://github.com/apache/kafka/blob/trunk/clients/src/main/java/org/apache/kafka/common/requests/ProduceRequest.java#L286) does not cause such exception.
There was a problem hiding this comment.
The previous code probably relied on the range checking of the message format to imply support here. My point is that the request is doomed to fail if it holds transactional data and we drop the transactionalId. So we may as well fail fast.
There was a problem hiding this comment.
So we may as well fail fast.
That make sense. will revert this change.
There was a problem hiding this comment.
Indeed, that makes sense. My bad!
0ac91fe to
ffbe9a3
Compare
OffsetForLeaderEpoch and Produce are not yet generated RPCs, but will be once apache#9401 and apache#9547 are merged.
issue: https://issues.apache.org/jira/browse/KAFKA-9628
Benchmark
kafkatest.benchmarks.core.benchmark_test.Benchmark.test_producer_throughput
JMH results
In short, most ops performance are regression since we have to convert data to protocol data. The cost is inevitable (like other request/response) before we use protocol data directly.
JMH for ProduceRequest
BEFORE
AFTER
JMH for ProduceResponse
BEFORE
AFTER
Committer Checklist (excluded from commit message)