Description
On trying to train CiFAR-10 dataset with VGG16, I noticed the initial learning rate has to be set a very small value to make the training converging. According the implementation of fit.py under example/image-classification/common, the Xavier with Gaussian random type is set as the default weight initializing strategy.
On a NVIDIA P40 GPU, with CUDA-9.1 and openblas, I executed the following comparison tests:
Test 1: Initial LR = 0.01 Xavier with Gaussian random type
Test 2: Initial LR = 0.00025 Xavier with Gaussian random type
Test 3: Initial LR = 0.01 Xavier with uniform random type
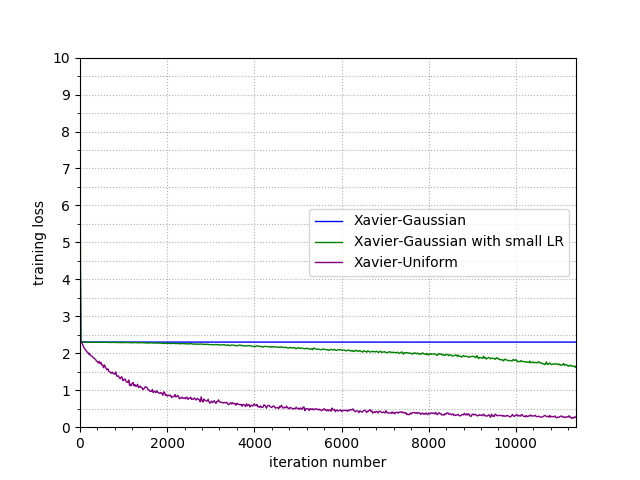
The following two figures are corresponding to the comparison of the trends of training top-1 accuracy and cross-entropy loss. The curves in blue, green, purple are corresponding to test 1, 2, 3 respectively.
It can be observed: with same initial LR (0.01), the training with Xavier-Gaussian will not converge, while the training with Xavier-uniform converges fast.
Similar phenomenon can also be observed when the dataset changed to CiFAR-100. (Retrieved from http://data.mxnet.io/data/cifar100.zip) When training CiFAR-100, the initial learning rate has to be set to 0.00001 if the Xavier-Gaussian is used to initialize the weight.

Environment info (Required)
HW: NVIDIA P40
SW: MxNet master branch, with CUDA-v9.1, CUDNN v7.1 and openblas 2.1
What to do:
- Download the training script from https://github.com/juliusshufan/mxnet
- Run the three python script correspond to test 1, 2, 3
(Note: The test script modified from the original train_cifar10.py coming with MXNET examples)
Build info (Required if built from source)
Compiler: gcc 4.8.5
MXNet commit hash: cea8d2f
Build config:
make -j($nproc) USE_OPENCV=1 USE_CUDA=1 USE_CUDNN=1 USE_BLAS=openblas USE_CUDA_PATH=/usr/local/cuda-9.1
What have you tried to solve it?
Using the Xavier with uniform random, but not the Gaussian random.
I have submitted a PR #9867, in which the weight initializing strategy will be set as Xavier-uniform if network is VGG, and the initializer will not be explicitly set in the training script.
Description
On trying to train CiFAR-10 dataset with VGG16, I noticed the initial learning rate has to be set a very small value to make the training converging. According the implementation of fit.py under example/image-classification/common, the Xavier with Gaussian random type is set as the default weight initializing strategy.
On a NVIDIA P40 GPU, with CUDA-9.1 and openblas, I executed the following comparison tests:
Test 1: Initial LR = 0.01 Xavier with Gaussian random type
Test 2: Initial LR = 0.00025 Xavier with Gaussian random type
Test 3: Initial LR = 0.01 Xavier with uniform random type
The following two figures are corresponding to the comparison of the trends of training top-1 accuracy and cross-entropy loss. The curves in blue, green, purple are corresponding to test 1, 2, 3 respectively.
It can be observed: with same initial LR (0.01), the training with Xavier-Gaussian will not converge, while the training with Xavier-uniform converges fast.
Similar phenomenon can also be observed when the dataset changed to CiFAR-100. (Retrieved from http://data.mxnet.io/data/cifar100.zip) When training CiFAR-100, the initial learning rate has to be set to 0.00001 if the Xavier-Gaussian is used to initialize the weight.
Environment info (Required)
HW: NVIDIA P40
SW: MxNet master branch, with CUDA-v9.1, CUDNN v7.1 and openblas 2.1
What to do:
(Note: The test script modified from the original train_cifar10.py coming with MXNET examples)
Build info (Required if built from source)
Compiler: gcc 4.8.5
MXNet commit hash: cea8d2f
Build config:
make -j($nproc) USE_OPENCV=1 USE_CUDA=1 USE_CUDNN=1 USE_BLAS=openblas USE_CUDA_PATH=/usr/local/cuda-9.1
What have you tried to solve it?
Using the Xavier with uniform random, but not the Gaussian random.
I have submitted a PR #9867, in which the weight initializing strategy will be set as Xavier-uniform if network is VGG, and the initializer will not be explicitly set in the training script.