Shared subscription: improvement with offloaded ledgers #16417
Conversation
|
We found trouble with consumption of an offloaded backlog using a shared subscription. (failover subscriptions perform well) Using the OMB we built a 64GB backlog of 100 byte messages with 10 topics with 3 partitions.
With this patch we see a big improvement and shared subscriptions are consumed like this: |
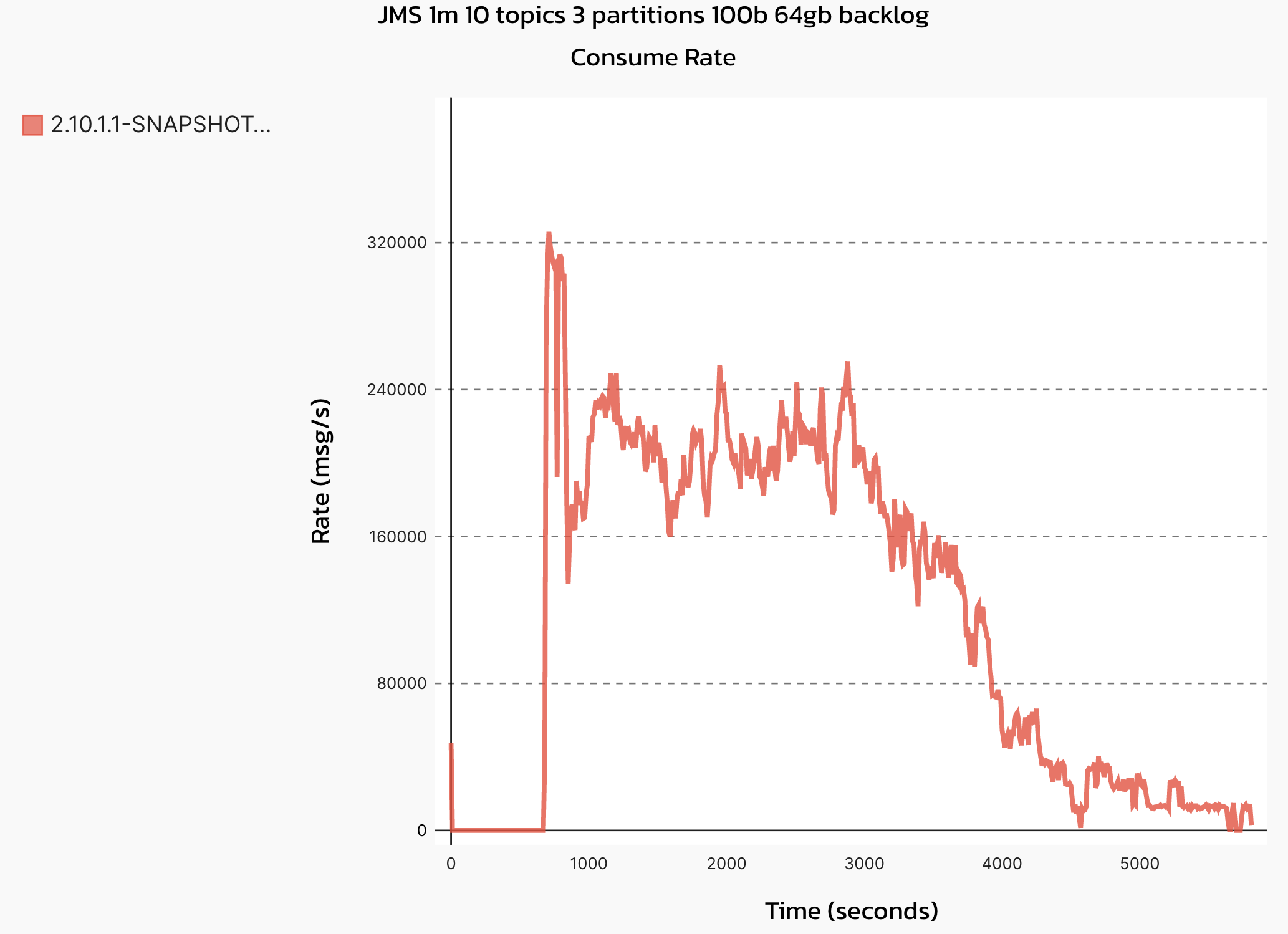
...in/java/org/apache/bookkeeper/mledger/offload/jcloud/impl/BlobStoreBackedReadHandleImpl.java
Outdated
Show resolved
Hide resolved
| // never over to the last entry again. | ||
| if (!seeked) { | ||
| inputStream.seek(index.getIndexEntryForEntry(nextExpectedId).getDataOffset()); | ||
| Long knownOffset = entryOffsets.get(nextExpectedId); |
There was a problem hiding this comment.
Maybe we can a function to package this logic and all the index.getIndexEntryForEntry(nextExpectedId).getDataOffset() call this function.
Other seek places also need to check the index cache first.
There was a problem hiding this comment.
sounds good, in my testing it looked that only this point needs the cache, btw it is better to use it everywhere
...c/test/java/org/apache/bookkeeper/mledger/offload/jcloud/BlobStoreBackedInputStreamTest.java
Outdated
Show resolved
Hide resolved
5997cd1 to
afea8e9
Compare
| // this Cache is accessed only by one thread | ||
| private final Cache<Long, Long> entryOffsets = CacheBuilder | ||
| .newBuilder() | ||
| .expireAfterAccess(10, TimeUnit.MINUTES) |
There was a problem hiding this comment.
10 minutes may be too short, 30 minutes to 1 hour? This cache can be shared with other catch-up readers.
There was a problem hiding this comment.
I have changed it to 30 minutes and made it configurable via system property
I don't think we have to document the system property, I made it configurable only in case of problems
|
ping @zymap @horizonzy please help take a look, thanks. |
dba2dba to
f0237a7
Compare
f0237a7 to
388912d
Compare
|
@eolivelli Please rebase the master branch |
|
@Technoboy- @codelipenghui |

Motivation
When you use a Shared subscription the Dispatcher (PersistentDispatcherMultipleConsumers) does our of order reads from the ManagedLedger, this is happening very frequently in the
consumerFlowmethod, that basically re-reads messages that have not been processed yet.This happens because
consumerFlowcalls readMoreEntries() and this in turn finds that there are messages to be re-delivered, because not yet acknowledged by any consumer.This fact triggers backward seeks in the BlobStoreBackedReadHandleImpl. Even if the data is already loaded in memory you have to parse it again most of the time, because the seek currently is done to the beginning of a block, because the index keeps only track of some entries and not of every entry.
Modifications
Add a in memory cache of the offsets of each entry, this way when you have to do a backward seek we do the seek exactly to the position where you can find the entry.
The trade-off here is that we build this TreeMap that adds some memory costs
Verifying this change
This change added tests.
I did some manual testing with GCP and this patch brings a x2 improvement on throughput of a Shared subscription (with pulsar-perf) with a single consumer.
@dave2wave did more extensive testing with complex scenarios with OpenMessaging Benchmark and confirmed that this patch brings a big improvement on Shared subscriptions.
doc-not-needed