[SPARK-22165][SQL] Fixes type conflicts between double, long, decimals, dates and timestamps in partition column #19389
Conversation
|
cc @cloud-fan (I believe my similar PR was reviewed by you before), @ueshin and @squito. |
|
Test build #82307 has finished for PR 19389 at commit
|
|
retest this please |
|
Test build #82310 has finished for PR 19389 at commit
|
 squito
left a comment
squito
left a comment
There was a problem hiding this comment.
lgtm, just a small comment on scoping, though I'm not an expert on this area. Left a couple of questions just for my own understanding.
Also, I'm curious why the tests are all going into ParquetPartitionDiscoverySuite -- this doesn't seem specific to parquet, and in fact I wonder if it will be different in parquet since the non-partition columns have schemas specified in the data. I'm just surprised this isn't tested across more formats.
There was a problem hiding this comment.
just for my own understanding -- these added asserts are just to improve failure msgs, right? They would have all been covered by the assert(actualSpec === spec) below anywyay, right?
There was a problem hiding this comment.
Yes, it is. It was difficult for me to find which one was different.
There was a problem hiding this comment.
this passes even before the change, right?
as I mentioned on the other PR, I don't really understand why this works despite the issue you're fixing. Regardless, seems like a good test to have.
There was a problem hiding this comment.
I think 2016-01-01 00:01:00 was placed first in literals somehow when calling resolveTypeConflicts. Let me try to make this test case not dependent on this.
There was a problem hiding this comment.
surprisingly, TypeCoercion is totally public, so this should probably be private[sql].
There was a problem hiding this comment.
Actually, these were removed in SPARK-16813 and #14418 :).
Yea, I agree since this problem is not specific to Parquet. Here, such changes and test cases look added in this file so far and I simply just decided to follow it, rather than including changes here restructuing or moving the test cases, partly for the easy of backporting (we should backport this into branch-2.2 and 2.1) and partly to reduce reviewing cost. |
|
Test build #82345 has finished for PR 19389 at commit
|
|
This PR introduces the behavior changes. We are unable to do this. |
|
Please ensure no behavior change is introduced when fixing such issues. Also cc @cloud-fan |
|
@gatorsmile, could you elaborate which behaviour changes you mean? |
|
Do you mean before / after in PR description? They are bugs to fix, aren't they? |
|
ping @gatorsmile |
|
ping? |
|
@cloud-fan, could you take a look when you have some time please? |
|
Will review it this weekend. |
|
Thank you so much @gatorsmile. |
|
Hi @gatorsmile, could you please review this when you have some time? |
|
Generally, the current type inference/coercion rules are messy and random. We have to seriously revisit our type coercion. After thinking it more, I think this change in this PR is pretty risky. It just introduces new type inference behaviors, although I do not like the previous one neither. These changes could easily cause new regression when our users upgrading their Spark versions. For making the migration more smooth, my general proposal is to introduce a conf for each one when we change something like this, if we believe this is a bug fix. Remove or deprecate the internal conf in the next release (or after a few releases) if nobody raises the issue after a major release (around half a year). |
|
Also cc @rxin @cloud-fan @sameeragarwal |
|
Maybe, what do you think about opening a discussion in the mailing list? If I understood correctly, some committers have a different opinion on this (did I understand correctly?). That should deduplicate a discussion about it. I am also willing to actively join in it. |
There was a problem hiding this comment.
I think it's a bug, the previous code didn't consider the case when input literal types are outside of the upCastingOrder, and just pick the first type as the final type.
However I'm not sure what's the expected behavior. We need to figure out what's the possible data types for partition columns, and how to merge them.
There was a problem hiding this comment.
Let me try to describe what this PR explicitly changes soon in terms of expected input types and merged types.
There was a problem hiding this comment.
I think we will have the input types for this resolveTypeConflicts:
Seq(
NullType, IntegerType, LongType, DoubleType,
*DecimalType(...), DateType, TimestampType, StringType)*DecimalType only when it's bigger than LongType:
Because:
this particular resolveTypeConflicts seems being only called through:
In the first call, I am seeing pathsWithPartitionValues is constructed by partitionValues, which is the output from parsePartition:
which parses the input by parsePartitionColumn:
which calls this inferPartitionColumnValue:
There was a problem hiding this comment.
So, for the types:
Seq(
NullType, IntegerType, LongType, DoubleType,
*DecimalType(...), DateType, TimestampType, StringType)I produced a chart as below by this codes:
test("Print out chart") {
val supportedTypes: Seq[DataType] = Seq(
NullType, IntegerType, LongType, DoubleType,
DecimalType(38, 0), DateType, TimestampType, StringType)
val combinations = for {
t1 <- supportedTypes
t2 <- supportedTypes
} yield Seq(t1,t2)
// Old type conflict resolution:
val upCastingOrder: Seq[DataType] =
Seq(NullType, IntegerType, LongType, FloatType, DoubleType, StringType)
def oldResolveTypeConflicts(dataTypes: Seq[DataType]): DataType = {
val topType = dataTypes.maxBy(upCastingOrder.indexOf(_))
if (topType == NullType) StringType else topType
}
// New type conflict resolution:
def newResolveTypeConflicts(dataTypes: Seq[DataType]): DataType = {
TypeCoercion.findWiderCommonType(dataTypes) match {
case Some(NullType) => StringType
case Some(dt: DataType) => dt
case _ => StringType
}
}
println("|Input types|Old output type|New output type|")
println("|-----------|---------------|---------------|")
combinations.foreach { pair =>
val oldType = oldResolveTypeConflicts(pair)
val newType = newResolveTypeConflicts(pair)
if (oldType != newType) {
println(s"|[`${pair(0)}`, `${pair(1)}`]|`$oldType`|`$newType`|")
}
}
}So, looks this PR makes the changes in type resolution as below:
| Input types | Old output type | New output type |
|---|---|---|
[NullType, DecimalType(38,0)] |
StringType |
DecimalType(38,0) |
[NullType, DateType] |
StringType |
DateType |
[NullType, TimestampType] |
StringType |
TimestampType |
[IntegerType, DecimalType(38,0)] |
IntegerType |
DecimalType(38,0) |
[IntegerType, DateType] |
IntegerType |
StringType |
[IntegerType, TimestampType] |
IntegerType |
StringType |
[LongType, DecimalType(38,0)] |
LongType |
DecimalType(38,0) |
[LongType, DateType] |
LongType |
StringType |
[LongType, TimestampType] |
LongType |
StringType |
[DoubleType, DateType] |
DoubleType |
StringType |
[DoubleType, TimestampType] |
DoubleType |
StringType |
[DecimalType(38,0), NullType] |
StringType |
DecimalType(38,0) |
[DecimalType(38,0), IntegerType] |
IntegerType |
DecimalType(38,0) |
[DecimalType(38,0), LongType] |
LongType |
DecimalType(38,0) |
[DecimalType(38,0), DateType] |
DecimalType(38,0) |
StringType |
[DecimalType(38,0), TimestampType] |
DecimalType(38,0) |
StringType |
[DateType, NullType] |
StringType |
DateType |
[DateType, IntegerType] |
IntegerType |
StringType |
[DateType, LongType] |
LongType |
StringType |
[DateType, DoubleType] |
DoubleType |
StringType |
[DateType, DecimalType(38,0)] |
DateType |
StringType |
[DateType, TimestampType] |
DateType |
TimestampType |
[TimestampType, NullType] |
StringType |
TimestampType |
[TimestampType, IntegerType] |
IntegerType |
StringType |
[TimestampType, LongType] |
LongType |
StringType |
[TimestampType, DoubleType] |
DoubleType |
StringType |
[TimestampType, DecimalType(38,0)] |
TimestampType |
StringType |
There was a problem hiding this comment.
I think the new behavior is much better. It seems like the previous behavior is just wrong, but it's very rare to see different data types in partition columns, and that's why no users open tickets for it yet.
cc @gatorsmile
There was a problem hiding this comment.
Do we really wanna document the previous wrong behavior in the doc? An example is merging TimestampType and DateType, the result is non-deterministic, depends on which partition path gets parsed first. How do we document that?
There was a problem hiding this comment.
BTW this is only used in partition discovery, I can't think of a problematic case for it. The only thing it can break is, users give Spark a data dir to do partition discovering, and users make an assumption on the inferred partition schema, but then we can argue that why users ask Spark to do partition discovery at the beginning?
There was a problem hiding this comment.
Both the values and the schemas could be changed. The external applications might be broken if the schema is different.
The new behaviors are consistent with what we does for the other type coercion cases. However, implicit type casting and partition discovery are unstable. The other mature systems have clear/stable rules about it. Below is an example. https://docs.oracle.com/cloud/latest/db112/SQLRF/sql_elements002.htm#g195937
If each release introduces new behaviors, it becomes hard to use by the end users who have such expectation. Thus, my suggestion is to first stabilize our type coercion rules before addressing this.
#18853 is the first PR attempt in this direction.
There was a problem hiding this comment.
Partitioned columns are different from normal type coercion cases, they are literally all string type, and we are just trying to find a most reasonable type of them.
The previous behavior was there since the very beginning, which I think didn't go through a decent discussion. This is the first time we seriously design the type merging logic for partition discovery. I think it doesn't need to be blocked by the type coercion stabilization work, as they can diverge.
@HyukjinKwon can you send the proposal to dev list? I think we need more feedback, e.g. people may want more strict rules and have more cases to fallback to string.
There was a problem hiding this comment.
Let me send the proposal to dev soon tonight (KST)
52d0cc8 to
a1f1c3a
Compare
|
I have just made a table to check the diff easily: Before:
After:
|
a1f1c3a to
07bcf36
Compare
|
Test build #84049 has finished for PR 19389 at commit
|
|
Test build #84051 has finished for PR 19389 at commit
|
|
retest this please |
|
Test build #84059 has finished for PR 19389 at commit
|
| * |DateType |DateType |StringType |StringType |StringType |StringType|DateType |TimestampType|StringType| | ||
| * |TimestampType |TimestampType |StringType |StringType |StringType |StringType|TimestampType|TimestampType|StringType| | ||
| * |StringType |StringType |StringType |StringType |StringType |StringType|StringType |StringType |StringType| | ||
| * +-----------------+-----------------+-----------------+-----------------+-----------------+----------+-------------+-------------+----------+ |
There was a problem hiding this comment.
we should also put this table in sql-programming-guide and sql migration guide.
| if (topType == NullType) StringType else topType | ||
| } | ||
| val litTypes = literals.map(_.dataType) | ||
| val desiredType = litTypes.fold[DataType](NullType)(findWiderTypeForPartitionColumn) |
There was a problem hiding this comment.
nit: I think we can use reduce? literals should not be empty.
There was a problem hiding this comment.
Yup. I just address this one and the one above.
|
|
||
| - Since Spark 2.3, the queries from raw JSON/CSV files are disallowed when the referenced columns only include the internal corrupt record column (named `_corrupt_record` by default). For example, `spark.read.schema(schema).json(file).filter($"_corrupt_record".isNotNull).count()` and `spark.read.schema(schema).json(file).select("_corrupt_record").show()`. Instead, you can cache or save the parsed results and then send the same query. For example, `val df = spark.read.schema(schema).json(file).cache()` and then `df.filter($"_corrupt_record".isNotNull).count()`. | ||
| - The `percentile_approx` function previously accepted numeric type input and output double type results. Now it supports date type, timestamp type and numeric types as input types. The result type is also changed to be the same as the input type, which is more reasonable for percentiles. | ||
| - Partition column inference previously found incorrect common type for different inferred types, for example, previously it ended up with double type as the common type for double type and date type. Now it finds the correct common type for such conflicts. The conflict resolution follows the table below: |
There was a problem hiding this comment.
Built doc shows as below:

| * | NullType | NullType | IntegerType | LongType | DecimalType(38,0) | DoubleType | DateType | TimestampType | StringType | | ||
| * | IntegerType | IntegerType | IntegerType | LongType | DecimalType(38,0) | DoubleType | StringType | StringType | StringType | | ||
| * | LongType | LongType | LongType | LongType | DecimalType(38,0) | StringType | StringType | StringType | StringType | | ||
| * | DecimalType(38,0) | DecimalType(38,0) | DecimalType(38,0) | DecimalType(38,0) | DecimalType(38,0) | StringType | StringType | StringType | StringType | |
There was a problem hiding this comment.
might be good to explain why we can only see DecimaType(38, 0)
|
LGTM |
|
One thing we can do in follow-up: the sql programming guide does have a partition discovery section, but it's under the parquet section, we should move it a layer up and put the type casting table there. |
|
|
||
| - Since Spark 2.3, the queries from raw JSON/CSV files are disallowed when the referenced columns only include the internal corrupt record column (named `_corrupt_record` by default). For example, `spark.read.schema(schema).json(file).filter($"_corrupt_record".isNotNull).count()` and `spark.read.schema(schema).json(file).select("_corrupt_record").show()`. Instead, you can cache or save the parsed results and then send the same query. For example, `val df = spark.read.schema(schema).json(file).cache()` and then `df.filter($"_corrupt_record".isNotNull).count()`. | ||
| - The `percentile_approx` function previously accepted numeric type input and output double type results. Now it supports date type, timestamp type and numeric types as input types. The result type is also changed to be the same as the input type, which is more reasonable for percentiles. | ||
| - Partition column inference previously found incorrect common type for different inferred types, for example, previously it ended up with double type as the common type for double type and date type. Now it finds the correct common type for such conflicts. The conflict resolution follows the table below: |
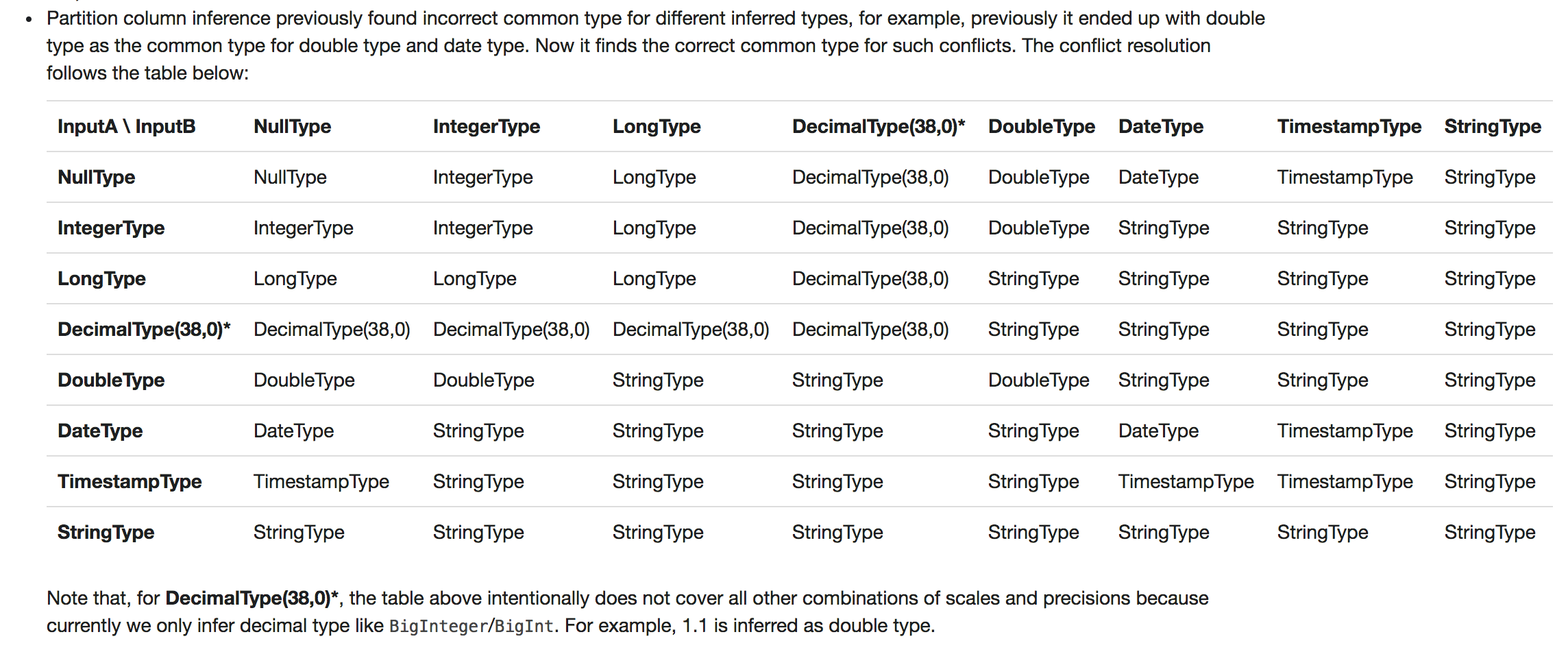
|
Test build #84073 has finished for PR 19389 at commit
|
|
Test build #84074 has finished for PR 19389 at commit
|
|
thanks, merging to master! |
What changes were proposed in this pull request?
This PR proposes to add a rule that re-uses
TypeCoercion.findWiderCommonTypewhen resolving type conflicts in partition values.Currently, this uses numeric precedence-like comparison; therefore, it looks introducing failures for type conflicts between timestamps, dates and decimals, please see:
The codes below:
produces output as below:
Before
After
Type coercion table:
This PR proposes the type conflict resolusion as below:
Before
NullTypeIntegerTypeLongTypeDecimalType(38,0)DoubleTypeDateTypeTimestampTypeStringTypeNullTypeStringTypeIntegerTypeLongTypeStringTypeDoubleTypeStringTypeStringTypeStringTypeIntegerTypeIntegerTypeIntegerTypeLongTypeIntegerTypeDoubleTypeIntegerTypeIntegerTypeStringTypeLongTypeLongTypeLongTypeLongTypeLongTypeDoubleTypeLongTypeLongTypeStringTypeDecimalType(38,0)StringTypeIntegerTypeLongTypeDecimalType(38,0)DoubleTypeDecimalType(38,0)DecimalType(38,0)StringTypeDoubleTypeDoubleTypeDoubleTypeDoubleTypeDoubleTypeDoubleTypeDoubleTypeDoubleTypeStringTypeDateTypeStringTypeIntegerTypeLongTypeDateTypeDoubleTypeDateTypeDateTypeStringTypeTimestampTypeStringTypeIntegerTypeLongTypeTimestampTypeDoubleTypeTimestampTypeTimestampTypeStringTypeStringTypeStringTypeStringTypeStringTypeStringTypeStringTypeStringTypeStringTypeStringTypeAfter
NullTypeIntegerTypeLongTypeDecimalType(38,0)DoubleTypeDateTypeTimestampTypeStringTypeNullTypeNullTypeIntegerTypeLongTypeDecimalType(38,0)DoubleTypeDateTypeTimestampTypeStringTypeIntegerTypeIntegerTypeIntegerTypeLongTypeDecimalType(38,0)DoubleTypeStringTypeStringTypeStringTypeLongTypeLongTypeLongTypeLongTypeDecimalType(38,0)StringTypeStringTypeStringTypeStringTypeDecimalType(38,0)DecimalType(38,0)DecimalType(38,0)DecimalType(38,0)DecimalType(38,0)StringTypeStringTypeStringTypeStringTypeDoubleTypeDoubleTypeDoubleTypeStringTypeStringTypeDoubleTypeStringTypeStringTypeStringTypeDateTypeDateTypeStringTypeStringTypeStringTypeStringTypeDateTypeTimestampTypeStringTypeTimestampTypeTimestampTypeStringTypeStringTypeStringTypeStringTypeTimestampTypeTimestampTypeStringTypeStringTypeStringTypeStringTypeStringTypeStringTypeStringTypeStringTypeStringTypeStringTypeThis was produced by:
How was this patch tested?
Unit tests added in
ParquetPartitionDiscoverySuite.