[SPARK-42771][SQL] Refactor HiveGenericUDF #40394
Conversation
|
cc @cloud-fan, It's appreciated if it can be reviewed in your convenience, thanks! |
| } | ||
| } | ||
|
|
||
| class HiveGenericUDFHelper( |
There was a problem hiding this comment.
how about HiveGenericUDFEvaluator?
| private[hive] val deterministic = isUDFDeterministic && children.forall(_.deterministic) | ||
|
|
||
| @transient | ||
| private[hive] val foldable = |
There was a problem hiding this comment.
why do we define these properties here instead of in the expression? are we going to reuse it in HiveSimpleUDF?
There was a problem hiding this comment.
If we do not define dataType foldable deterministic properties in this class, we will have to expose some internal logic, such as returnInspector
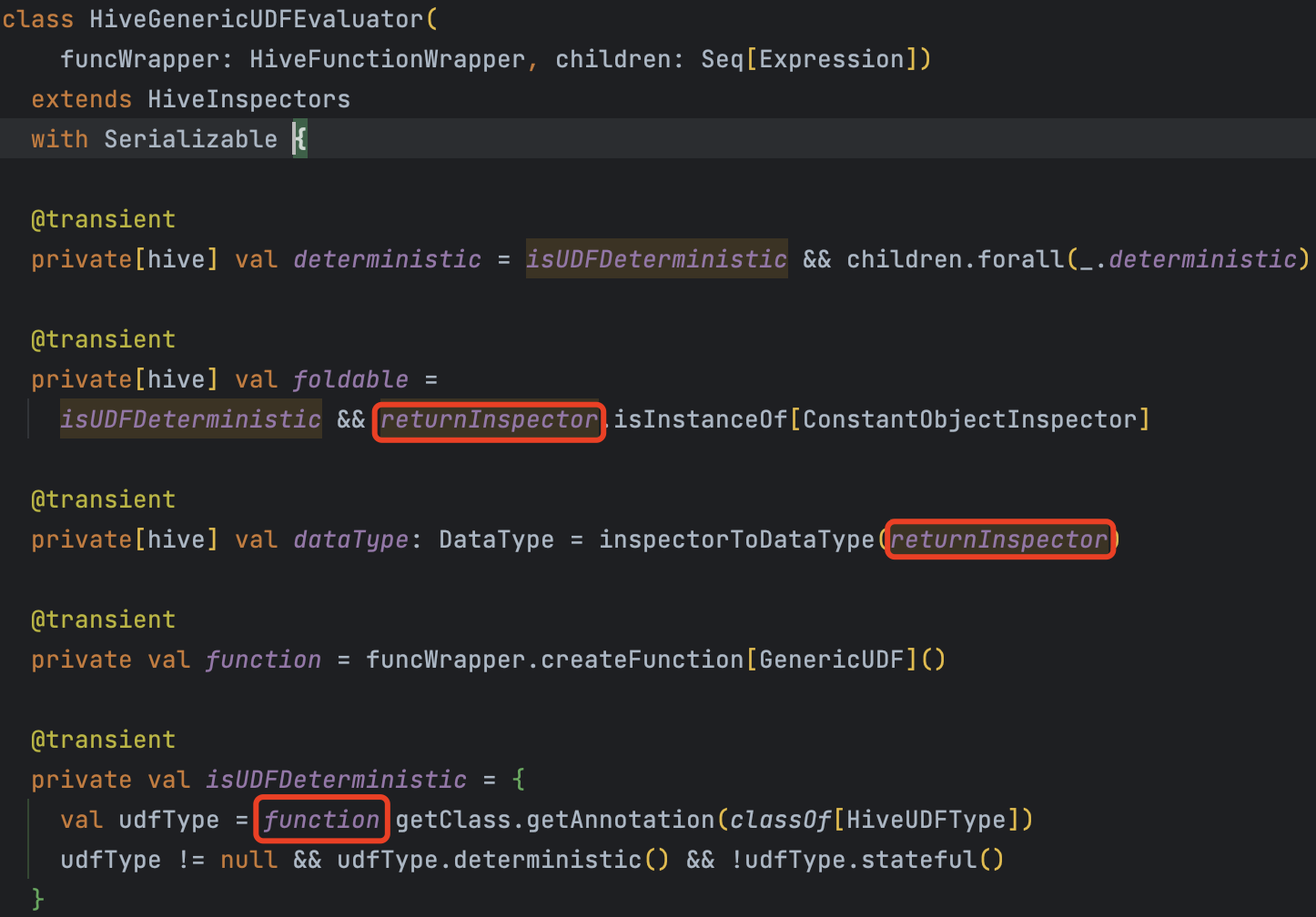
With the similar implementation of HiveSimpleUDF, I found some common properties, or I can do some abstraction and reuse later.
There was a problem hiding this comment.
SGTM, we can probably add a base class HiveUDFEvaluatorBase
There was a problem hiding this comment.
When I am working on HiveSimpleUDF , I will try to do this.
| private lazy val argumentInspectors = children.map(toInspector) | ||
|
|
||
| @transient | ||
| private lazy val deferredObjects: Array[DeferredObject] = argumentInspectors.zip(children).map { |
There was a problem hiding this comment.
lazy val has perf overhead. I don't think this class needs any lazy val, but itself should be lazy val in HiveGenericUDF
There was a problem hiding this comment.
when we reference the new evaluator, some properties in HiveGenericUDFEvaluator will have to use lazy, because it needs to be recreated on the Executor side.
There was a problem hiding this comment.
This makes me think that we should only keep execution-related things in this evaluator: function and deferredObjects. Can we expose argumentInspectors so that expression can define dataType, foldable, etc.?
There was a problem hiding this comment.
For expression can define dataType, foldable, deterministic, we will expose argumentInspectors , returnInspector.
Done
| override protected def doGenCode(ctx: CodegenContext, ev: ExprCode): ExprCode = { | ||
|
|
||
| protected def doGenCode(ctx: CodegenContext, ev: ExprCode): ExprCode = { | ||
| val refTerm = ctx.addReferenceObj("this", this) |
There was a problem hiding this comment.
do we still reference the entire this? Can we just reference the new evaluator?
There was a problem hiding this comment.
Very good suggestions!
BTW, when we reference the new evaluator, some properties in HiveGenericUDFEvaluator will have to use lazy, because it needs to be recreated on the Executor side.
| private lazy val returnInspector = { | ||
| function.initializeAndFoldConstants(argumentInspectors.toArray) | ||
| } | ||
| override lazy val dataType: DataType = evaluator.dataType |
There was a problem hiding this comment.
| override lazy val dataType: DataType = evaluator.dataType | |
| override def dataType: DataType = evaluator.dataType |
There was a problem hiding this comment.
If remove lazy, the following error will be generated
[info] - SPARK-28012 Hive UDF supports struct type foldable expression *** FAILED *** (43 milliseconds)
[info] org.apache.spark.SparkException: [INTERNAL_ERROR] Cannot evaluate expression: name
[info] at org.apache.spark.SparkException$.internalError(SparkException.scala:77)
[info] at org.apache.spark.SparkException$.internalError(SparkException.scala:81)
[info] at org.apache.spark.sql.errors.QueryExecutionErrors$.cannotEvaluateExpressionError(QueryExecutionErrors.scala:66)
[info] at org.apache.spark.sql.catalyst.expressions.Unevaluable.eval(Expression.scala:384)
[info] at org.apache.spark.sql.catalyst.expressions.Unevaluable.eval$(Expression.scala:383)
[info] at org.apache.spark.sql.catalyst.expressions.PrettyAttribute.eval(namedExpressions.scala:381)
[info] at org.apache.spark.sql.catalyst.expressions.CreateNamedStruct.$anonfun$names$1(complexTypeCreator.scala:437)
[info] at scala.collection.immutable.List.map(List.scala:293)
[info] at org.apache.spark.sql.catalyst.expressions.CreateNamedStruct.names$lzycompute(complexTypeCreator.scala:437)
[info] at org.apache.spark.sql.catalyst.expressions.CreateNamedStruct.names(complexTypeCreator.scala:437)
[info] at org.apache.spark.sql.catalyst.expressions.CreateNamedStruct.dataType$lzycompute(complexTypeCreator.scala:446)
[info] at org.apache.spark.sql.catalyst.expressions.CreateNamedStruct.dataType(complexTypeCreator.scala:445)
[info] at org.apache.spark.sql.catalyst.expressions.CreateNamedStruct.dataType(complexTypeCreator.scala:432)
[info] at org.apache.spark.sql.hive.HiveInspectors.toInspector(HiveInspectors.scala:930)
[info] at org.apache.spark.sql.hive.HiveInspectors.toInspector$(HiveInspectors.scala:864)
[info] at org.apache.spark.sql.hive.HiveGenericUDFEvaluator.toInspector(hiveUDFs.scala:204)
[info] at org.apache.spark.sql.hive.HiveGenericUDFEvaluator.$anonfun$argumentInspectors$1(hiveUDFs.scala:219)
[info] at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:286)
[info] at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
[info] at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
[info] at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
[info] at scala.collection.TraversableLike.map(TraversableLike.scala:286)
[info] at scala.collection.TraversableLike.map$(TraversableLike.scala:279)
[info] at scala.collection.AbstractTraversable.map(Traversable.scala:108)
[info] at org.apache.spark.sql.hive.HiveGenericUDFEvaluator.(hiveUDFs.scala:219)
[info] at org.apache.spark.sql.hive.HiveGenericUDF.evaluator$lzycompute(hiveUDFs.scala:143)
[info] at org.apache.spark.sql.hive.HiveGenericUDF.evaluator(hiveUDFs.scala:143)
[info] at org.apache.spark.sql.hive.HiveGenericUDF.(hiveUDFs.scala:140)
[info] at org.apache.spark.sql.hive.HiveGenericUDF.copy(hiveUDFs.scala:130)
[info] at org.apache.spark.sql.hive.HiveGenericUDF.withNewChildrenInternal(hiveUDFs.scala:160)
[info] at org.apache.spark.sql.hive.HiveGenericUDF.withNewChildrenInternal(hiveUDFs.scala:129)
[info] at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$withNewChildren$2(TreeNode.scala:390)
[info] at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:104)
[info] at org.apache.spark.sql.catalyst.trees.TreeNode.withNewChildren(TreeNode.scala:389)
[info] at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:750)
[info] at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:517)
[info] at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$3(TreeNode.scala:517)
[info] at org.apache.spark.sql.catalyst.trees.BinaryLike.mapChildren(TreeNode.scala:1275)
[info] at org.apache.spark.sql.catalyst.trees.BinaryLike.mapChildren$(TreeNode.scala:1274)
[info] at org.apache.spark.sql.catalyst.expressions.BinaryExpression.mapChildren(Expression.scala:652)
[info] at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:517)
[info] at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:488)
[info] at org.apache.spark.sql.catalyst.trees.TreeNode.transform(TreeNode.scala:456)
[info] at org.apache.spark.sql.catalyst.util.package$.usePrettyExpression(package.scala:110)
[info] at org.apache.spark.sql.catalyst.util.package$$anonfun$usePrettyExpression$1.applyOrElse(package.scala:117)
[info] at org.apache.spark.sql.catalyst.util.package$$anonfun$usePrettyExpression$1.applyOrElse(package.scala:110)
[info] at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$1(TreeNode.scala:512)
[info] at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:104)
[info] at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:512)
[info] at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:488)
[info] at org.apache.spark.sql.catalyst.trees.TreeNode.transform(TreeNode.scala:456)
[info] at org.apache.spark.sql.catalyst.util.package$.usePrettyExpression(package.scala:110)
[info] at org.apache.spark.sql.catalyst.util.package$.toPrettySQL(package.scala:145)
[info] at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveAliases$$anonfun$$nestedInanonfun$assignAliases$2$1.applyOrElse(Analyzer.scala:496)
[info] at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveAliases$$anonfun$$nestedInanonfun$assignAliases$2$1.applyOrElse(Analyzer.scala:484)
[info] at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformUpWithPruning$2(TreeNode.scala:566)
[info] at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:104)
[info] at org.apache.spark.sql.catalyst.trees.TreeNode.transformUpWithPruning(TreeNode.scala:566)
[info] at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveAliases$.$anonfun$assignAliases$2(Analyzer.scala:484)
[info] at scala.collection.immutable.List.map(List.scala:293)
[info] at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveAliases$.org$apache$spark$sql$catalyst$analysis$Analyzer$ResolveAliases$$assignAliases(Analyzer.scala:484)
[info] at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveAliases$$anonfun$apply$6.applyOrElse(Analyzer.scala:525)
[info] at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveAliases$$anonfun$apply$6.applyOrElse(Analyzer.scala:512)
[info] at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.$anonfun$resolveOperatorsUpWithPruning$3(AnalysisHelper.scala:138)
[info] at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:104)
[info] at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.$anonfun$resolveOperatorsUpWithPruning$1(AnalysisHelper.scala:138)
[info] at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.allowInvokingTransformsInAnalyzer(AnalysisHelper.scala:323)
[info] at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.resolveOperatorsUpWithPruning(AnalysisHelper.scala:134)
[info] at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.resolveOperatorsUpWithPruning$(AnalysisHelper.scala:130)
[info] at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveOperatorsUpWithPruning(LogicalPlan.scala:31)
[info] at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveAliases$.apply(Analyzer.scala:512)
[info] at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveAliases$.apply(Analyzer.scala:471)
[info] at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$2(RuleExecutor.scala:222)
[info] at scala.collection.LinearSeqOptimized.foldLeft(LinearSeqOptimized.scala:126)
[info] at scala.collection.LinearSeqOptimized.foldLeft$(LinearSeqOptimized.scala:122)
[info] at scala.collection.immutable.List.foldLeft(List.scala:91)
[info] at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$1(RuleExecutor.scala:219)
[info] at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$1$adapted(RuleExecutor.scala:211)
[info] at scala.collection.immutable.List.foreach(List.scala:431)
[info] at org.apache.spark.sql.catalyst.rules.RuleExecutor.execute(RuleExecutor.scala:211)
[info] at org.apache.spark.sql.catalyst.analysis.Analyzer.org$apache$spark$sql$catalyst$analysis$Analyzer$$executeSameContext(Analyzer.scala:228)
[info] at org.apache.spark.sql.catalyst.analysis.Analyzer.$anonfun$execute$1(Analyzer.scala:224)
[info] at org.apache.spark.sql.catalyst.analysis.AnalysisContext$.withNewAnalysisContext(Analyzer.scala:173)
[info] at org.apache.spark.sql.catalyst.analysis.Analyzer.execute(Analyzer.scala:224)
[info] at org.apache.spark.sql.catalyst.analysis.Analyzer.execute(Analyzer.scala:188)
[info] at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$executeAndTrack$1(RuleExecutor.scala:182)
[info] at org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:88)
[info] at org.apache.spark.sql.catalyst.rules.RuleExecutor.executeAndTrack(RuleExecutor.scala:182)
[info] at org.apache.spark.sql.catalyst.analysis.Analyzer.$anonfun$executeAndCheck$1(Analyzer.scala:209)
[info] at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.markInAnalyzer(AnalysisHelper.scala:330)
[info] at org.apache.spark.sql.catalyst.analysis.Analyzer.executeAndCheck(Analyzer.scala:208)
[info] at org.apache.spark.sql.hive.test.TestHiveQueryExecution.$anonfun$analyzed$1(TestHive.scala:624)
[info] at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:813)
[info] at org.apache.spark.sql.hive.test.TestHiveQueryExecution.analyzed$lzycompute(TestHive.scala:600)
[info] at org.apache.spark.sql.hive.test.TestHiveQueryExecution.analyzed(TestHive.scala:600)
[info] at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:66)
[info] at org.apache.spark.sql.Dataset$.$anonfun$ofRows$1(Dataset.scala:90)
[info] at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:813)
[info] at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:88)
[info] at org.apache.spark.sql.hive.test.TestHiveSparkSession.$anonfun$sql$1(TestHive.scala:240)
[info] at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:813)
[info] at org.apache.spark.sql.hive.test.TestHiveSparkSession.sql(TestHive.scala:238)
[info] at org.apache.spark.sql.test.SQLTestUtilsBase.$anonfun$sql$1(SQLTestUtils.scala:232)
[info] at org.apache.spark.sql.hive.execution.HiveUDFSuite.$anonfun$new$100(HiveUDFSuite.scala:651)
[info] at org.apache.spark.sql.QueryTest.checkAnswer(QueryTest.scala:133)
[info] at org.apache.spark.sql.hive.execution.HiveUDFSuite.$anonfun$new$99(HiveUDFSuite.scala:652)
[info] at org.apache.spark.sql.test.SQLTestUtilsBase.withUserDefinedFunction(SQLTestUtils.scala:255)
[info] at org.apache.spark.sql.test.SQLTestUtilsBase.withUserDefinedFunction$(SQLTestUtils.scala:253)
[info] at org.apache.spark.sql.hive.execution.HiveUDFSuite.withUserDefinedFunction(HiveUDFSuite.scala:58)
[info] at org.apache.spark.sql.hive.execution.HiveUDFSuite.$anonfun$new$98(HiveUDFSuite.scala:646)
[info] at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
[info] at org.scalatest.OutcomeOf.outcomeOf(OutcomeOf.scala:85)
[info] at org.scalatest.OutcomeOf.outcomeOf$(OutcomeOf.scala:83)
[info] at org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104)
[info] at org.scalatest.Transformer.apply(Transformer.scala:22)
[info] at org.scalatest.Transformer.apply(Transformer.scala:20)
[info] at org.scalatest.funsuite.AnyFunSuiteLike$$anon$1.apply(AnyFunSuiteLike.scala:226)
[info] at org.apache.spark.SparkFunSuite.withFixture(SparkFunSuite.scala:207)
[info] at org.scalatest.funsuite.AnyFunSuiteLike.invokeWithFixture$1(AnyFunSuiteLike.scala:224)
[info] at org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$runTest$1(AnyFunSuiteLike.scala:236)
[info] at org.scalatest.SuperEngine.runTestImpl(Engine.scala:306)
[info] at org.scalatest.funsuite.AnyFunSuiteLike.runTest(AnyFunSuiteLike.scala:236)
[info] at org.scalatest.funsuite.AnyFunSuiteLike.runTest$(AnyFunSuiteLike.scala:218)
[info] at org.apache.spark.SparkFunSuite.org$scalatest$BeforeAndAfterEach$$super$runTest(SparkFunSuite.scala:66)
[info] at org.scalatest.BeforeAndAfterEach.runTest(BeforeAndAfterEach.scala:234)
[info] at org.scalatest.BeforeAndAfterEach.runTest$(BeforeAndAfterEach.scala:227)
[info] at org.apache.spark.SparkFunSuite.runTest(SparkFunSuite.scala:66)
[info] at org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$runTests$1(AnyFunSuiteLike.scala:269)
[info] at org.scalatest.SuperEngine.$anonfun$runTestsInBranch$1(Engine.scala:413)
[info] at scala.collection.immutable.List.foreach(List.scala:431)
[info] at org.scalatest.SuperEngine.traverseSubNodes$1(Engine.scala:401)
[info] at org.scalatest.SuperEngine.runTestsInBranch(Engine.scala:396)
[info] at org.scalatest.SuperEngine.runTestsImpl(Engine.scala:475)
[info] at org.scalatest.funsuite.AnyFunSuiteLike.runTests(AnyFunSuiteLike.scala:269)
[info] at org.scalatest.funsuite.AnyFunSuiteLike.runTests$(AnyFunSuiteLike.scala:268)
[info] at org.scalatest.funsuite.AnyFunSuite.runTests(AnyFunSuite.scala:1564)
[info] at org.scalatest.Suite.run(Suite.scala:1114)
[info] at org.scalatest.Suite.run$(Suite.scala:1096)
[info] at org.scalatest.funsuite.AnyFunSuite.org$scalatest$funsuite$AnyFunSuiteLike$$super$run(AnyFunSuite.scala:1564)
[info] at org.scalatest.funsuite.AnyFunSuiteLike.$anonfun$run$1(AnyFunSuiteLike.scala:273)
[info] at org.scalatest.SuperEngine.runImpl(Engine.scala:535)
[info] at org.scalatest.funsuite.AnyFunSuiteLike.run(AnyFunSuiteLike.scala:273)
[info] at org.scalatest.funsuite.AnyFunSuiteLike.run$(AnyFunSuiteLike.scala:272)
[info] at org.apache.spark.SparkFunSuite.org$scalatest$BeforeAndAfterAll$$super$run(SparkFunSuite.scala:66)
[info] at org.scalatest.BeforeAndAfterAll.liftedTree1$1(BeforeAndAfterAll.scala:213)
[info] at org.scalatest.BeforeAndAfterAll.run(BeforeAndAfterAll.scala:210)
[info] at org.scalatest.BeforeAndAfterAll.run$(BeforeAndAfterAll.scala:208)
[info] at org.apache.spark.SparkFunSuite.run(SparkFunSuite.scala:66)
[info] at org.scalatest.tools.Framework.org$scalatest$tools$Framework$$runSuite(Framework.scala:321)
[info] at org.scalatest.tools.Framework$ScalaTestTask.execute(Framework.scala:517)
[info] at sbt.ForkMain$Run.lambda$runTest$1(ForkMain.java:413)
[info] at java.util.concurrent.FutureTask.run(FutureTask.java:266)
[info] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
[info] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
[info] at java.lang.Thread.run(Thread.java:750)
| }.toArray[DeferredObject] | ||
|
|
||
| override lazy val dataType: DataType = inspectorToDataType(returnInspector) | ||
| private[hive] lazy val evaluator = new HiveGenericUDFEvaluator(funcWrapper, children) |
There was a problem hiding this comment.
| private[hive] lazy val evaluator = new HiveGenericUDFEvaluator(funcWrapper, children) | |
| private lazy val evaluator = new HiveGenericUDFEvaluator(funcWrapper, children) |
unless we need to access it somewhere.
There was a problem hiding this comment.
When we reference the new evaluator, private[hive] -> private is ok.
| private lazy val function = funcWrapper.createFunction[GenericUDF]() | ||
|
|
||
| @transient | ||
| private[hive] val getUDFType = function.getClass.getAnnotation(classOf[HiveUDFType]) |
There was a problem hiding this comment.
This is only called in the expression, we can move it out
There was a problem hiding this comment.
In this way, we will have to expose function, Is that OK?
sql/hive/src/main/scala/org/apache/spark/sql/hive/hiveUDFs.scala
Outdated
Show resolved
Hide resolved
sql/hive/src/main/scala/org/apache/spark/sql/hive/hiveUDFs.scala
Outdated
Show resolved
Hide resolved
sql/hive/src/main/scala/org/apache/spark/sql/hive/hiveUDFs.scala
Outdated
Show resolved
Hide resolved
sql/hive/src/main/scala/org/apache/spark/sql/hive/hiveUDFs.scala
Outdated
Show resolved
Hide resolved
sql/hive/src/main/scala/org/apache/spark/sql/hive/hiveUDFs.scala
Outdated
Show resolved
Hide resolved
sql/hive/src/main/scala/org/apache/spark/sql/hive/hiveUDFs.scala
Outdated
Show resolved
Hide resolved
Co-authored-by: Wenchen Fan <cloud0fan@gmail.com>
Co-authored-by: Wenchen Fan <cloud0fan@gmail.com>
Co-authored-by: Wenchen Fan <cloud0fan@gmail.com>
Co-authored-by: Wenchen Fan <cloud0fan@gmail.com>
Co-authored-by: Wenchen Fan <cloud0fan@gmail.com>
Co-authored-by: Wenchen Fan <cloud0fan@gmail.com>
|
thanks, merging to master! |
What changes were proposed in this pull request?
The pr aims to refactor HiveGenericUDF.
Why are the changes needed?
Following #39949.
Make the code more concise.
Does this PR introduce any user-facing change?
No.
How was this patch tested?
Pass GA.