Repo này fork từ Build a Large Language Model (From Scratch)

Tip: Nếu chưa cài đặt môi trường, có thể xem hướng dẫn từ README.md trong thư mục setup.
| Danh sách các chương | Nội dung chính | Tất cả tài liệu + code |
|---|---|---|
| Ch 1: Hiểu về mô hình ngôn ngữ lớn | No code | - |
| Ch 2: Xử lý dữ liệu văn bản | - ch02.ipynb - dataloader.ipynb (summary) - exercise-solutions.ipynb |
./ch02 |
| Ch 3: Cơ chế Attention | - ch03.ipynb - multihead-attention.ipynb (summary) - exercise-solutions.ipynb |
./ch03 |
| Ch 4: Triển khai mô hình GPT | - ch04.ipynb - gpt.py (summary) - exercise-solutions.ipynb |
./ch04 |
| Ch 5: Tiền huấn luyện với dữ liệu không gán nhãn | - ch05.ipynb - gpt_train.py (summary) - gpt_generate.py (summary) - exercise-solutions.ipynb |
./ch05 |
| Ch 6: Tinh chỉnh cho nhiệm vụ phân loại văn bản | - ch06.ipynb - gpt_class_finetune.py - exercise-solutions.ipynb |
./ch06 |
| Ch 7: Tinh chỉnh mô hình theo phương pháp Instruction fine-tuning | - ch07.ipynb - gpt_instruction_finetuning.py (summary) - ollama_evaluate.py (summary) - exercise-solutions.ipynb |
./ch07 |
| Phụ lục A: Giới thiệu PyTorch | - code-part1.ipynb - code-part2.ipynb - DDP-script.py - exercise-solutions.ipynb |
./appendix-A |
| Phụ lục B: Tài liệu tham khảo | No code | - |
| Phụ lục C: Đáp án các bài tập | No code | - |
| Phụ lục D: Adding Bells and Whistles to the Training Loop | - appendix-D.ipynb | ./appendix-D |
| Phụ lục E: Tinh chỉnh hiệu quả tham số với LoRA | - appendix-E.ipynb | ./appendix-E |
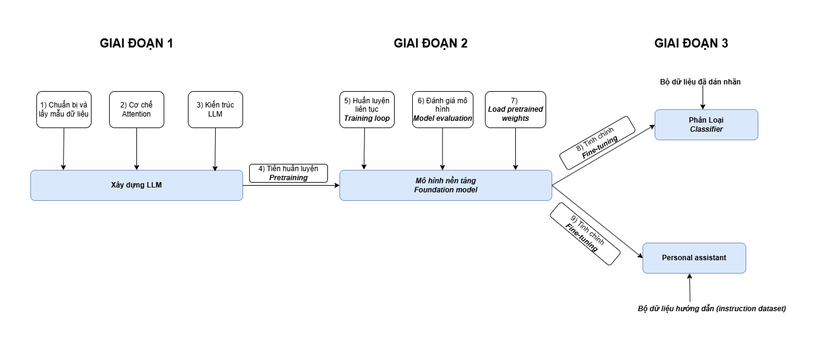
Mô tả trực quan nội dụng của các chương và các phần
Một cái laptop, có GPU càng tốt. Cầu hình yếu quá thì có thể lên Google Colab
- Cài đặt
- Chương 2: Làm việc với dữ liệu văn bản
- Chương 3: Cơ chế attention
- Chương 4: Triển khai mô hình GPT model từ đầu
- Chương 5: Tiền huấn luyện với dữ liệu không gán nhãn:
- Alternative Weight Loading Methods
- Pretraining GPT on the Project Gutenberg Dataset
- Adding Bells and Whistles to the Training Loop
- Optimizing Hyperparameters for Pretraining
- Building a User Interface to Interact With the Pretrained LLM
- Converting GPT to Llama
- Llama 3.2 From Scratch
- Memory-efficient Model Weight Loading
- Extending the Tiktoken BPE Tokenizer with New Tokens
- PyTorch Performance Tips for Faster LLM Training
- Chương 6: Tinh chỉnh cho mục đích phân loại văn bản
- Chương 7: Tỉnh chỉnh mô hình nghe theo chỉ dẫn
- Dataset Utilities for Finding Near Duplicates and Creating Passive Voice Entries
- Evaluating Instruction Responses Using the OpenAI API and Ollama
- Generating a Dataset for Instruction Finetuning
- Improving a Dataset for Instruction Finetuning
- Generating a Preference Dataset with Llama 3.1 70B and Ollama
- Direct Preference Optimization (DPO) for LLM Alignment
- Building a User Interface to Interact With the Instruction Finetuned GPT Model