Dashboard for failed tasks #6595
Conversation
|
Thoughts on using the Jinja template pages instead? The Bokeh tables aren't the greatest. My sense is that tracebacks will be pretty critical here. |
Yeah, I can definitely do a jinja template. I'm a little skittish about putting tracebacks in a Note that I put the traceback in a tooltip for this table, so it is available, though not very well formatted. |
Unit Test ResultsSee test report for an extended history of previous test failures. This is useful for diagnosing flaky tests. 15 files ± 0 15 suites ±0 6h 42m 30s ⏱️ - 3h 38m 55s For more details on these failures, see this check. Results for commit 83ca016. ± Comparison against base commit a8eb3b2. ♻️ This comment has been updated with latest results. |
|
We could also grab code from the oldest computation associated to the exception. I think that Bokeh is good when we're doing live-updating. This seems like a case where that doesn't need to be the case. The info pages might be simpler to work with and give us more flexilibity generally. |
|
Also, in case the info pages aren't well known to you (I think I'm the only person who has touched them (it shows)) there are some pointers in the text of #6539 (in case you skimmed over it) |
They're known, though I don't tend to go that way very often as they don't really play nicely with the labextension |
|
Hrm, interesting point. I think that with this though I think that over
time we're going to want to invest more into the UX beyond what the bokeh
table and maybe even the JLab widgets can support. I think that clicking
into the exception to get more information is important. I could imagine
navigating to the task. I could even imagine (with some more security
involved) clicking a button to retry the task.
The bokeh plots are great for at a glance dynamic stuff. This feels more
like a "let's dig in" situation where something else might be more
appropriate.
…On Fri, Jun 17, 2022, 4:48 PM Ian Rose ***@***.***> wrote:
Also, in case the info pages aren't well known to you (I think I'm the
only person who has touched them (it shows)) there are some pointers in the
text of #6539 <#6539> (in case
you skimmed over it)
They're known, though I don't tend to go that way very often as they don't
really play nicely with the labextension
—
Reply to this email directly, view it on GitHub
<#6595 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AACKZTC2LFNCKTSEIP2KLGDVPUFENANCNFSM5ZDI5RRQ>
.
You are receiving this because you commented.Message ID:
***@***.***>
|
|
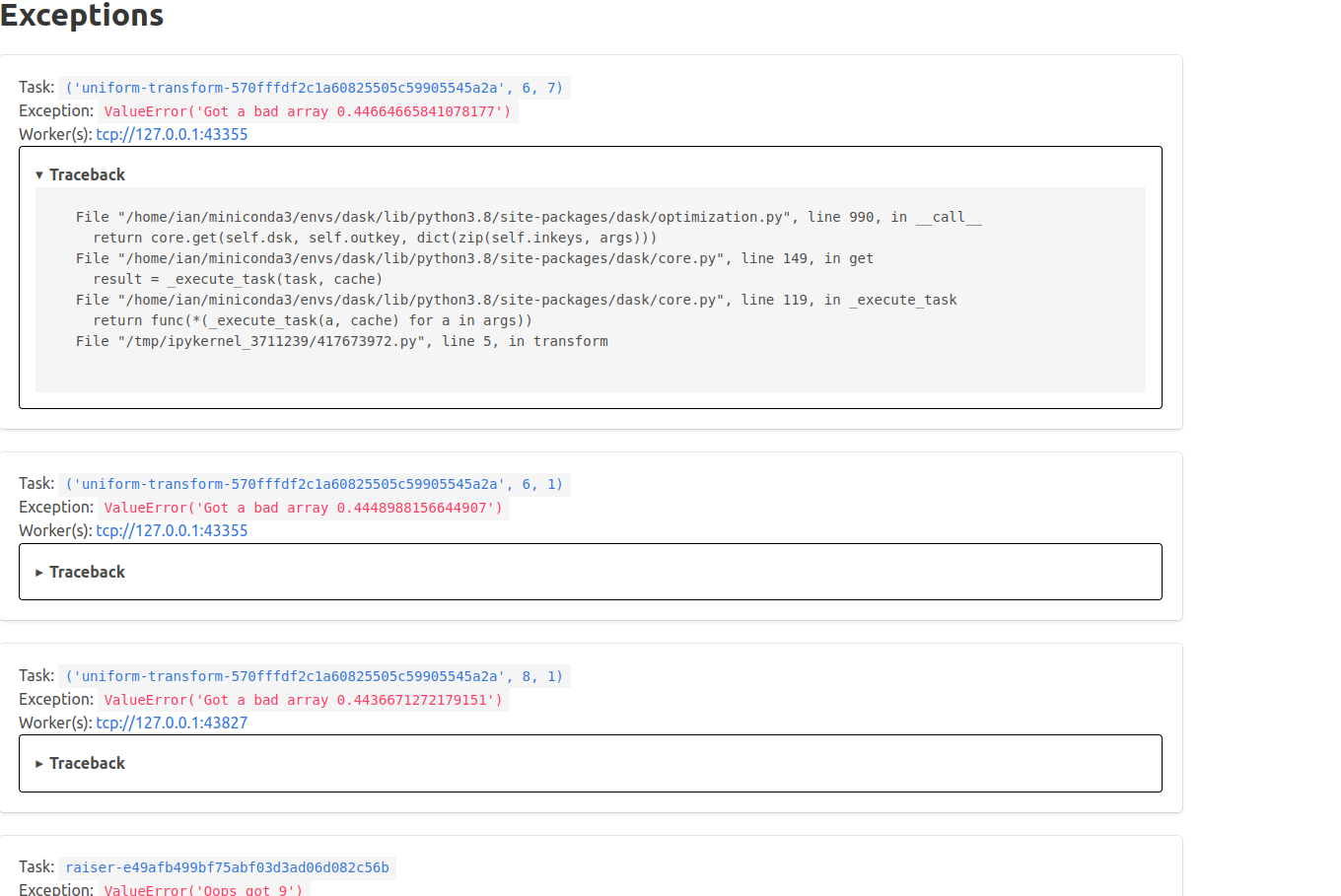
Updated with a dedicated HTML template for exceptions: |
991454d to
63cef84
Compare
|
This is ready for review. The bokeh stuff is logically separate from the HTML template, and I could easily remove it, though I personally found it helpful when developing this. |
|
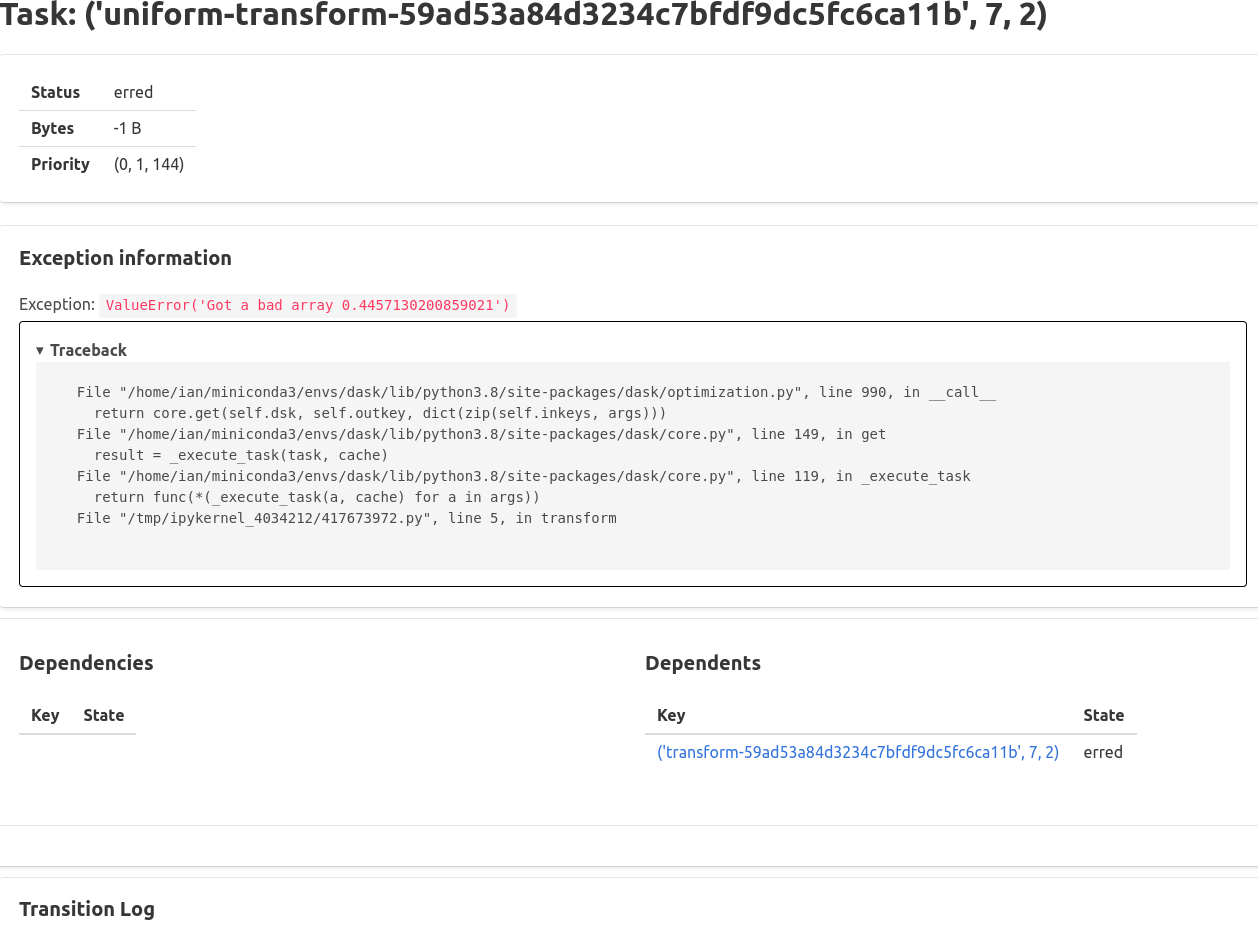
Also added some info on the individual tasks page if there is an error:
|
| self.group_exceptions[(ts.group_key, ex)]["workers"].add(w or worker) | ||
| self.group_exceptions[(ts.group_key, ex)]["count"] += 1 | ||
| self.group_exceptions[(ts.group_key, ex)]["last_seen"] = time() | ||
|
|
There was a problem hiding this comment.
I'm hesitant to add more state to the scheduler for this. Instead, keeping with the single-point-of-truth approach, I wonder if we can grab this information from the existing state.
Perhaps we could wander through all task groups, find any with erred tasks, and then use those?
Or is your goal to capture a history of exceptions? Typically the Dask dashboard doesn't try to capture much history. It's more about getting a view of current state. Thoughts?
There was a problem hiding this comment.
My goal here was actually to do a level of deduplication, effectively trying to hash based on (group, exception_type), so that many similar-but-not-identical exceptions are consolidated into a single row.
Perhaps we could wander through all task groups, find any with erred tasks, and then use those?
Yes, I can refactor to do something like that. One thing that I did find helpful was keeping errored tasks in a deque to force them to be in scope a bit longer. Otherwise it was too easy to loose task state for what is presumably a forensic exercise. So I might stick up for that data structure with some history a bit more than this deduplicated-dictionary.
There was a problem hiding this comment.
Okay, I've removed (most of) the state, and it now has a lighter footprint on the scheduler
There was a problem hiding this comment.
I think what we've found useful to have is the exception and the traceback on the exception for investigating what went wrong, but I agree that I wouldn't want multiple states for this.
For the future (if this helps guide your design decisions) I can imagine:
- wanting to retry these tasks via the dashboard
- Figuring out what input mapped to each failed task (in particular for large client.map calls).
In our experience tasks generally fail:
- All with exactly the same exception/traceback (example: something in the submitted function is broken)
- All with the same exception/mostly the same traceback (example: some service is just down)
- Singleish task failures (some specific input is bad)
There was a problem hiding this comment.
Thanks for the insights @gerrymanoim! A few thoughts inline:
For the future (if this helps guide your design decisions) I can imagine:
1. wanting to retry these tasks via the dashboard
This would be really cool, though we'd probably want to proceed carefully, since adding things which actually affect scheduler state to the dashboard brings in some serious security considerations (cf #6407). I don't think anything in this design would prevent us from doing this, however, should we figure out good ways of handling the security concerns.
2. Figuring out what input mapped to each failed task (in particular for large client.map calls).
I also added the exception information to the individual task page, so as a user one can go from Exceptions -> individual task -> dependencies all via links. Does that work for the type of investigations you are thinking about?
* All with exactly the same exception/traceback (example: something in the submitted function is broken) * All with the same exception/mostly the same traceback (example: some service is just down) * Singleish task failures (some specific input is bad)
An earlier version of this did some light attempts at deduplicating similar tasks (e.g., they are all the same, but the chunk/partition index is different, so the text is strictly different). I have some thoughts about how that might be done, but for the time being I've removed that logic in favor of simplicity. If huge numbers of similar tasks winds up being a problem with this approach, I'd certainly be interested in hearing about it!
There was a problem hiding this comment.
since adding things which actually affect scheduler state to the dashboard brings in some serious security considerations
Definitely a fair point. Maybe something that's better as a (future) jupyter widget instead of on the dashboard? I can imagine a whole UI wrapper for as_completed that gives you progress/tracebacks/restarts (just thinking out loud here).
Exceptions -> individual task -> dependencies
Does dependencies mean upstream nodes in the graph? Or the actual input (if any) a dask was passed? i.e. if I do
def fail_if_two(x):
if x == 2:
raise RuntimeError("It was two!")
numbers_to_run = list(range(1000))
futures = client.map(fail_if_two, numbers_to_run)will I be able to recover 2 via the dashboard?
If huge numbers of similar tasks winds up being a problem with this approach, I'd certainly be interested in hearing about it!
👍 will report back - thanks!
There was a problem hiding this comment.
We can consider dashboard pages that affect state. Arguably the Dask Dashboard should be treated more securely than it currently is by most systems. We'd want to iterate with a broader set of stakeholders here first, but I'm open to it.
Does dependencies mean upstream nodes in the graph? Or the actual input (if any) a dask was passed? i.e. if I do
By dependencies I think that @ian-r-rose mostly means upstream nodes, and not inputs. Inputs might be tricky currently because they're currently stored in serialized form in the scheduler (and the scheduler isn't supposed to unpack them). This will change if we merge in #6028 (on hold until stability issues stabilize (which it seems like maybe they have?)).
There was a problem hiding this comment.
By dependencies I think that @ian-r-rose mostly means upstream nodes, and not inputs
That's correct, the upstream task nodes are visible, but their deserialized inputs are not. For your example, if I edit it to have some upstream tasks:
def fail_if_two(x):
if x == 2:
raise RuntimeError("It was two!")
def inc(x):
return x + 1
numbers_to_run = list(range(1000))
futures_a = client.map(inc, numbers_to_run)
futures_b = client.map(fail_if_two, futures_a)I will be able to see that the exception has an inc task as a dependency, but not what the actual input value was.
There was a problem hiding this comment.
Understood - thanks for the clarifications.
|
I like the content on the exceptions page. I also like that it's on the info page for the task. Question though, how does one navigate to this page? |
There is a new "Exceptions" button at the top of the landing info page |
|
Ah ha! So there is. |
| ) | ||
| self.erred_tasks: deque[TaskState] = deque( | ||
| maxlen=dask.config.get("distributed.diagnostics.erred-tasks.max-history") | ||
| ) |
There was a problem hiding this comment.
@crusaderky will keeping around a deque of references to old TaskStates that have failed cause any issues that you can think of?
There was a problem hiding this comment.
I would wipe out the run_spec, as it can be potentially several MB per tasks. It's what we already do with the to_loggable method in worker_state_machine.py.
There was a problem hiding this comment.
@ian-r-rose you should be able to do this by grepping for del self.tasks in scheduler.py. Just before the del line we'd also del ts.run_spec`.
There was a problem hiding this comment.
I would also be fine just not tracking exceptions in this way and losing them when they go out of scope. I'm not sure that the benefit added by this page outweighs the extra state in the scheduler. My inclination would be to remove the deque entirely if that's possible.
There was a problem hiding this comment.
I would also be fine just not tracking exceptions in this way and losing them when they go out of scope. I'm not sure that the benefit added by this page outweighs the extra state in the scheduler. My inclination would be to remove the deque entirely if that's possible.
It's definitely possible (and not hard), I am just not convinced that it results in a good user experience. To get really concrete, if I run the following:
import time
import dask
import distributed
cluster = distributed.LocalCluster()
client = distributed.Client(cluster)
@dask.delayed
def func(x):
time.sleep(1)
raise ValueError(f"Oops got {x}")
func(10).compute()The exceptions are not reachable on the dashboard, because there are no futures hanging on to the task reference, and they are very quickly cleaned up by the scheduler. This is true of basically any .compute() call that errors. In practice, I think that means that a lot of exceptions would not be visible, and it would not be possible to do any sort of forensics after-the-fact. Having a relatively short data structure that keeps them for a bit longer results in a real UX improvement.
There was a problem hiding this comment.
My understanding is that @gjoseph92 is going to take a look at this and provide a tiebreaking vote
erred_tasks dict also hangs on to some references to task states, but we don't care about their (possibly large) run_specs
 gjoseph92
left a comment
gjoseph92
left a comment
There was a problem hiding this comment.
I'm hesitant to add more state to the scheduler for this
I agree. I find adding a dedicated SchedulerState field just for a dashboard to use to be a bit much.
I also don't like holding onto TaskState objects (even with their runspecs cleared), since they have references to other tasks, and we want to get better about not keeping long-lived reference cycles around: #6250.
In principle, I also don't like keeping exceptions around for tasks that have been released. On a long-lived cluster, or just when you're iterating quickly, this could be confusing and messy. However, losing the exceptions from every compute call is probably worse UX. Ideally, maybe we'd keep them around, but at least have a clear button? That's not a pattern we support anywhere else on the dashboard though, so I think the way you have it now is the best pattern to start with.
Additionally, implementing this without some extra state is not feasible. Single-source-of-truth-ing it would require iterating through all of scheduler.tasks. I don't think there's any state that could restrict this search; task groups don't link back to the tasks they contain, so that doesn't help.
Rather than the erred_tasks queue and holding TaskStates, what if you use a scheduler plugin, like the TaskStream does?
from distributed.scheduler import TaskState
from dataclasses import dataclass
@dataclass
class ErredTaskInfo:
key: str
erred_on: set[str]
exception_text: str
traceback_text: str
class ErredTasksPlugin(SchedulerPlugin):
name = "erred-tasks"
def __init__(self, scheduler):
self.errors: deque[ErredTaskInfo] = deque(
maxlen=dask.config.get(
"distributed.scheduler.dashboard.erred-tasks.max-history"
)
)
self.scheduler = scheduler
def transition(self, key, start, finish, *args, **kwargs):
if finish == "erred":
ts: TaskState = self.scheduler.tasks[key]
self.errors.append(
ErredTaskInfo(key, ts.erred_on, ts.exception_text, ts.traceback_text)The downside is that errors won't be recorded until you've already opened the errors page on the dashboard, which is a bit annoying.
I'd be okay with this. Agree that the "register on first load" behavior is potentially annoying and confusing to users, but perhaps not too bad. |
|
I'd also be okay with |
Also fine with me. If the main concern is rogue references, I think this would provide the best UX. |
|
I gave the latter suggestion a shot -- thoughts? |
gjoseph92
left a comment
There was a problem hiding this comment.
This looks good. I'm happy with the ErredTask compromise, I think it'll be worth it. Excited to have this!
|
Thanks for the reviews @mrocklin and @gjoseph92 and the merge, @crusaderky! |
Not ready yet, but putting this out for early visibility. I also want to add similar data to the individual scheduler and worker info pages, as well as add various tests. Closes #6539
pre-commit run --all-files