p2p: Add in-memory buffering for output DiskShardsBuffer #7664
Conversation
It is likely that at least some part (possibly all) of the output of the shuffle will fit in memory. In this circumstance, we don't need to necessarily write output shards to disk only to read them in later. To enable this, provide (optional) in-memory buffering on the output DiskShardsBuffer. While the total output size is less than some limit, don't bother hitting the disk, but rather just hold in memory references. Once too much data has arrived, block to flush these buffers to disk. When reading, we now might have some shards in memory, so we concatenate these with the on-disk buffers.
|
@hendrikmakait / @fjetter Do you have example scaled workflows to test for performance. On my system (16 cores, 128GiB RAM, reasonably fast disk), this gives about a 20% performance boost (20s as opposed to 25s) over trunk for this example. Obviously this fits in memory, so that's a best case scenario. |
Unit Test ResultsSee test report for an extended history of previous test failures. This is useful for diagnosing flaky tests. 26 files ± 0 26 suites ±0 13h 41m 7s ⏱️ + 1h 31m 4s For more details on these failures, see this check. Results for commit 2e287c0. ± Comparison against base commit af14180. This pull request removes 33 and adds 100 tests. Note that renamed tests count towards both.This pull request skips 2 tests.♻️ This comment has been updated with latest results. |
|
I'll run an A/B test on our benchmark suite. |
|
FYI: When running our benchmark suite, some workloads timed out and rechunking failed entirely. See https://github.com/coiled/coiled-runtime/actions/runs/4451074014 for the benchmark summary, I'll be on PTO next week, I suggest to coordinate with @fjetter in the meantime. |
Thanks. i'll try and replicate to see what is happening |
I think this is a consequence of me hard-coding (rather than taking the configuration from the worker's available memory) the size of the in-memory buffer each worker is allowed to use before flushing to disk. I had 1GiB but all the failing tests in your A/B run run with a |
Ah, apologies. It's not just this, I get ---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
File ~/third-party/distributed/distributed/shuffle/_rechunk.py:57, in rechunk_unpack()
56 try:
---> 57 return _get_worker_extension().get_output_partition(
58 id, barrier_run_id, output_chunk
59 )
60 except Exception as e:
File ~/third-party/distributed/distributed/shuffle/_worker_extension.py:903, in get_output_partition()
902 shuffle = self.get_shuffle_run(shuffle_id, run_id)
--> 903 return sync(self.worker.loop, shuffle.get_output_partition, output_partition)
File ~/third-party/distributed/distributed/utils.py:416, in sync()
415 typ, exc, tb = error
--> 416 raise exc.with_traceback(tb)
417 else:
File ~/third-party/distributed/distributed/utils.py:389, in f()
388 future = asyncio.ensure_future(future)
--> 389 result = yield future
390 except Exception:
File ~/compose/etc/conda/cuda_11.8/envs/rapids/lib/python3.10/site-packages/tornado/gen.py:769, in run()
768 try:
--> 769 value = future.result()
770 except Exception:
File ~/third-party/distributed/distributed/shuffle/_worker_extension.py:376, in get_output_partition()
374 return convert_chunk(data, subdims)
--> 376 return await self.offload(_)
File ~/third-party/distributed/distributed/shuffle/_worker_extension.py:132, in offload()
131 with self.time("cpu"):
--> 132 return await asyncio.get_running_loop().run_in_executor(
133 self.executor,
134 func,
135 *args,
136 )
File ~/compose/etc/conda/cuda_11.8/envs/rapids/lib/python3.10/concurrent/futures/thread.py:58, in run()
57 try:
---> 58 result = self.fn(*self.args, **self.kwargs)
59 except BaseException as exc:
File ~/third-party/distributed/distributed/shuffle/_worker_extension.py:374, in _()
373 subdims = tuple(len(self._old_to_new[dim][ix]) for dim, ix in enumerate(i))
--> 374 return convert_chunk(data, subdims)
File ~/third-party/distributed/distributed/shuffle/_worker_extension.py:989, in convert_chunk()
988 arrs = rec_cat_arg.tolist()
--> 989 return concatenate3(arrs)
File ~/compose/etc/conda/cuda_11.8/envs/rapids/lib/python3.10/site-packages/dask/array/core.py:5315, in concatenate3()
5314 arr = arr[None, ...]
-> 5315 result[idx] = arr
5317 return result
ValueError: could not broadcast input array from shape (0,20) into shape (20,20)
The above exception was the direct cause of the following exception:
RuntimeError Traceback (most recent call last)So I must be restoring data incorrectly somehow, let me investigate. |
Fixes somes shards going "missing".
When buffering disk output, don't hardcode the memory limit, but rather allow up to a quarter of the worker's memory to be used.
|
I think I fixed this (the coiled benchmarks that were failing are now not failing locally for me), I was inadvertantly overwriting a shard ID when flush the memory buffer to disk, so data were being incorrectly assigned to the wrong output id in some cases. |
|
Probably need to update the
|
I needed to provide it at all... |
 fjetter
left a comment
fjetter
left a comment
There was a problem hiding this comment.
adding a config option and a test or two and we're good to go, I believe. I noticed a failing test test_bad_disk that is likely related because you're setting the threshold large enough that this test doesn't touch disk. Should be fixed with a config option as well
Thanks, I think this is now (pending tests) good to go too. One query is whether or not to run the whole test suite in "buffer in memory" as well as "hit disk" mode, or just a few select tests. So far I have only done the latter. But since this flips a default to be "buffer in memory" only a few tests now explicitly hit disk in the output phase of shuffles. |
Good point. I wouldn't want to run everything in |
Done with three size options:
|
|
I ran this on an actual cluster once and adjusted the buffer size a bit. I think we'll need to iterate on this a little more.
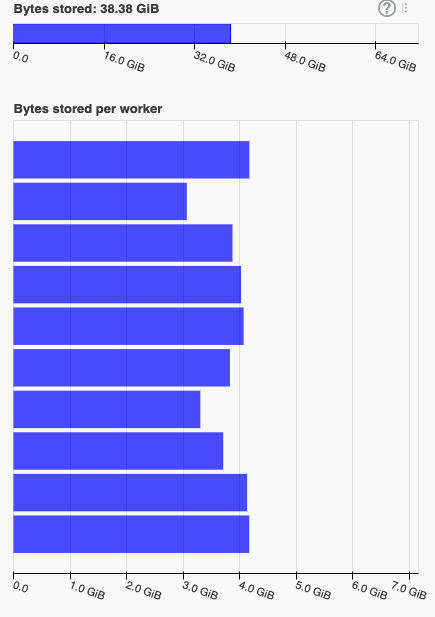
This specific run was using 8GiB workers and I set the limit to half of that. Once the buffer reaches this size, we can see that the computation freezes up. Some still running transfers take up ~10s (ordinarily 500ms) and new ones are not even scheduled. This is very likely due to a blocked event loop when writing 4GiB at once. It also looks like we got some leftover data in memory after the shuffle completed
|
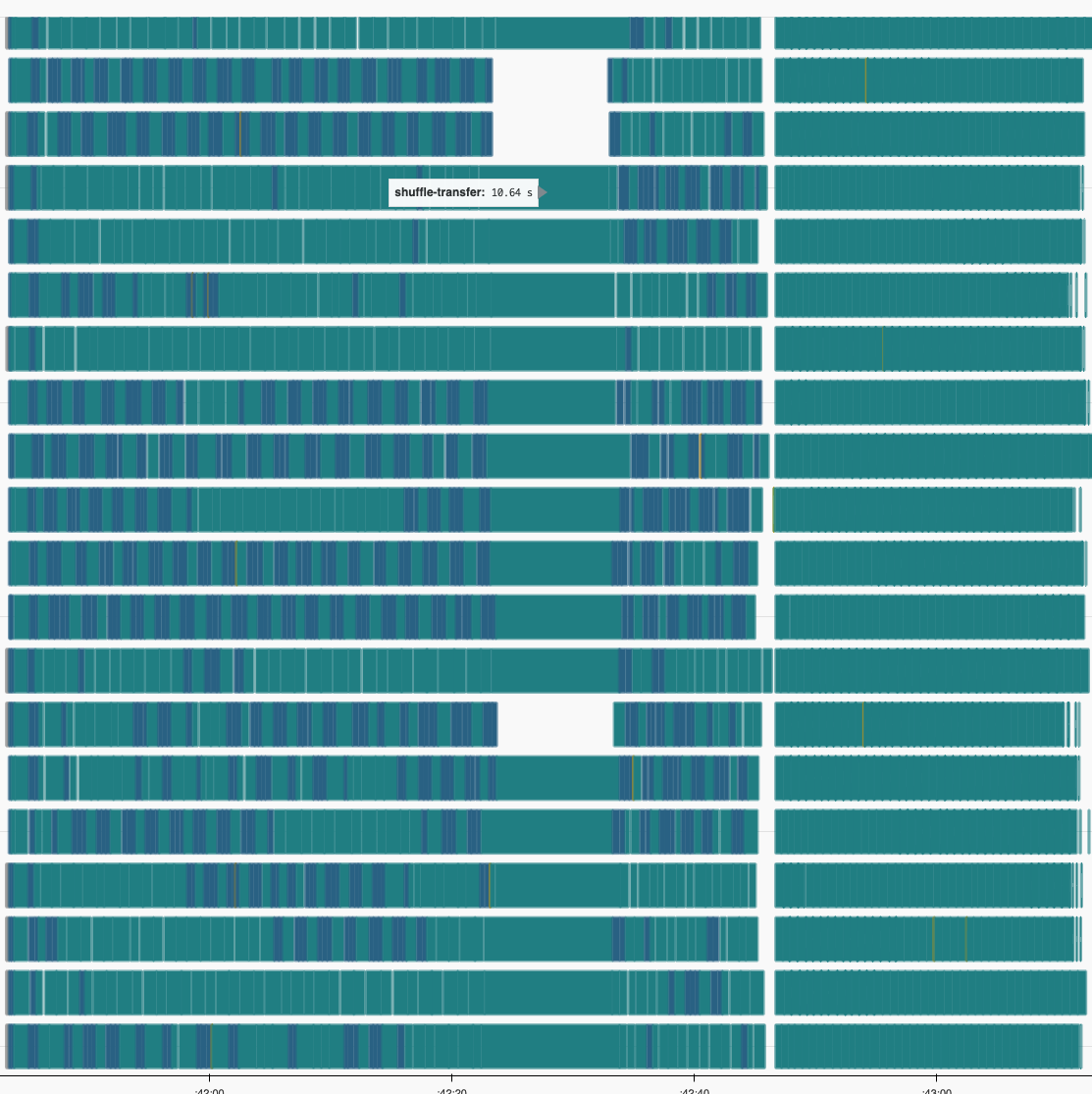
So previously IIUC, the approach was that the writes to disk are small enough that they should just block. Now though, they can be large so should be pushed onto a background task?
Does this disappear if you run |
Possibly. Even for what's on main we considered offloading this to a background task. At least when rechunking arrays this IO is non-trivial and we can see that threads are idling in io_wait
Don't know. I don't have the cluster up anymore. |
|
I spent a bit of time on this and put #7704 together. This PR is far from working properly but shows my original idea. I do realize now, though, that my approach is not necessarily about "making disk optional" but rather about an additional batching layer to reduce IO ops. FYI If you do know know about this, yet, there is also a "hidden dashboard" showing some P2P instrumentation on |
OK, makes sense. What I observe is that for writes that eventually hit the disk, with this code, the performance is reasonably unchanged from trunk: there's a reasonable speedup when things fit in memory. So in that sense the pauses just move some of the blocking around and make it more noticeable I think. When I am hitting the disk on the this branch, the overall runtime is unchanged, but the proportion of time spent in writes goes down, AFAICT. In my simple example I run with ~1000 partitions on 16 works and a total dataframe size of ~35GiB, generated with: So I am starting with the dataframe fully in memory. |
It is likely that at least some part (possibly all) of the output of the shuffle will fit in memory. In this circumstance, we don't need to necessarily write output shards to disk only to read them in later.
To enable this, provide (optional) in-memory buffering on the output DiskShardsBuffer. While the total output size is less than some limit, don't bother hitting the disk, but rather just hold in memory references. Once too much data has arrived, block to flush these buffers to disk.
When reading, we now might have some shards in memory, so we concatenate these with the on-disk buffers.
Partially addresses #7572.
pre-commit run --all-files