Replace PS-Worker mode with multi-worker one.#892
Replace PS-Worker mode with multi-worker one.#892amcadmus merged 11 commits intodeepmodeling:develfrom
Conversation
Codecov Report
@@ Coverage Diff @@
## devel #892 +/- ##
==========================================
- Coverage 73.88% 64.28% -9.61%
==========================================
Files 85 5 -80
Lines 6805 14 -6791
==========================================
- Hits 5028 9 -5019
+ Misses 1777 5 -1772 Continue to review full report at Codecov.
|

|
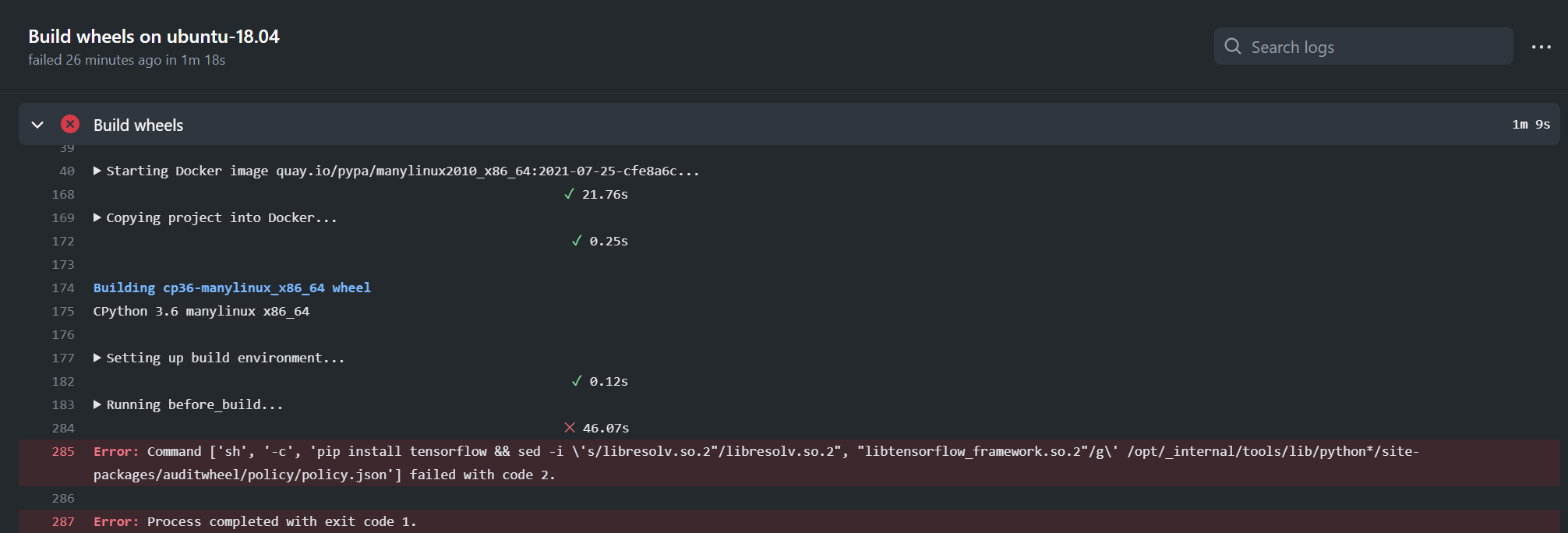
@njzjz The only failure in CI was caused by environment. Exit code 2 usually means "file not found". In this case, maybe Besides, as talked with @denghuilu yesterday, unit testes on distributed training will be added in future when CI environment is ready. |
|
This failure is fixed in #889 - you can ignore it. |
 amcadmus
left a comment
amcadmus
left a comment
There was a problem hiding this comment.
Could you please write a subsection like "distributed training" in the "train a model" section of "getting started" to introduce the users on the distributed training? Thanks!
|
@amcadmus Document is added now. |
doc/getting-started.md
Outdated
| To experience this powerful feature, please intall Horovod first. For better performance on GPU, please follow tuning steps in [Horovod on GPU](https://github.com/horovod/horovod/blob/master/docs/gpus.rst). | ||
| ```bash | ||
| # By default, MPI is used as communicator. | ||
| HOROVOD_WITHOUT_GLOO=1 HOROVOD_WITH_TENSORFLOW=1 pip3 install horovod |
There was a problem hiding this comment.
This extra requirement can be added into setup.py instead. And this may be added into installation part.
There was a problem hiding this comment.
I'm not sure whether horovod should be installed together with deepmd-kit in default. One reason is that, optimal build options can be different among cluster/host environments.
@amcadmus @denghuilu What's your options?
There was a problem hiding this comment.
I don't mean setup in default. You can add "horovod": ["horovod", "mpi4py"], here:
Lines 136 to 140 in 953621f
Then users can install with
HOROVOD_WITHOUT_GLOO=1 HOROVOD_WITH_TENSORFLOW=1 pip install .[horovod]
 denghuilu
left a comment
denghuilu
left a comment
There was a problem hiding this comment.
In the default serial training mode, the training speed indicates that the GPU device is not enabled for training, although the GPU device has been detected by TensorFlow:
root se_e2_a $ dp train input.json
2021-07-29 22:08:21.243635: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
WARNING:tensorflow:From /root/dp-devel/tensorflow_venv/lib/python3.6/site-packages/tensorflow/python/compat/v2_compat.py:96: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version.
Instructions for updating:
non-resource variables are not supported in the long term
DEEPMD INFO _____ _____ __ __ _____ _ _ _
DEEPMD INFO | __ \ | __ \ | \/ || __ \ | | (_)| |
DEEPMD INFO | | | | ___ ___ | |__) || \ / || | | | ______ | | __ _ | |_
DEEPMD INFO | | | | / _ \ / _ \| ___/ | |\/| || | | ||______|| |/ /| || __|
DEEPMD INFO | |__| || __/| __/| | | | | || |__| | | < | || |_
DEEPMD INFO |_____/ \___| \___||_| |_| |_||_____/ |_|\_\|_| \__|
DEEPMD INFO Please read and cite:
DEEPMD INFO Wang, Zhang, Han and E, Comput.Phys.Comm. 228, 178-184 (2018)
DEEPMD INFO installed to: /tmp/pip-req-build-e2bfdasy/_skbuild/linux-x86_64-3.6/cmake-install
DEEPMD INFO source : v2.0.0.b2-43-gad444c3
DEEPMD INFO source brach: devel
DEEPMD INFO source commit: ad444c3
DEEPMD INFO source commit at: 2021-07-29 21:28:37 +0800
DEEPMD INFO build float prec: double
DEEPMD INFO build with tf inc: /root/dp-devel/tensorflow_venv/lib/python3.6/site-packages/tensorflow/include;/root/dp-devel/tensorflow_venv/lib/python3.6/site-packages/tensorflow/include
DEEPMD INFO build with tf lib:
DEEPMD INFO ---Summary of the training---------------------------------------
DEEPMD INFO running on: iZ2zeedzsx4jorjze9gyq7Z
DEEPMD INFO CUDA_VISIBLE_DEVICES: unset
DEEPMD INFO num_intra_threads: 0
DEEPMD INFO num_inter_threads: 0
DEEPMD INFO -----------------------------------------------------------------
2021-07-29 22:08:22.873108: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX512F
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2021-07-29 22:08:22.874062: I tensorflow/compiler/jit/xla_gpu_device.cc:99] Not creating XLA devices, tf_xla_enable_xla_devices not set
2021-07-29 22:08:22.875101: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcuda.so.1
2021-07-29 22:08:23.548699: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-07-29 22:08:23.549803: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1720] Found device 0 with properties:
pciBusID: 0000:00:07.0 name: Tesla V100-SXM2-32GB computeCapability: 7.0
coreClock: 1.53GHz coreCount: 80 deviceMemorySize: 31.75GiB deviceMemoryBandwidth: 836.37GiB/s
2021-07-29 22:08:23.549837: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
2021-07-29 22:08:23.553827: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublas.so.11
2021-07-29 22:08:23.553948: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublasLt.so.11
2021-07-29 22:08:23.555190: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcufft.so.10
2021-07-29 22:08:23.555509: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcurand.so.10
2021-07-29 22:08:23.557718: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcusolver.so.10
2021-07-29 22:08:23.558629: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcusparse.so.11
2021-07-29 22:08:23.558829: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudnn.so.8
2021-07-29 22:08:23.558951: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-07-29 22:08:23.560063: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-07-29 22:08:23.561086: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1862] Adding visible gpu devices: 0
2021-07-29 22:08:23.561123: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
2021-07-29 22:08:24.224048: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1261] Device interconnect StreamExecutor with strength 1 edge matrix:
2021-07-29 22:08:24.224091: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1267] 0
2021-07-29 22:08:24.224101: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1280] 0: N
2021-07-29 22:08:24.224335: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-07-29 22:08:24.225467: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-07-29 22:08:24.226541: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-07-29 22:08:24.227571: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1406] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 30129 MB memory) -> physical GPU (device: 0, name: Tesla V100-SXM2-32GB, pci bus id: 0000:00:07.0, compute capability: 7.0)
DEEPMD INFO ---Summary of DataSystem: training -----------------------------------------------
DEEPMD INFO found 3 system(s):
DEEPMD INFO system natoms bch_sz n_bch prob pbc
DEEPMD INFO ../data/data_0/ 192 1 80 0.250 T
DEEPMD INFO ../data/data_1/ 192 1 160 0.500 T
DEEPMD INFO ../data/data_2/ 192 1 80 0.250 T
DEEPMD INFO --------------------------------------------------------------------------------------
DEEPMD INFO ---Summary of DataSystem: validation -----------------------------------------------
DEEPMD INFO found 1 system(s):
DEEPMD INFO system natoms bch_sz n_bch prob pbc
DEEPMD INFO ../data/data_3 192 1 80 1.000 T
DEEPMD INFO --------------------------------------------------------------------------------------
DEEPMD INFO training without frame parameter
2021-07-29 22:08:24.263356: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:196] None of the MLIR optimization passes are enabled (registered 0 passes)
2021-07-29 22:08:24.264028: I tensorflow/core/platform/profile_utils/cpu_utils.cc:112] CPU Frequency: 2499995000 Hz
DEEPMD INFO built lr
DEEPMD INFO built network
DEEPMD INFO built training
2021-07-29 22:08:28.109074: I tensorflow/compiler/jit/xla_gpu_device.cc:99] Not creating XLA devices, tf_xla_enable_xla_devices not set
2021-07-29 22:08:28.109125: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1261] Device interconnect StreamExecutor with strength 1 edge matrix:
2021-07-29 22:08:28.109134: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1267]
DEEPMD INFO initialize model from scratch
DEEPMD INFO start training at lr 1.00e-03 (== 1.00e-03), decay_step 5000, decay_rate 0.950006, final lr will be 3.51e-08
DEEPMD INFO batch 100 training time 10.11 s, testing time 0.17 s
DEEPMD INFO batch 200 training time 8.90 s, testing time 0.17 s
DEEPMD INFO batch 300 training time 8.92 s, testing time 0.17 s
DEEPMD INFO batch 400 training time 8.90 s, testing time 0.17 s
DEEPMD INFO batch 500 training time 8.88 s, testing time 0.17 s
DEEPMD INFO batch 600 training time 8.86 s, testing time 0.17 s
DEEPMD INFO batch 700 training time 8.88 s, testing time 0.17 s
DEEPMD INFO batch 800 training time 8.90 s, testing time 0.17 s
DEEPMD INFO batch 900 training time 8.86 s, testing time 0.17 s
DEEPMD INFO batch 1000 training time 8.88 s, testing time 0.17 s
By the way, when I set CUDA_VISIBLE_DEVICES manually, everything works fine:
root se_e2_a $ export CUDA_VISIBLE_DEVICES=0
root se_e2_a $ dp train input.json
2021-07-29 22:17:17.239849: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
WARNING:tensorflow:From /root/dp-devel/tensorflow_venv/lib/python3.6/site-packages/tensorflow/python/compat/v2_compat.py:96: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version.
Instructions for updating:
non-resource variables are not supported in the long term
DEEPMD INFO _____ _____ __ __ _____ _ _ _
DEEPMD INFO | __ \ | __ \ | \/ || __ \ | | (_)| |
DEEPMD INFO | | | | ___ ___ | |__) || \ / || | | | ______ | | __ _ | |_
DEEPMD INFO | | | | / _ \ / _ \| ___/ | |\/| || | | ||______|| |/ /| || __|
DEEPMD INFO | |__| || __/| __/| | | | | || |__| | | < | || |_
DEEPMD INFO |_____/ \___| \___||_| |_| |_||_____/ |_|\_\|_| \__|
DEEPMD INFO Please read and cite:
DEEPMD INFO Wang, Zhang, Han and E, Comput.Phys.Comm. 228, 178-184 (2018)
DEEPMD INFO installed to: /tmp/pip-req-build-e2bfdasy/_skbuild/linux-x86_64-3.6/cmake-install
DEEPMD INFO source : v2.0.0.b2-43-gad444c3
DEEPMD INFO source brach: devel
DEEPMD INFO source commit: ad444c3
DEEPMD INFO source commit at: 2021-07-29 21:28:37 +0800
DEEPMD INFO build float prec: double
DEEPMD INFO build with tf inc: /root/dp-devel/tensorflow_venv/lib/python3.6/site-packages/tensorflow/include;/root/dp-devel/tensorflow_venv/lib/python3.6/site-packages/tensorflow/include
DEEPMD INFO build with tf lib:
DEEPMD INFO ---Summary of the training---------------------------------------
DEEPMD INFO running on: iZ2zeedzsx4jorjze9gyq7Z
DEEPMD INFO CUDA_VISIBLE_DEVICES: ['0']
DEEPMD INFO num_intra_threads: 0
DEEPMD INFO num_inter_threads: 0
DEEPMD INFO -----------------------------------------------------------------
2021-07-29 22:17:18.880828: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX512F
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2021-07-29 22:17:18.881757: I tensorflow/compiler/jit/xla_gpu_device.cc:99] Not creating XLA devices, tf_xla_enable_xla_devices not set
2021-07-29 22:17:18.882870: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcuda.so.1
2021-07-29 22:17:19.569019: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-07-29 22:17:19.570151: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1720] Found device 0 with properties:
pciBusID: 0000:00:07.0 name: Tesla V100-SXM2-32GB computeCapability: 7.0
coreClock: 1.53GHz coreCount: 80 deviceMemorySize: 31.75GiB deviceMemoryBandwidth: 836.37GiB/s
2021-07-29 22:17:19.570188: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
2021-07-29 22:17:19.574174: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublas.so.11
2021-07-29 22:17:19.574287: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublasLt.so.11
2021-07-29 22:17:19.575548: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcufft.so.10
2021-07-29 22:17:19.575895: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcurand.so.10
2021-07-29 22:17:19.578154: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcusolver.so.10
2021-07-29 22:17:19.579071: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcusparse.so.11
2021-07-29 22:17:19.579304: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudnn.so.8
2021-07-29 22:17:19.579443: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-07-29 22:17:19.580599: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-07-29 22:17:19.581638: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1862] Adding visible gpu devices: 0
2021-07-29 22:17:19.581678: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
2021-07-29 22:17:20.230706: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1261] Device interconnect StreamExecutor with strength 1 edge matrix:
2021-07-29 22:17:20.230751: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1267] 0
2021-07-29 22:17:20.230761: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1280] 0: N
2021-07-29 22:17:20.231000: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-07-29 22:17:20.232145: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-07-29 22:17:20.233195: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-07-29 22:17:20.234241: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1406] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 30129 MB memory) -> physical GPU (device: 0, name: Tesla V100-SXM2-32GB, pci bus id: 0000:00:07.0, compute capability: 7.0)
DEEPMD INFO ---Summary of DataSystem: training -----------------------------------------------
DEEPMD INFO found 3 system(s):
DEEPMD INFO system natoms bch_sz n_bch prob pbc
DEEPMD INFO ../data/data_0/ 192 1 80 0.250 T
DEEPMD INFO ../data/data_1/ 192 1 160 0.500 T
DEEPMD INFO ../data/data_2/ 192 1 80 0.250 T
DEEPMD INFO --------------------------------------------------------------------------------------
DEEPMD INFO ---Summary of DataSystem: validation -----------------------------------------------
DEEPMD INFO found 1 system(s):
DEEPMD INFO system natoms bch_sz n_bch prob pbc
DEEPMD INFO ../data/data_3 192 1 80 1.000 T
DEEPMD INFO --------------------------------------------------------------------------------------
DEEPMD INFO training without frame parameter
2021-07-29 22:17:20.268792: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:196] None of the MLIR optimization passes are enabled (registered 0 passes)
2021-07-29 22:17:20.269495: I tensorflow/core/platform/profile_utils/cpu_utils.cc:112] CPU Frequency: 2499995000 Hz
DEEPMD INFO built lr
DEEPMD INFO built network
DEEPMD INFO built training
2021-07-29 22:17:24.066846: I tensorflow/compiler/jit/xla_gpu_device.cc:99] Not creating XLA devices, tf_xla_enable_xla_devices not set
2021-07-29 22:17:24.067087: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-07-29 22:17:24.067507: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1720] Found device 0 with properties:
pciBusID: 0000:00:07.0 name: Tesla V100-SXM2-32GB computeCapability: 7.0
coreClock: 1.53GHz coreCount: 80 deviceMemorySize: 31.75GiB deviceMemoryBandwidth: 836.37GiB/s
2021-07-29 22:17:24.067549: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
2021-07-29 22:17:24.067622: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublas.so.11
2021-07-29 22:17:24.067641: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublasLt.so.11
2021-07-29 22:17:24.067658: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcufft.so.10
2021-07-29 22:17:24.067675: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcurand.so.10
2021-07-29 22:17:24.067691: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcusolver.so.10
2021-07-29 22:17:24.067706: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcusparse.so.11
2021-07-29 22:17:24.067723: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudnn.so.8
2021-07-29 22:17:24.067798: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-07-29 22:17:24.068155: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-07-29 22:17:24.068453: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1862] Adding visible gpu devices: 0
2021-07-29 22:17:24.068487: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1261] Device interconnect StreamExecutor with strength 1 edge matrix:
2021-07-29 22:17:24.068495: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1267] 0
2021-07-29 22:17:24.068502: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1280] 0: N
2021-07-29 22:17:24.068584: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-07-29 22:17:24.068932: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-07-29 22:17:24.069243: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1406] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 30129 MB memory) -> physical GPU (device: 0, name: Tesla V100-SXM2-32GB, pci bus id: 0000:00:07.0, compute capability: 7.0)
DEEPMD INFO initialize model from scratch
DEEPMD INFO start training at lr 1.00e-03 (== 1.00e-03), decay_step 5000, decay_rate 0.950006, final lr will be 3.51e-08
2021-07-29 22:17:24.827416: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublas.so.11
2021-07-29 22:17:25.278037: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublasLt.so.11
DEEPMD INFO batch 100 training time 2.92 s, testing time 0.02 s
DEEPMD INFO batch 200 training time 1.40 s, testing time 0.02 s
DEEPMD INFO batch 300 training time 1.40 s, testing time 0.02 s
DEEPMD INFO batch 400 training time 1.41 s, testing time 0.02 s
DEEPMD INFO batch 500 training time 1.41 s, testing time 0.02 s
DEEPMD INFO batch 600 training time 1.41 s, testing time 0.02 s
DEEPMD INFO batch 700 training time 1.40 s, testing time 0.02 s
DEEPMD INFO batch 800 training time 1.40 s, testing time 0.02 s
DEEPMD INFO batch 900 training time 1.40 s, testing time 0.02 s
DEEPMD INFO batch 1000 training time 1.39 s, testing time 0.02 s
DEEPMD INFO saved checkpoint model.ckpt
|
@denghuilu Fixed by commit Let TensorFlow choose device when CUDA_VISIBLE_DEVICES is unset. When executing |
|
Now serial training can be performed correctly, but when I use two GPUs for training, an error occurs: |
|
@denghuilu I have explained in document that: It is not a good practice that run GPU program without explicit declaration of This is also the reason why I prefer not using GPU if |
denghuilu
left a comment
There was a problem hiding this comment.
I have tested the horovod training process in the CUDA environment, and there's no problem
* Replace PS-Worker mode with multi-worker one. * Remove deprecated `try_distrib` argument in tests. * Limit reference of mpi4py to logger.py. * Add tutorial on parallel training. * Refine words & tokens used. * Only limit sub sessions to CPU when distributed training. * Add description of `mpi4py` in tutorial. * Explain linear relationship between batch size and learning rate. * Fine documents & comments. * Let TensorFlow choose device when CUDA_VISIBLE_DEVICES is unset. Co-authored-by: Han Wang <amcadmus@gmail.com>
Before this pull request, DeePMD-Kit 2.0 Preview offers capability of distributed training with PS-Worker mode on tf.train.SyncReplicasOptimizer. The old implementation:
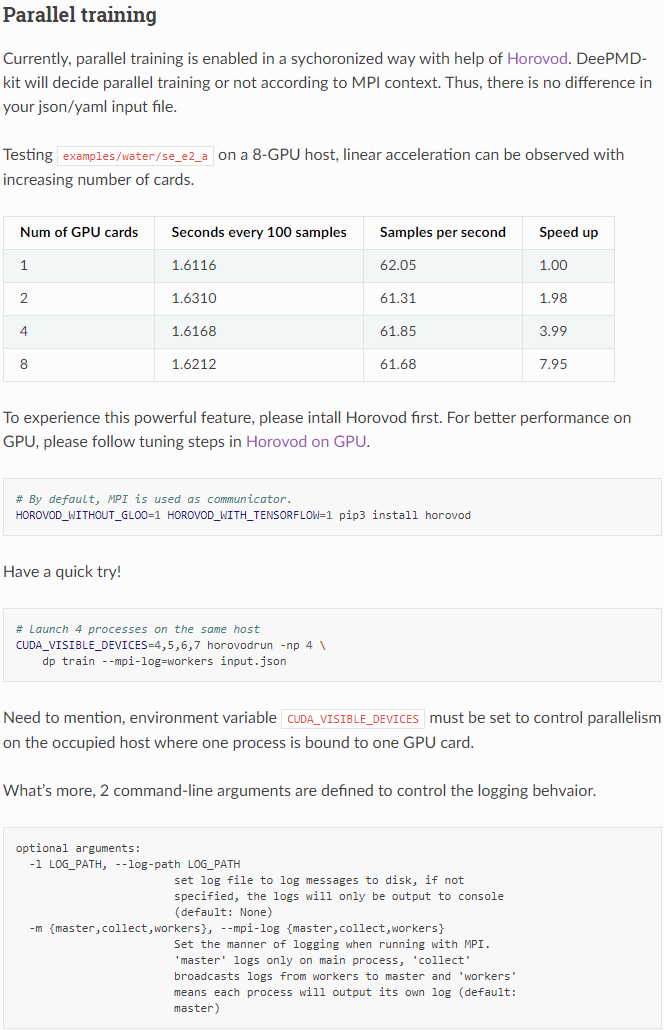
Thus, here comes a simpler but faster implentation based on Horovod. As the table shows, sample throughput of
examples/water/se_e2_ascales linearly when running on a 8-GPU host:There is no break change of user interface after this pull request. Key changes behind are:
learning_rateis scaled by the number of workers for better convergence as the global batch size is larger.descriptor,neighbor_stat,type_embeddingandinfer.*are limited to CPU device only.with_distribargument is deleted fromINPUTconfig. Instead, we decide multi-worker training or not according to MPI context.