When I train transformer architecture (encoder + decoder) with ZeRO stage 1, it shows different loss curve compared to stage 0 and stage 2.
On the other hand, the trainings with stage 0 and stage 2 look very similar.
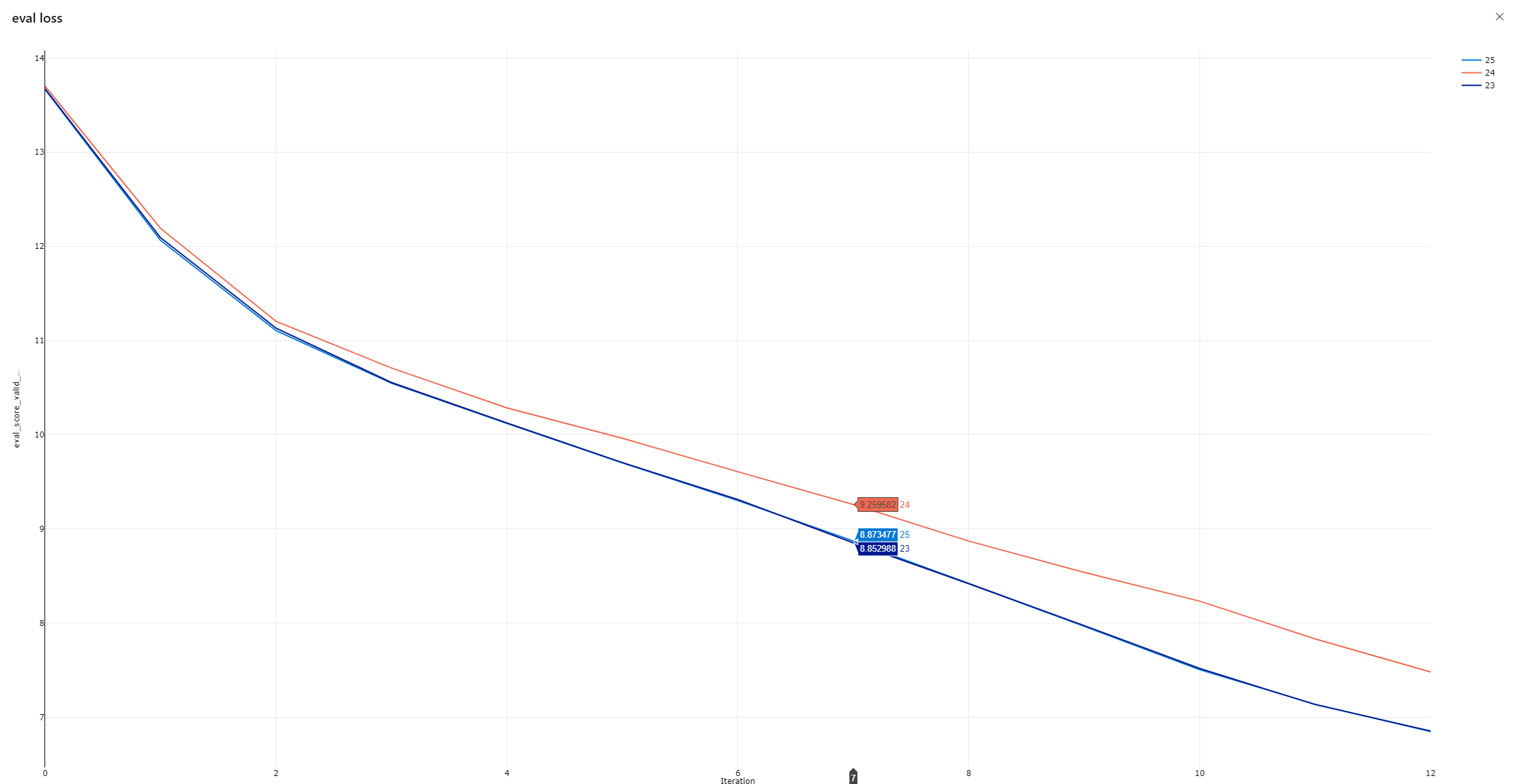
23: stage 0, 24: stage 1, 25: stage 2
When I train transformer architecture (encoder + decoder) with ZeRO stage 1, it shows different loss curve compared to stage 0 and stage 2.
On the other hand, the trainings with stage 0 and stage 2 look very similar.
23: stage 0, 24: stage 1, 25: stage 2