Improving memory utilization of Z2+MoE#2079
Merged
siddharth9820 merged 14 commits intomasterfrom Jul 13, 2022
Merged
Conversation
siddharth9820
commented
Jul 12, 2022
|
|
||
| def split_params_into_different_moe_groups_for_optimizer( | ||
| param_groups: Tuple[Dict]) -> Tuple[Dict]: | ||
| def split_params_into_different_moe_groups_for_optimizer(param_groups: Tuple[Dict], |
Contributor
Author
There was a problem hiding this comment.
@tjruwase, please let me know how we would want to offer the user a way to set the max_group_size
Contributor
There was a problem hiding this comment.
As discussed, let's add an moe section in ds_config. Perhaps, @awan-10 could help with the design.
Contributor
Author
There was a problem hiding this comment.
@awan-10 Perhaps the moe section can also contain a flag to toggle expert slicing too?
tjruwase
approved these changes
Jul 12, 2022
…nto zero2_optim_tiling
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
2 participants
Add this suggestion to a batch that can be applied as a single commit.This suggestion is invalid because no changes were made to the code.Suggestions cannot be applied while the pull request is closed.Suggestions cannot be applied while viewing a subset of changes.Only one suggestion per line can be applied in a batch.Add this suggestion to a batch that can be applied as a single commit.Applying suggestions on deleted lines is not supported.You must change the existing code in this line in order to create a valid suggestion.Outdated suggestions cannot be applied.This suggestion has been applied or marked resolved.Suggestions cannot be applied from pending reviews.Suggestions cannot be applied on multi-line comments.Suggestions cannot be applied while the pull request is queued to merge.Suggestion cannot be applied right now. Please check back later.
Summary
While running experiments, I found that an inordinate amount of memory is used in the gradient upscaling step for high expert to GPU ratios (like 1 or 1/2).
This PR does two things:
deepspeed/moe/utils.py).deepspeed/runtime/zero/stage_1_and_2.py)Highlight Result
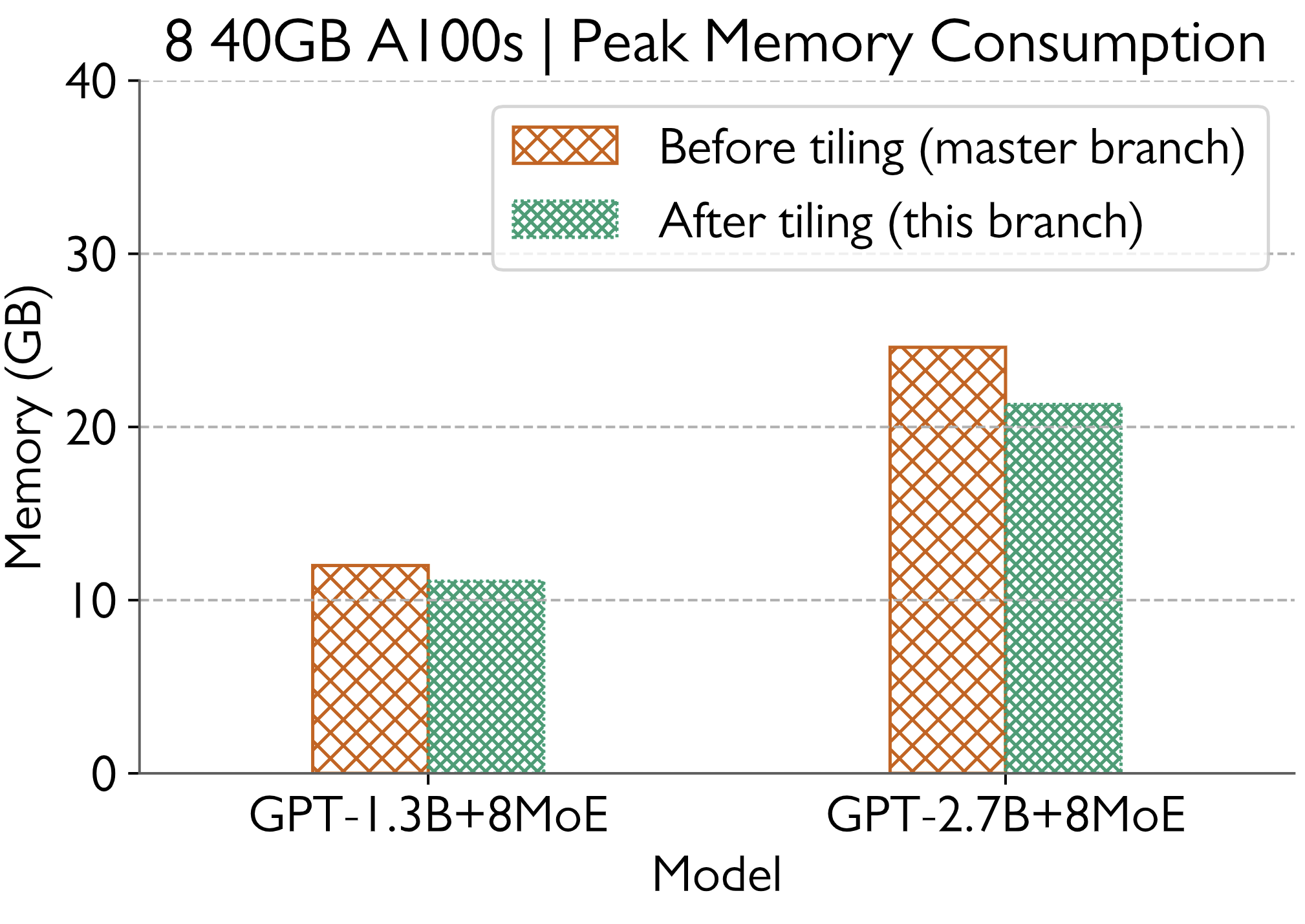
Prior to this PR a 6.7B base model with 16 experts ran OOM on 32 A100 GPUs (40GB).
With the changes, I am able to run the same model with a peak memory utilization of 31.3 GB. Thus at the bare minimum we are saving 21.75% memory for this model.
Train loss curve for reference
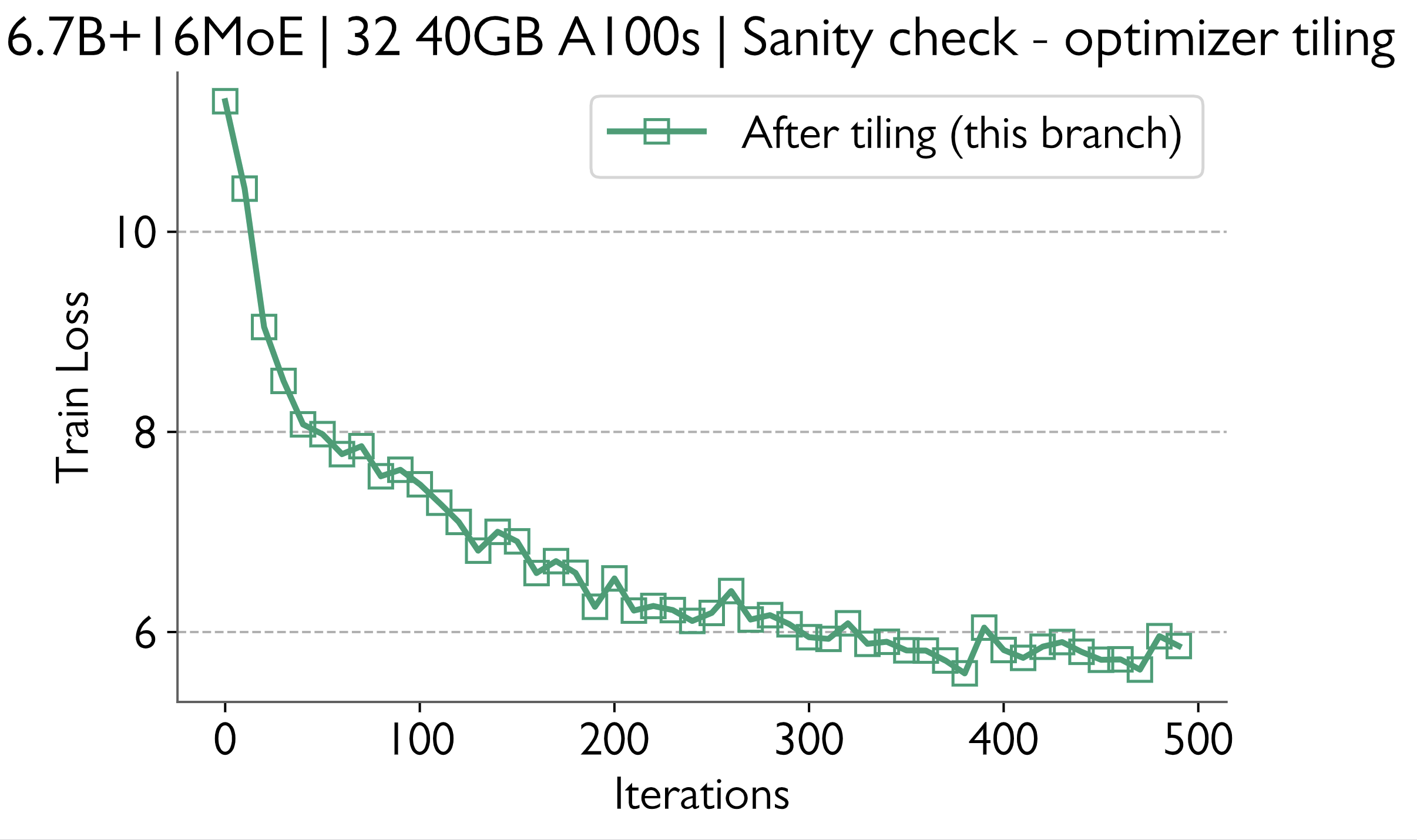
Sanity Checks
Train loss curves before and after the changes match
Batch Times
To create the most pathological case, I set global batch size to 8. Yet, there is no penalty in batch times.
Memory Consumption
The memory saved is expected to increase with increasing model sizes.