Revive #3531 - Adding support for __traits(documentation, ...)#6872
Revive #3531 - Adding support for __traits(documentation, ...)#6872wilzbach wants to merge 1 commit intodlang:masterfrom
Conversation
Since you have an implementation, why not measure the memory consumption? |
|
What would be some good use cases? One simple way to estimate the impact on memory consumption is to build phobos with and without the feature enabled, and measure time and peak memory consumption. As phobos has profuse ddoc comments, that should be toward the upper bound. If there is no significant impact (as I suspect), then that particular argument goes away. @wilzbach can you to this test? Thanks! |
Here is my use case: Here, each method represents a command-line action. I use a slightly ugly string literal UDA for the |
|
@CyberShadow cool, though one counter-argument is that cmdline help documentation has restrictions (e.g. single-line, under 70 chars or so) that actually make it more suitable as a UDA. Documentation comments are usually not subjected to such restrictions. Just to clarify the general idea: I'm generally in favor of more introspection capabilities, but each should be motivated by good applicability. |
|
@andralex just replace cmdline with GUI - i.e. one function per GUI command; hovering over a button displays the documentation in a tooltip. Another use case is named unittests. A test runner could show the name of a failing unittest with something along the lines of: foreach (test; __traits(getUnitTests, MyClass))
try
test();
catch (AssertError e)
{
static immutable summary = __traits(documentation, test);
"
+-------------------------------------
| %s
+-------------------------------------
| Summary: %s
| File: %s
| Line: %s
+-------------------------------------"
.writefln(e.msg, summary, e.file, e.line);
continue;
}Also, one could easily write a mixin statically asserts that all public functions have documentation and also that functions with non-void return types have a "Returns: ..." section, etc. |
|
One could also imagine using CTFE instead of ddoc macros for certain use cases, or even preprocessing documentation comments, mixing them again and leaving them to the standard ddoc pipeline. |
Whoa, wait. Are you saying a module could define and run a compile-time function that preprocesses some or all of the documentation in that module? That would be solid! |
|
Yes, exactly my idea, though I haven't tried it yet. |
|
I tried the following function: import std.algorithm, std.range, std.format, std.meta, std.traits;
enum stringOf(T) = T.stringof;
enum sizeOf(T) = T.sizeof;
string makeDdoc(alias f)(string summary)
{
return format(
"
/**
* %s
*
* Params:
%-(%s\n%)
*/",
summary,
[ ParameterIdentifierTuple!f ]
.zip([ staticMap!(stringOf, Parameters!f) ], [ staticMap!(sizeOf, Parameters!f) ])
.map!(x => " * %s = A parameter of type `%s`, size %s.".format(x[0], x[1], x[2]))
);
}That when applied to a function void fun(short x, float y, double z);
makeDdoc!fun("This is a great function.")Yields: /**
* This is a great function.
*
* Params:
* x = A parameter of type `short`, size 2.
* y = A parameter of type `float`, size 4.
* z = A parameter of type `double`, size 8.
*/However, when I mixed in the documentation in front of the function like so: mixin (makeDdoc!fun("This is a great function."));
void fun(short x, float y, double z);And ran the following command: dmd -D test.dI got: Which confirmed my expectation that ddoc parsing doesn't take into account mixins. |

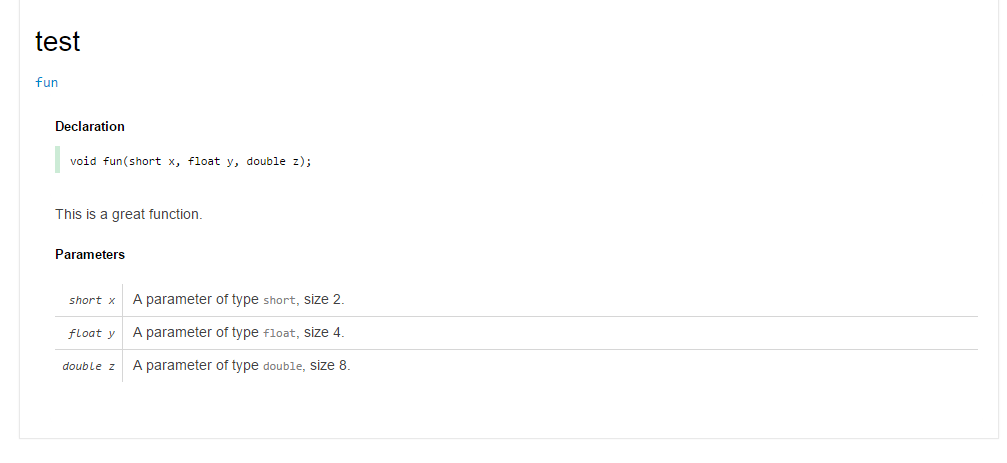
|
I'd say this PR would be a lot more valuable if it afforded users the ability to preprocess ddoc comments. |
|
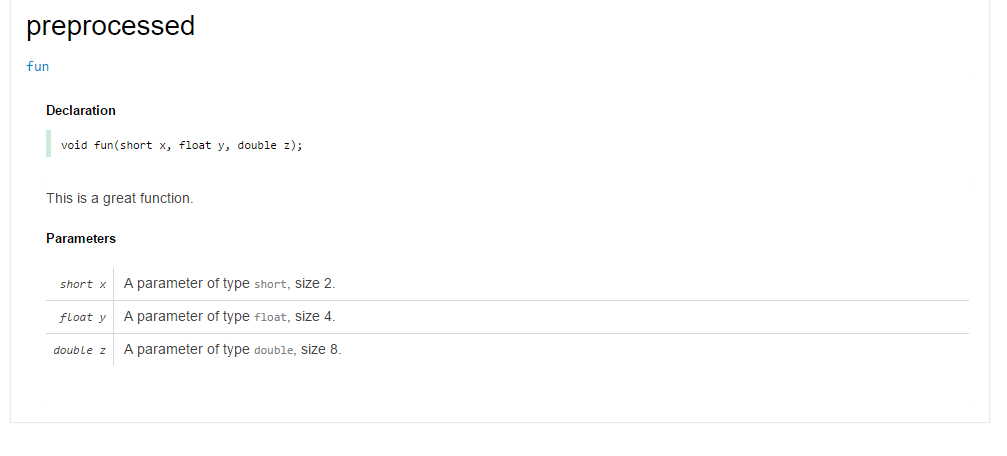
On second thought, I don't think we need much more than more than dmd -o- test.d 2> preprocessed.d && dmd -o- -Dftest.html -D preprocessed.d && rm preprocessed.d
import std.algorithm, std.array, std.range, std.format, std.meta, std.traits;
enum stringOf(T) = T.stringof;
enum sizeOf(T) = T.sizeof;
string makeDdoc(alias f)(string summary)
{
return format(
"
/**
* %s
*
* Params:
%-(%s\n%)
*/
%s;",
summary,
[ ParameterIdentifierTuple!f ]
.zip([ staticMap!(stringOf, Parameters!f) ], [ staticMap!(sizeOf, Parameters!f) ])
.map!(x => " * %s = A parameter of type `%s`, size %s.".format(x[0], x[1], x[2])),
typeof(&f).stringof.replace("function", __traits(identifier, f))
);
}
pragma (msg, makeDdoc!fun("This is a great function."));
void fun(short x, float y, double z);test.html:
Replacing the |
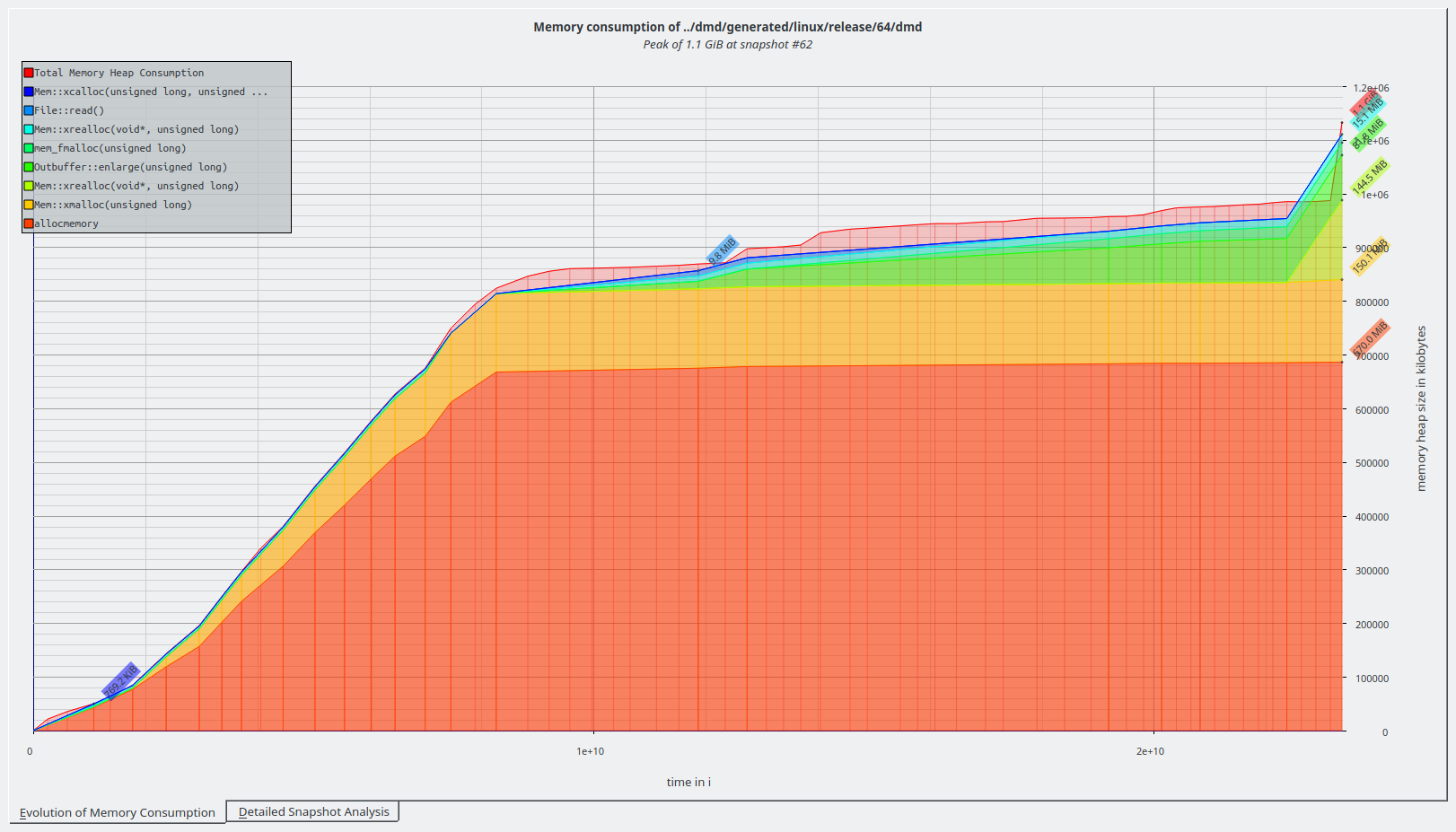
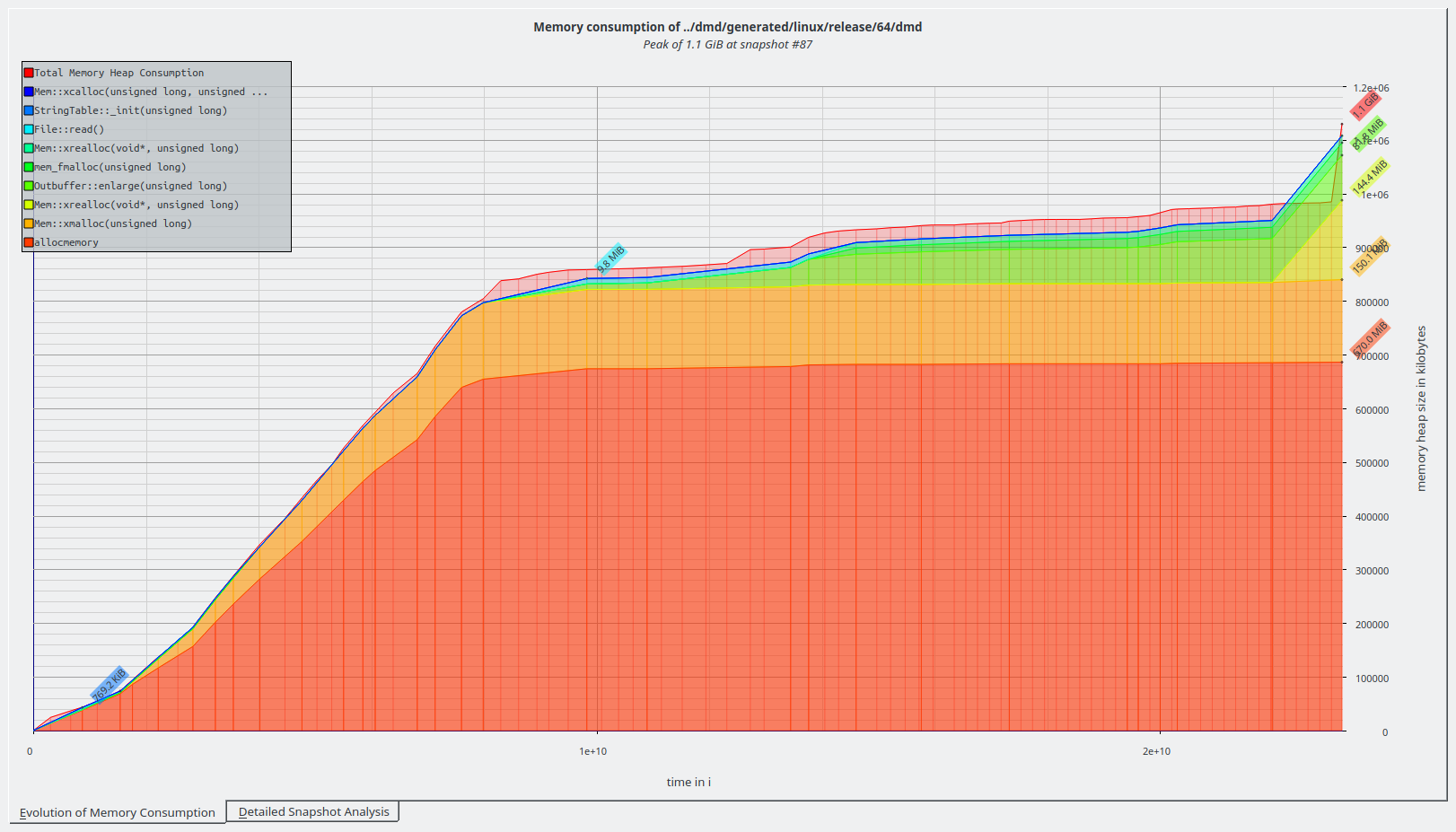
So we allocate 2.75 MB more at the peak, which imho would be neglectable considering that the peak is at 1.1 GB. With
|

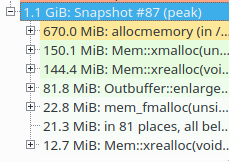
|
Yah, the increase in build time is measurable. My main problem is we're lacking a killer use case for this. In fact the converse may be more useful: make the body of a enum or function available to ddoc. Then you can click on a "+" to expand it inline. |
Please don't let us develop no features for Ddoc - this is far easier with Ddox. So what other options do we have?
|
|
I'd say keep it on the back burner until we find a couple of good ideas for using it. Discussing it in the forum may help. |
-> http://forum.dlang.org/post/cwjtsmnwwwwepvgvlqcy@forum.dlang.org |
|
I like cybershadow's use case - loading the documentation comment is really nice for command line things. Column limits are a simple case of authoring and word-wrapping; trivial, no need to separate and duplicate the text. As to preprocessing docs... no, bad idea. That'd be something the alternative doc parsers can't really duplicate and would make the docs likely less readable in source code. That's a net negative value. |
|
One usecase I would add is compile time generation of the OpenAPI documentation of REST API (ie using vibe-d) - see https://swagger.io/ |
|
Although I cannot see a immediate usecase, I will say that at this introducing memory problems is no concern. |
|
Putting this in the Phantom Zone due it needing a compelling use case(s) to justify consuming memory and compilation time. |
So I took the liberty to revive #3531, but unfortunately there hasn't been a clear consensus on how to move forward. The most important bits from the discussion:
The discussion circled around adding a special flag for this as
-Dalways produces an html file.I share this opinion, but I wanted to wait on feedback before investing more work on this PR (same for adding more tests).
The PR to dlang.org is still open.
So three years later, what's your opinion on being able to query DDoc comments during CTFE?