[Discussion] mark Seq.iter inline #3670
Conversation
|
For completeness sake, this compares #3662 against the latest FSharp.Compiler.Tools nuget fsc: https://gist.github.com/0x53A/bbc37d5d3c642d1a9d4a459f2598fd27 My pr improves the performance by 10%. I didn't implement the erasure for Seq.iter, only for List.iter, so it can't really be compared to the benchmarks in the first post. |
|
With regards to the debuggability, you can move up the call stack to see the other locals. |
|
Yes that's exactly what he wanted to avoid
|
|
What about functions with lot's of code in the function body and / or non performance critical code? Some hotspot cases you'll need the inline version, other non hotspot cases you'll need the non inlined version. There are no universal solution. How about providing multiple modules with different inlining level? Specialization will be easy with local module alias or aliases (if you want mix inline/noinline as you need), and you can start the specialization step by step basis for every hotspot. Something like this: module FooOperations = begin
// generic code
[<MethodImpl(MethodImplOptions.AggressiveInlining)>]
let inline bar x = x + 1
end
module FooNoInlining = begin
[<MethodImpl(MethodImplOptions.NoInlining)>]
let bar x = FooOperations.bar x
end
module Foo = begin
let bar x = FooOperations.bar x
end
module FooInlining = begin
let inline bar x = FooOperations.bar x
end
module FooAggressiveInlining = begin
[<MethodImpl(MethodImplOptions.AggressiveInlining)>]
let bar x = FooOperations.bar x
end
Example usage1: module F = Foo
module FI = FooAggressiveInlining
let testF() =
F.bar 1
let testFI() =
FI.bar 1
Please note: the AggressiveInlining will change the JIT inlining behaviour - the code will inlined even if exceed the inlining size limit in the JIT. |
Yes, for Debug code I'd image that's the case.
Again I'd prefer a set of orthogonal decision/optimizations/choices that would work for all code, including user-defined code, rather than just one function in the library. So let's take a look if Now nrmally we don't do lambda-propagation of
when encountering
Yes. |
|
So, three tasks:
The last one is probably the most important - in my example in Release mode, the lambda was inlined, but I couldn't even set a breakpoint. I will take another stab at this, but as always, it may be a while ;) Thanks!
I still think small targeted semantic optimizations like the seq.map fusion would make sense in the absence of staging. |
Hmmm.. I think (not sure) this should "just happen". Debug information gets erased from the implementation of the iteration, but not the lambda. So I think we should just get sequence points in the lambda as expected. But I'm still not sure what debug experience that will give on stepping, and it might depend where the lambda is used in the body of the implementation |
|
@dotnet-bot test this please |
|
I think the result of the discussion was that yes, marking these functions as inline would be a positive change. It's just that someone has to do it, and I haven't yet, and probably won't the next few weeks / months. I'd close this - if someone other wants to implement it, then great, otherwise I may reopen later. |
Program Code: https://gist.github.com/0x53A/9da43cb0f7c42f1b629b888fe7a68224
(for the inline version I inlined
let iter action (source : seq<'T>) =)This code was compiled into a release console exe.
TargetFW: net461
TargetRuntime: I have Win10CU with net47
Size:
Speed:
"Benchmark" Program:
As you can see, the x64 is always faster than the 32bit. The results have a lot of jitter, but the inline version is most of the time faster.
I also created a "real" benchmark using BenchmarkDotNet: https://gist.github.com/0x53A/320abe9890af709c510f02abdabd410a
Debuggability:
This one was a bit disappointing:
Debug:
Well,
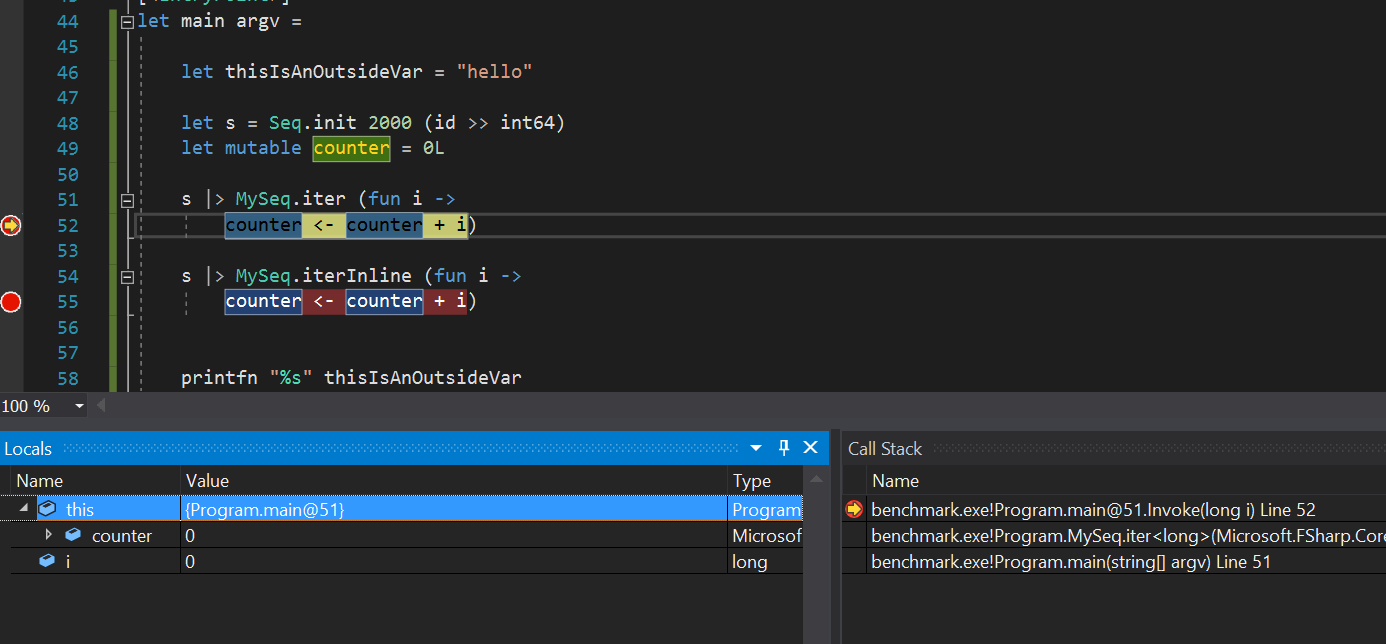
iand the closure are visible, as expected:This is a bit disappointing, the call to
iterwas inlined, but the lambda was not erased, so I am still inside theInvokeand the outside variables are not visible:Release:
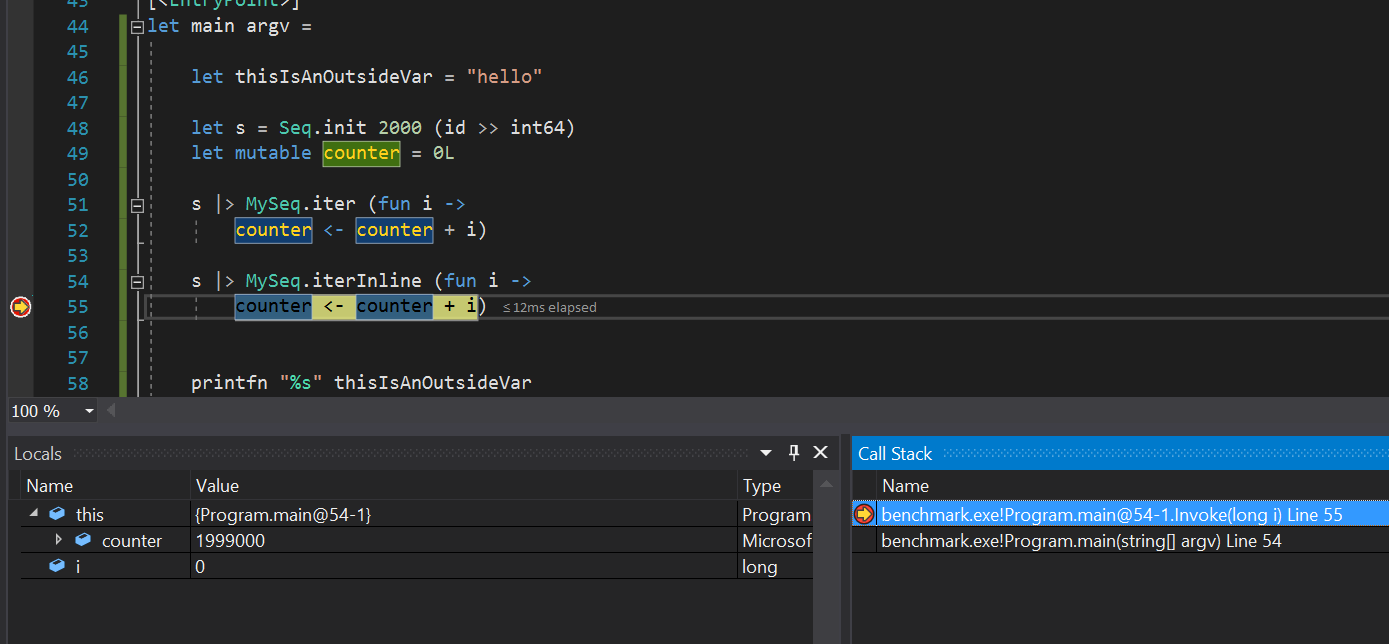
I couldn't even set a breakpoint into the callback for
iterInline...Conclusion:
Inlining improves performance, but does not improve debugability. I would still prefer to explicitly erase *.iter to a for loop, because that one also erases the lambda into the outer scope.
Now my question is: Which functions should all be inlined?
I strongly assume that any benchmarks for List.iter and Array.iter would give similar results. What about iteri? What about Option.[map/iter/forall]?
It is my strong guess that all functions with a small body that accept a callback would benefit a lot from this. For small functions that don't accept a callback, it is probably not so clear-cut.