Hash the AssertionDsc struct for faster lookup #72700
Conversation
|
Tagging subscribers to this area: @JulieLeeMSFT, @jakobbotsch Issue DetailsCreate a hash table to store the mapping of Fixes: #10592
|
c72cf71 to
1e57b63
Compare
|
Some thoughts:
|
I did some instrumentation which is not exactly similar to what you had. Here is how I instrumented it. I have added instrumentation for the 5 types of lookups we do today: With that instrumentation, I ran superpmi benchmarks, libraries.pmi and asp.net. benchmarks
And here is graph that maps number of methods (Y-axis) to the number of iterations / match.
libraries.pmi
asp
Essentially, if I am interpreting the data correctly, there is not much benefit in hashing other categories for faster lookup other than I have not instrumented the places where we iterate through all the assertions and try to find the best matching assertion (e.g.
There is some noise, but overall I see improvements. Below are the results of running superpmi 5 times on handful of method contexts that has high assertion count/iteration (last 2 columns).
If you think this instrumentation will be helpful in future, I can send a PR for the existing instrumentation I have done in kunalspathak@b549c14.
I do see 13 entries sometimes...let me try to narrow down.
I think |
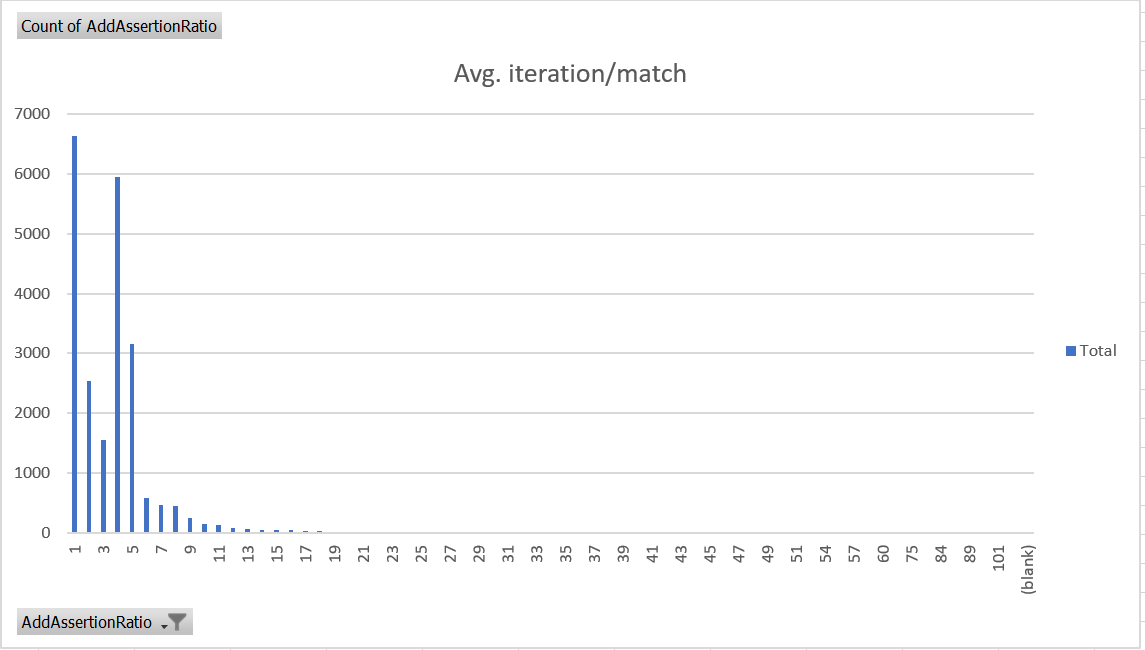

In benchmark superpmi, I see 3-4 methods that has 13 entries, but number of iterations we did for the match was 18497 and found 122 matches, so roughly 150ish iterations to find a match. So, I guess something < 15 still looks good. |
In addition to that, we are essentially scanning through bunch of Here is the data for
Here are the numbers for
|
I'm not sure I fully understand what you are measuring. Is this right? Seems like good metrics would be
The interesting cases to me are the non- |
That's right.
That's right.
Yes, I realized that I should include these two and will do it today.
Agree. |
|
Here is the aggregated information for benchmarks collection collected on windows/x64 using kunalspathak@f98c74b and sorted by the call count.
Observations:
|
|
I am inclined to merge this as is and I will have follow-up PRs for:
|
|
@dotnet/jit-contrib |
|
spmi asmdiffs and replay errors are related to re-publishing the log files. |
bb165aa to
5195133
Compare
|
@dotnet/jit-contrib |
| if (optAssertionDscMap->Set(*newAssertion, optAssertionCount + 1, AssertionDscMap::SetKind::SkipIfExist, | ||
| &fastAnswer)) |
There was a problem hiding this comment.
It is not obvious - why do we need SetKind::SkipIfExist if we have LookupPointer?
There was a problem hiding this comment.
Because you will call the GetHashCode() twice, first through LookupPointer and then during Set. With SkipIfExist, you just call it once.
|
SPMI doesn't see this as a TP win. Are there reasons to believe this is not accurate? |
Not sure what the noise range is, but I agree that for this PR, we should expect to at least show some TP improvements. I will think about it. |
The instrumentation is very precise. |
Thanks for reminding that. In that case, it could be that the hash function itself is expensive or time is consumed in traversing the chain. |
|
FWIW, I would also expect some slowdowns from the introduced copying of |
|
I will close this PR for now and get to it when I get time. |
Create a hash table to store the mapping of
AssertionDsctoAssertionIndex.Design:
vnBasedis passed around inEquals()method ofAssertionDsc, it was not possible to use it in HashTable'sKeyFuncstype. I tried various approaches like createing template, function pointers, inheritance, etc. but none of them solved the problem. In the end, I have just included thebool vnBasedinAssertionDsc. Although this field value is redundant since this is already stored onCompilerobjectand it does increase the size ofI also tried to have a static field overAssertionDscfrom 48 bytes to 56 bytes. However, most popular maximum size ofAssertionDscis 64, we end up taking 512 bytes extra during jitting per method.AssertionDscKeyFuncsbut there was a worry that if multiple methods are being compiled at the same time, the value ofvnBasedmight get outdated for one of the thread.Fixes: #10592