[RFC] Rebalance compression levels#2692
Conversation
|
Thanks for this rebalancing @senhuang42 , which already looks like a nice improvement. I agree that the main issue is that compression speed (and ratio) plateau'd at level 11, leaving a bit gap with level 13. I'm wondering if this speed limitation is related to maximum row size. Finally, any potential opportunity to bring level 4 to |
Yeah, I think this is something definitely worth taking a look at (though it would require additional refactoring of the rowhash code to support 64-entry rows), though I'm not sure by how much it can improve ratio since
|
bac275b to
6140a64
Compare
|
I've added support for 64-row entries in order to further assist the rebalancing effort. Now, the compression ratio gap between max Note that this PR is now rebased on top of #2681. The idea is to get #2681 merged first, then we can make further adjustments to how the 64-entry rows are integrated in this PR, after the adjustments/refactors to some rowhash internal APIs in #2681 are merged. So as of now, the code that adds 64-entry in this PR is just a WIP and exists just to have a working version. >256K: <=256K: <=128K: |
7a58f13 to
746ac8d
Compare
| #define ZSTD_ROW_HASH_CACHE_MASK (ZSTD_ROW_HASH_CACHE_SIZE - 1) | ||
|
|
||
| typedef U32 ZSTD_VecMask; /* Clarifies when we are interacting with a U32 representing a mask of matches */ | ||
| typedef U64 ZSTD_VecMask; /* Clarifies when we are interacting with a U64 representing a mask of matches */ |
There was a problem hiding this comment.
what is the performance impact on 32-bit builds?
There was a problem hiding this comment.
Something like a ~15% regression.
rebalanced 32-bit:
5#silesia.tar : 211957760 -> 62473463 (3.393), 72.5 MB/s , 596.1 MB/s
6#silesia.tar : 211957760 -> 61461315 (3.449), 61.0 MB/s , 596.9 MB/s
7#silesia.tar : 211957760 -> 60459438 (3.506), 47.6 MB/s , 629.6 MB/s
8#silesia.tar : 211957760 -> 59989973 (3.533), 38.0 MB/s , 638.0 MB/s
9#silesia.tar : 211957760 -> 59707605 (3.550), 35.9 MB/s , 644.7 MB/s
10#silesia.tar : 211957760 -> 59157938 (3.583), 33.5 MB/s , 644.0 MB/s
11#silesia.tar : 211957760 -> 58644580 (3.614), 25.3 MB/s , 652.9 MB/s
12#silesia.tar : 211957760 -> 58243087 (3.639), 18.6 MB/s , 660.0 MB/s
dev 32-bit with same params:
5#silesia.tar : 211957760 -> 62473463 (3.393), 78.8 MB/s , 593.5 MB/s
6#silesia.tar : 211957760 -> 61461315 (3.449), 70.1 MB/s , 594.7 MB/s
7#silesia.tar : 211957760 -> 60459438 (3.506), 52.9 MB/s , 627.3 MB/s
8#silesia.tar : 211957760 -> 59989973 (3.533), 48.0 MB/s , 635.8 MB/s
9#silesia.tar : 211957760 -> 59707605 (3.550), 42.4 MB/s , 642.4 MB/s
10#silesia.tar : 211957760 -> 59157938 (3.583), 39.6 MB/s , 641.8 MB/s
11#silesia.tar : 211957760 -> 58644580 (3.614), 31.8 MB/s , 650.4 MB/s
12-silesia.tar : 211957760 -> 58644580 (3.614), 31.6 MB/s , 650.6 MB/s
There was a problem hiding this comment.
I don't care about 32-bit builds... but branching on rowEntries in ZSTD_VecMask_next() would probably recover most performance in the 16/32 bits case. In the 64-bits case, on 32-bit platforms, it would be faster to process each each 32-bit half separately (which doesn’t really fit with the current ZSTD_VecMask_next() abstraction).
There was a problem hiding this comment.
matches &= (matches - 1) could be pull into its own function ... that branches on rowEntries and sizeof(size_t)
746ac8d to
16cbec0
Compare
9fede99 to
3c7fb73
Compare
|
Whats the status of this PR? |
Added the minor optimization for 32-bit mode, level 5 |
5f8eb43 to
a94fd1c
Compare
a94fd1c to
e28c257
Compare
e28c257 to
539b3aa
Compare
|
Unfortunately this rebalancing causes a massive performance "regression" on HTML/XML/JSON and other text files with good compressible data (due to repeatable structure, tags, etc) by marginal increase of compression ratio. + $ _x64-before-gh-2692/zstd --long -b5 -e12 -i5s -T0 dblp.xml
- $ _x64--after-gh-2692/zstd --long -b5 -e12 -i5s -T0 dblp.xml
+ 5#dblp.xml : 131 MiB -> 21.0 MiB (6.240), 284.2 MB/s, 1259.1 MB/s
- 5#dblp.xml : 131 MiB -> 20.4 MiB (6.438), 264.7 MB/s, 1313.9 MB/s | -7.37%
+ 6#dblp.xml : 131 MiB -> 20.4 MiB (6.439), 270.7 MB/s, 1268.1 MB/s
- 6#dblp.xml : 131 MiB -> 19.8 MiB (6.624), 164.9 MB/s, 1305.3 MB/s | -64.16%
+ 7#dblp.xml : 131 MiB -> 19.6 MiB (6.708), 230.1 MB/s, 1381.4 MB/s
- 7#dblp.xml : 131 MiB -> 19.2 MiB (6.821), 183.0 MB/s, 1397.5 MB/s | -25.74%
+ 8#dblp.xml : 131 MiB -> 19.3 MiB (6.792), 190.1 MB/s, 1418.5 MB/s
- 8#dblp.xml : 131 MiB -> 19.0 MiB (6.887), 137.7 MB/s, 1409.0 MB/s | -38.05%
+ 9#dblp.xml : 131 MiB -> 19.0 MiB (6.901), 153.1 MB/s, 1439.7 MB/s
- 9#dblp.xml : 131 MiB -> 18.7 MiB (7.027), 133.0 MB/s, 1357.8 MB/s | -15.11%
+ 10#dblp.xml : 131 MiB -> 18.7 MiB (7.027), 133.7 MB/s, 1338.6 MB/s
- 10#dblp.xml : 131 MiB -> 18.4 MiB (7.147), 117.2 MB/s, 1259.0 MB/s | -14.08%
+ 11#dblp.xml : 131 MiB -> 18.4 MiB (7.147), 117.7 MB/s, 1254.1 MB/s
- 11#dblp.xml : 131 MiB -> 18.1 MiB (7.232), 86.6 MB/s, 1261.8 MB/s | -35.91%
+ 12#dblp.xml : 131 MiB -> 18.1 MiB (7.232), 87.6 MB/s, 1263.7 MB/s
- 12#dblp.xml : 131 MiB -> 18.0 MiB (7.300), 57.9 MB/s, 1275.6 MB/s | -51.30% Especially with level 6 and 12 it is more than 50% slower now. + $ _x64-before-gh-2692/zstd --long -b6,12 -i3s -T1 dblp.xml
- $ _x64--after-gh-2692/zstd --long -b6,12 -i3s -T1 dblp.xml
+ 6#dblp.xml : 131 MiB -> 20.1 MiB (6.531), 108.7 MB/s, 1178.9 MB/s
- 6#dblp.xml : 131 MiB -> 19.3 MiB (6.798), 77.0 MB/s, 1107.1 MB/s | -41.17%
+ 12#dblp.xml : 131 MiB -> 17.5 MiB (7.487), 34.5 MB/s, 1211.3 MB/s
- 12#dblp.xml : 131 MiB -> 17.4 MiB (7.547), 24.2 MB/s, 1217.9 MB/s | -42.56%
# without `--long`:
+ $ _x64-before-gh-2692/zstd -b12 -i3s -T1 dblp.xml
- $ _x64--after-gh-2692/zstd -b12 -i3s -T1 dblp.xml
+ 12#dblp.xml : 131 MiB -> 18.5 MiB (7.108), 39.9 MB/s, 1318.1 MB/s
- 12#dblp.xml : 131 MiB -> 18.3 MiB (7.173), 26.6 MB/s, 1289.1 MB/s | -50.00% |
|
For inter-version speed comparison, prefer comparing current
If the speed is not fast enough, just lessen the compression level, typically by one notch. I don't have your file to reproduce exactly, but we do have
As can be seen |
Well, related to my tests this PR introduced still more worse "anomaly" than 1.5.0... Please take a careful look at level 5 - 8 in my excerpt above.
Here you go - https://dblp.org/xml/release/ (I used an excerpt of 130MB).
Sure... just exactly this types of files need often a good speed (by fewer interesting ratio, because it doesn't change too fast or as you correctly said entering the "plateau" faster than other files). Option |
|
That's interesting. I've benchmarked the first 2709MB of the dblp.xml corpus with the following results. So at least in my benchmarking, I'm seeing that the new level 6 is equivalent to the old level 7 in compressibility but faster. And the new level 7 is better in compressibility than the old level 7 at a just slightly slower speed. Indeed, we still don't have a perfectly smooth transition from levels 4 to 5, but that is sort of the step-function price you pay for switching to an entirely new algorithm. And of course, the file you are benchmarking itself matters a lot too in how the curve looks - we tune ours based off of common corpuses like Also, the new level 11 is almost identical to the old level 12, so if you desire that exact compressibility/speed tradeoff, use 11 instead of 12. The new 12 is just stronger than the old one.
If your use-case absolutely required this ability to hit these exact speeds, then that would push it into an "advanced scenario" where it makes sense to use a more customized query. In that case, you could use the |
But also you see a large distance between new and old levels regarding the compression speed. Anyway the difference between CR 6.3 and 6.1 is almost to neglect (it is ca 4% in target size), whereas the difference in speed 121.4 vs 184.1 MB/s is significant (more than 50%). And a switch to level 4 is not an option, because the resulting CR "degradation" would be also substantial.
Sure, and I have been well aware of it, therefore I tried max-possible
It was not about what I can try, but which characteristic values zstd would get by default. I know what I could do here.
|
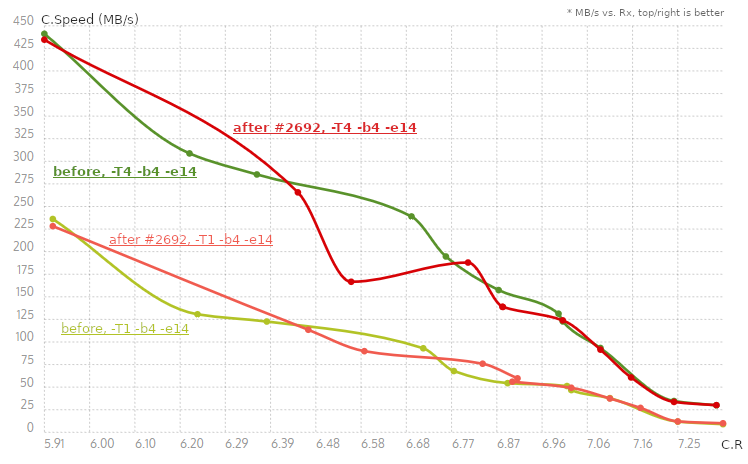
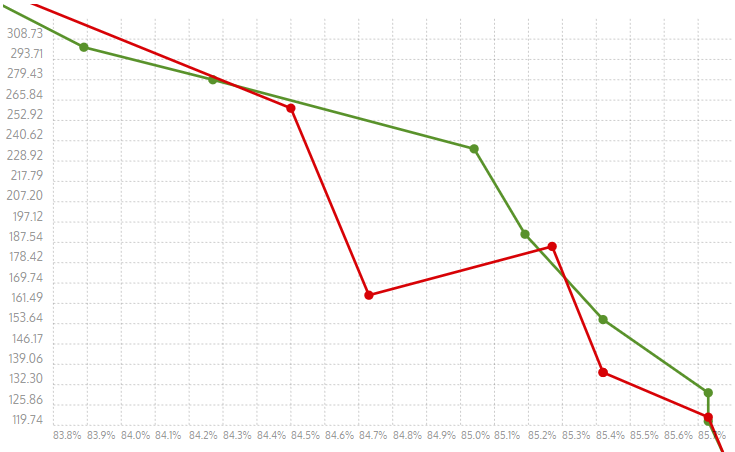
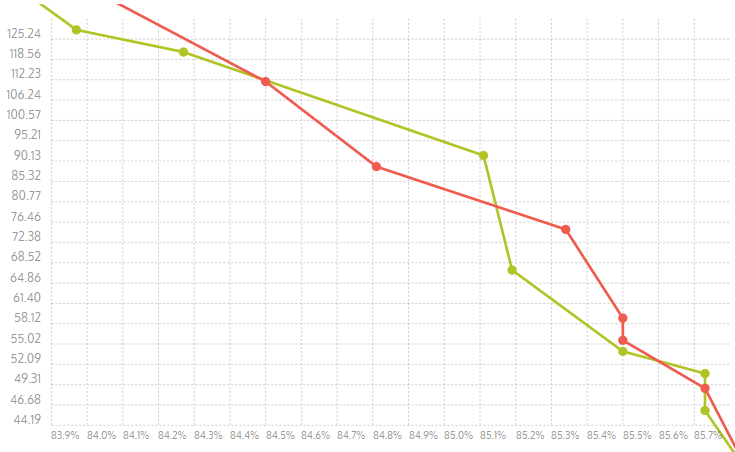
First, I appreciate the chart in visualizing the differences. It's definitely helpful and presents the findings in an easily digestible way. However, I still can't reproduce level 7 being faster than 6. And yes, in this particular case, we see that the cliff is larger. You make really great points about all the issues regarding the cliff, and maybe we should take a closer look at corpuses with more structured data. But also consider that all this is happening on this particular file. The search and matchfinding algorithm is entirely different between levels 4 and 5. We can make a best effort on trying to smooth out the difference, but it's impossible to maintain the exact same "cliff magnitude" across very different file classes.
If this is your main concern, rather than trying to get a specific performance profile for your specific use-case, then I think we also must necessarily expand this discussion beyond the scope of this single file since we're talking at a larger scope now. So compared to 1.4.9 in general, the cliff from 4->5 is still smaller, and compression ratio is a lot better. Compared to prior to this PR, the cliff is a tiny bit larger, but compression ratio is better. Consider clevels as speed targets - the purpose of this PR was to bring 1.5.0 zstd more in line with the 1.4.9 speed targets, so slowing down 5 in favor of more compression ratio brings zstd more in line with that goal.
Definitely, using
Yeah, that makes sense - And it appears that on this file in particular, having more searches is particularly costly without as much benefit. |
Hmm... how you compile it? I used gcc 11.1 with Anyway I'll try to reproduce this with other files as well as to make more tests (also with |
|
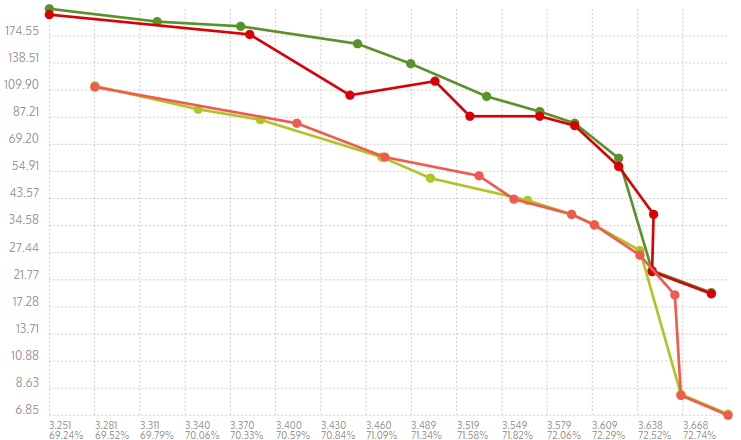
Here are the results with the charts for Results for
|
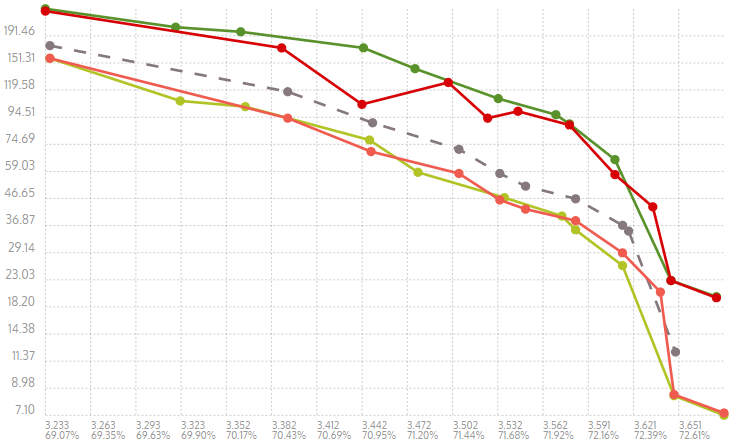
the calculation of rowLog in e411040 was implemented not correctly - it was always 4 no matter how large `slog` is, now it is [4 .. 6] depending on `slog`
the calculation of rowLog in e411040 was implemented not correctly - it was growing not restricted with the `slog`, now it is [4 .. 6] depending on `slog`
|
Thanks for the benchmarks!
Finally: |
Regarding ultimate results, sure, you are right... But for interim tests it is almost to neglect as long as the results are reasonably stable with a small measurement error (e. g. l.4 values - 241/238 shows 1%, which is surely acceptable tolerance and 158/157 is even 0.5%), especially if it is repeated many times with the same tendency.
Yes, just a rebalance of parameters showing previously good characteristics in single- and multi-threaded modes to some new values with a known degradation of multithreaded performance will be not reasonable probably, is it? By the way, would it be advisable to introduce some additional rules or another variant of
Well, one difference to me (i5-6500) would be the CPU cache size - 6MB (i5) vs. 16MB (i9). Larger CPU cache means fewer cache-misses and washouts, fewer cache refreshes on inter-threaded change due to larger amount of pages in TLB, etc. Typically it results in less frequent memory access, but in other case inappropriate parameter could cause that
We speak about defaults all the time, so let us concentrate on this, please.
I'm not in mode to find an optimal way for Chart for
|
|
I presume you are looking for "regularity" on the horizontal axis, which is more natural to read. Regarding level 4, the distance with this level is big because level 4 is a bit "too fast". We would preferably have a slower yet more powerful level 4, but we were unable to find good parameters for this specific speed range. Level 4 is essentially a "souped up" level 3, consuming more memory, which ends up being a little slower and stronger, but nowhere near the distance we would ideally want level 4 to be. When a better setup will exist, it will take this spot. In the meantime, we do what we can with what we have. |
No. Basically I was confused by speed regression bothering me on several level, hereafter I noticed that levels are not normally distributed across the speed axis (no matter vertical or horizontal). Moreover it shows drastic bottlenecks in MT-mode, which also don't help by regularity search. I could rotate it how you want, it changes nothing to me - neither I see "slightly better job" here, nor I think the distances is more "regular" now.
Well, then probably the rebalancing for levels 5 - 10 (or 11) would be not really necessary, is it? I understand what you mean, but my primary issue is - I cannot reproduce the picture of @senhuang42, I see almost always the pictures like in #2692 (comment) which are pretty irregular. |
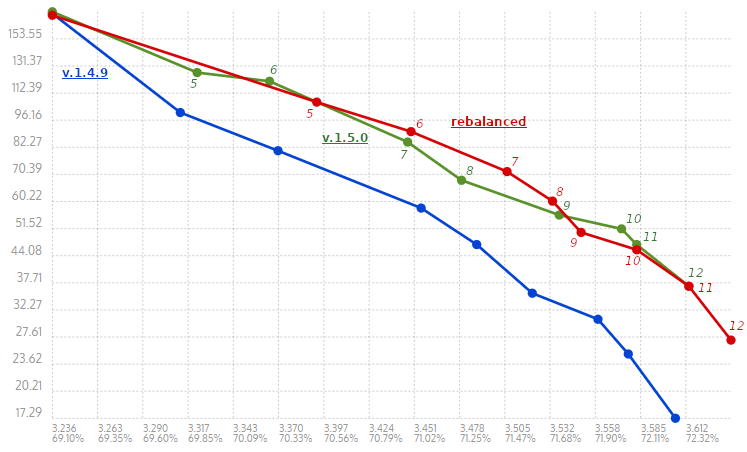
This PR rebalances some of the CParams for the middle compression levels to smooth out the ratio/speed curve a little bit. The methodology used was letting
paramgrillgive us some initial ideas to begin with, then do some manual tuning based on what the old curve looked like, trying to keep memory usage mostly in check, and maintaining monotonically increasingwLog. The file used wassilesia.tar(will check against other files too, but this is the main one for tuning).Currently, this only changes the > 256KB params.
I've provided some figures for how ratio and speed changes as we move through the compression levels.
>256K
Old curve 1.4.9:
Ratio/speed for 1.5.0 release (for reference):
Proposed ratio/speed:
Notes:
paramgrillwas mostly useful for levels 5-8ish), but I'm putting this PR up for now for any comments or suggestions.wLog ~= 22, and we don't want to artificially increasewLogto 27 just for the sake of LDM.btlazy2has some room for improvement, speed-wise.The smaller srcSize parameters also get some slight modifications to smooth out the curve a bit and fix redundant levels. There is less of an emphasis on shifting to compression ratio though, since that was already present.
<=256K
1.5.0:
new proposal:
<=128K
1.5.0:
new proposed:
Params <= 16K are unchanged, since we don't use the row matchfinder by default for those levels.