Python: add regex parser #5866
Python: add regex parser #5866
Conversation
…into python-regex-parser
Get the JS regex AST viewer
not having single char constants yet all redos results disappeared
|
|
||
| private string escapableChars() { result = "AbBdDsSwWZafnNrtuUvx\\\\" } | ||
|
|
||
| private string keywordChars() { result = "()|*+?\\-\\[\\]" } |
There was a problem hiding this comment.
I think you're missing some characters here, e.g. { and }. I tested the tokenization with the regex a*b{9}, and you can see that tokens treats the braces as both normalchar and as part of fixedrepeat:
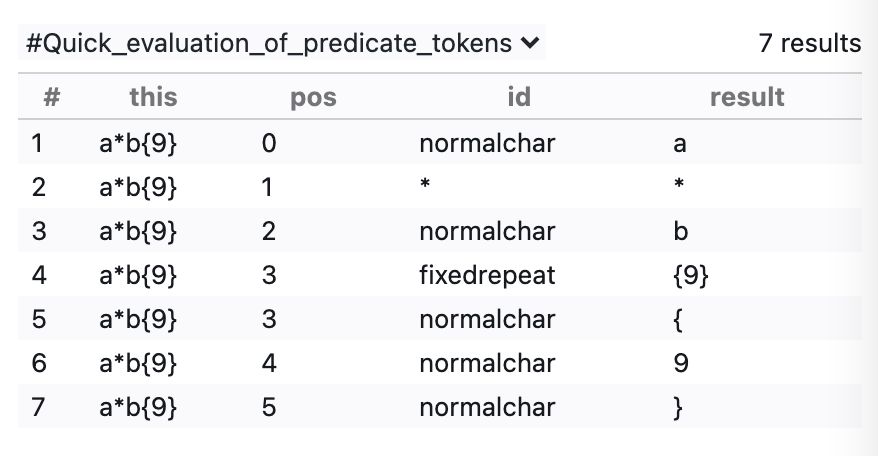
But I've only just started to try and understand this code, so it's possible I've misunderstood.
There was a problem hiding this comment.
{ and } can be a keyword or not based on context.
E.g. in a{b the { is a string constant, but { is a keyword in a{2,}.
That might be why.
That is at least the case for JavaScript.
Even though I think it's in conflict with the specification.
But everyone seems to do it.
There was a problem hiding this comment.
Ah, that makes sense.
But I assume we still need to maintain the invariant that each character in a regex literal is only part of one token. So in my example above, the last 3 rows should not be there.
There was a problem hiding this comment.
But I assume we still need to maintain the invariant that each character in a regex literal is only part of one token. So in my example above, the last 3 rows should not be there.
We could do that. A regular expression should be able to capture exactly which { and } are keywords.
(I haven't dived deep into the implementation, so I might be wrong).
But I'm not sure we need to do that.
The way the parser works is that is spuriously creates everything that seems feasible when looking at the very local context.
And each layer/iteration of the parser then only uses the tokens/ast-nodes that can be used to create a valid ast-node.
So I don't think spurious tokens are an issue.
Spurious tokens also arise when parsing dashes inside character classes.
E.g. in /foo[A-Z-]bar/, where the first dash is a keyword, and the second is a constant.
And I'm not sure if a regular expression can correctly capture which dashes are keywords.
If the C# extension is installed, then it reports 25k+ errors on the C# extractor until it is properly built. This is pure noise because the solution would be opened and built from the correct subdirectory. This commit disables the C# compilation altogether.
|
Superseded by #6175. |
This as a first stage for ReDoS, but we will also try to build AST viewing on it.