🐛 Describe the bug
I'm working on the RLHF implementation in application/ChatGPT,
Can I use LoRA in my actor/critic and turn shard_init on while also tensor parallelize my model after the initialization? I' ve tried several combinations all of the above functionalities and I've found problems under the following settings:
- LoRA + shard_init + TP: I modify the construction function of
LoRALinear in order to provide it the correct weight shape, but I found something went wrong resulting in NotImplementedError raised in colossalai/nn/_ops/embedding.py:130
- shard_init + TP: also the same
NotImplementedError
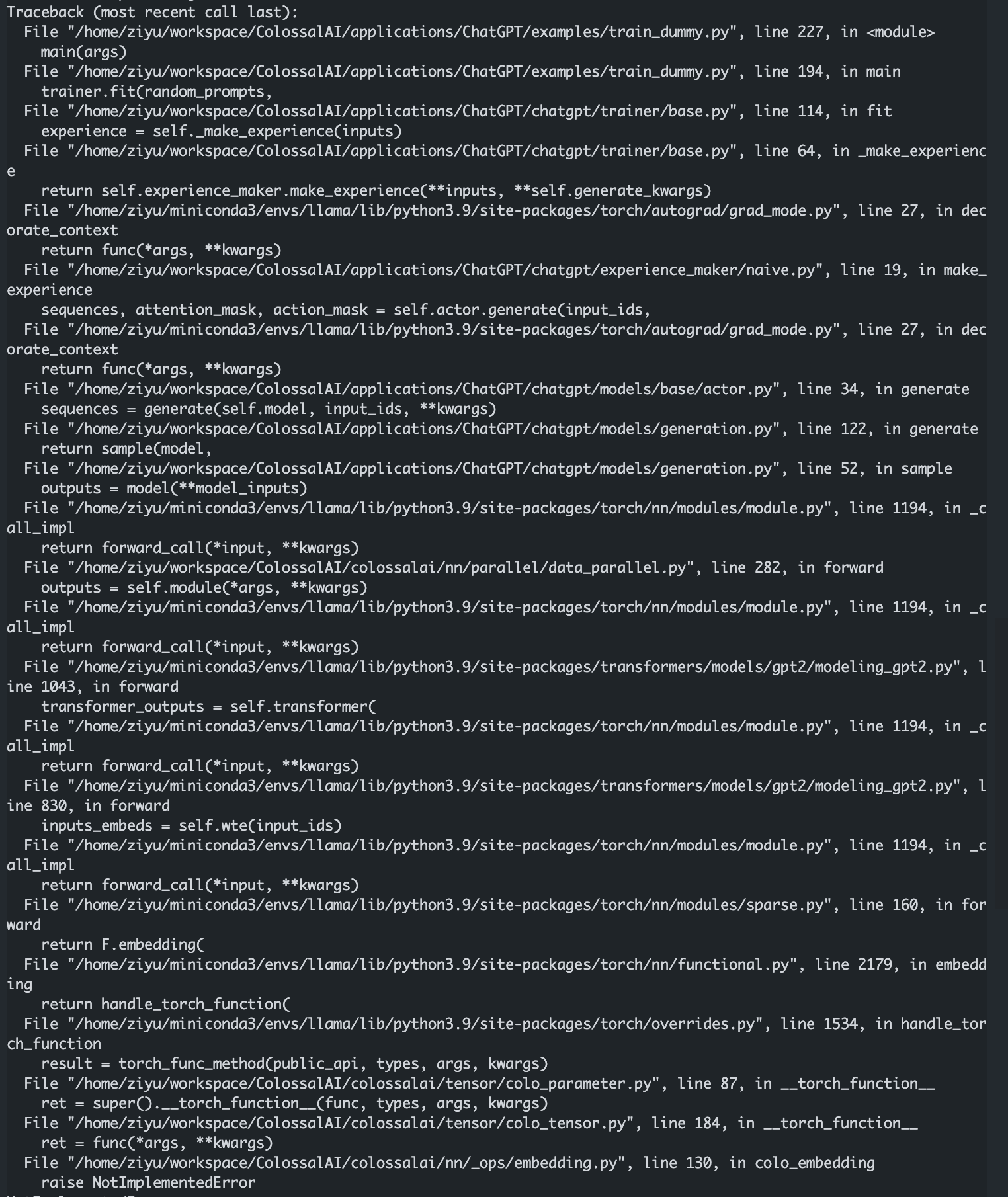
And also a noob question: when I use shard_init, I cannot let tp_degree different from nproc_per_node which raises error

While (LoRA + TP) runs well so I think maybe the problem is purely because my implementation of tensor parallelization has some conflicts with the provided scripts?
So here I first provide the TP code and my running scripts first. And about LoRA problem since it needs to provide another file, so maybe we can see it after (shard_init + TP) runs right.
Reproduction
my_train_dummy.py.zip
also modify GPTActor and GPTCritic by adding an input of lora_rank like the following code

Environment
torch 1.13.1
torchaudio 0.13.1
torchvision 0.14.1
colossalai 0.2.5
🐛 Describe the bug
I'm working on the RLHF implementation in
application/ChatGPT,Can I use LoRA in my actor/critic and turn
shard_initon while also tensor parallelize my model after the initialization? I' ve tried several combinations all of the above functionalities and I've found problems under the following settings:LoRALinearin order to provide it the correct weight shape, but I found something went wrong resulting inNotImplementedErrorraised in colossalai/nn/_ops/embedding.py:130NotImplementedErrorAnd also a noob question: when I use

shard_init, I cannot lettp_degreedifferent fromnproc_per_nodewhich raises errorWhile (LoRA + TP) runs well so I think maybe the problem is purely because my implementation of tensor parallelization has some conflicts with the provided scripts?
So here I first provide the TP code and my running scripts first. And about LoRA problem since it needs to provide another file, so maybe we can see it after (shard_init + TP) runs right.
Reproduction
my_train_dummy.py.zip

also modify
GPTActorandGPTCriticby adding an input of lora_rank like the following codeEnvironment
torch 1.13.1
torchaudio 0.13.1
torchvision 0.14.1
colossalai 0.2.5