Make most SOLR fields ignore diacritics#599
Make most SOLR fields ignore diacritics#599cdrini wants to merge 1 commit intointernetarchive:masterfrom
Conversation
|
@mek Can you confirm the solr version on production? There are things in the code which make me fear it might still be 1.4, but not sure. |
|
Thanks for tackling an issue first reported in 2010 by the lead engineer, then reported again in 2011, by the (then) project leader. Although it doesn't affect US (aka SF) users much, it's a been a critical usability issue for the rest of the world for the better part of a decade. I'll try to review more carefully in the next day or two, but I'm concerned by the "map down to ASCII" and "fold to ASCII" phraseology. The character encoding should be normalized, but in the Unicode domain, not the ASCII domain. Do you really mean ASCII or is that just a convenient shorthand for NFKC? |
|
@cdrini that mapping txt was there on my dev instance: |
|
@mek actually, can you perform a diff of it with |
|
@tfmorris Here's hoping it works :) |
e2ca745 to
b8849aa
Compare
|
Here are the ascii mappings that will be applied: https://www.apt-browse.org/browse/ubuntu/trusty/universe/all/solr-common/3.6.2+dfsg-2/file/etc/solr/conf/mapping-FoldToASCII.txt (this file might not be exactly the one we use depending on what version is in solr, but should be similar). |
|
I had a look at the FoldToASCII mappings and I'm not feeling any more comfortable that this helps anyone other than English speakers. What about normalization of all the non-Roman character sets in the world? Why can't NFKC be used? The current search scheme prevents users from finding entries which differ only in trivial encoding details such as precomposed diacriticals vs non-spacing diacriticals (for non-Roman character sets). |
|
Wow. I did some research into NFKC and unicode normalization, and that stuff is mind-blowing! Did not know all that stuff was happening under-the-hood; super neat! Here's my quick summary for the uninitiated: https://gist.github.com/cdrini/ef398d918959444b282fbb566082bb7b (from reading http://unicode.org/reports/tr15/ ). @tfmorris I think we've again come up with another case of misleading wording :P. "Normalization" here does not mean "unicode normalization" (that would be too clear) but basically just removing diacritics. As far as I can tell, no form of unicode normalization does this. I think normalizing to NFKC is a great idea, especially if there are inconsistencies in our data, but I would consider that a different issue from that which was originally posed in #178 (although that issue, again as a result of using the word "normalization", ended up touching on unicode normalization as well, it was originally about allowing searches to match with diacritics stripped). To clarify: unicode normalization would ensure that the following searches all return the same results (which they currently do not; although they do if searching works for some reason 🤔):
Stripping diacritics ensures the following searches all return the same results:
Stripping diacritics would allow people to search without having to use the special keys for diacritic characters, which would be a boon for both English speakers searching for non-English works as well as for non-English speakers searching for non-English works. If you got all the way to the end of this |
 mekarpeles
left a comment
mekarpeles
left a comment
There was a problem hiding this comment.
I'm approving the changes but we should hold off merging until we figure out how reindexing will occur
@cdrini notes:
Probably hold off on merging the diacritics stripping PR Did some research and it looks like a full reindex will require a bit more planning to avoid any downtime (this site seems to have some good tips: http://www.ehabelgindy.com/how-to-achieve-zero-downtime-sitecore-deployments-part-ii/ )
|
Sorry! I conflated normalization and folding, leading you on a wild goose chase. I think using one of the normalized forms for our data would be an improvement, but it's separate from the searching indexing issue. My objection to ASCII remains though. It's not an English speaking world. You want the ICU Folding Filter, at a minimum. If you wanted to get fancy, you could investigate the ICU Transform Filter to do stuff like transliteration: Source | Transliteration |
conf/solr/conf/schema.xml
Outdated
| words="stopwords.txt" | ||
| enablePositionIncrements="true" | ||
| /> | ||
| <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true"/> |
There was a problem hiding this comment.
These are English (only) stop words
|
On the subject of stop words, the current list is English only which may not be appropriate. Additionally whatever is used to index personal names (e.g. authors) should use stop words at all, most likely. The current field type "textgen" includes English stop words which will zap things like A, An, etc. |
|
Here are some background links on Solr language processing: https://www.liip.ch/en/blog/search-get-past-english-with-solr |
|
@mek Speaking of reindexing, is there a staging server that can be used to test search changes? Search is a cornerstone of the user experience, so it's definitely something we want to be improving, not making worse -- which means we need to be able to test our changes. |
|
Internet Archive is using the ICU components for its index: That post also has some good hints on how to replace a generic English only stopwords list with common words from the corpus. |
|
Interesting read. Very ingenious handling of common words: Avoiding a complete ignore of "the", rather than turning "the" "quick" "brown" "fox" into "the" "quick" "brown" "fox", they used "the quick" "quick" "brown" "fox" instead. Slick! |
|
@tfmorris Thanks for the info! And no worries, it was an informative 'goose chase' :) I like the looks of the ICU Folding Filter! It seems like it handles Unicode normalization, case folding, and diacritic stripping (i.e. win-win-win!). The Solr docs say it's better than "ASCII Folding Filter, Lower Case Filter, and ICU Normalizer 2 Filter.". The full foldings performed by this filter are here: https://lucene.apache.org/core/3_6_2/api/contrib-icu/org/apache/lucene/analysis/icu/ICUFoldingFilter.html (Info about each type of folding can be found here: http://www.unicode.org/reports/tr30/tr30-4.html#_Toc22 ). Adding this is slightly more involved since we have to enable some solr plugins (which might take some time to figure out depending on how prod is configured). I think I'd like to setup a workflow for reindexing solr with minimal downtime first (since that will be necessary for most solr schema changes), but I was able to get the ICU folding filter running locally in ~1 day: https://github.com/cdrini/openlibrary/compare/178/hotfix/normalize-author-name-in-solr...cdrini:feature/solr-icu-folding-filter?w=1 (note this is mostly just me playing around until it worked and needs some more love to be production ready :) ) With regards to stopwords, that is very much outside the scope of this PR. Also, at least on the local dev environment, that stopwords file is empty :P Not sure if this is the case for prod, though. |
b8849aa to
6fdb1c4
Compare
|
@cdrini Cool! Let me know when you've got a revised (or different) PR that you'd like reviewed. @mekarpeles It's probably obvious, but even though this is "approved" I don't think it should be merged in its current state. Also, on a related note, any info on a staging server? (asked above, but I pinged the wrong mek)
|
|
@cdrini let's bring this up for our Tuesday call to see what next steps are. |
|
What is needed to make some progress on this? Can we make a list of the blockers? |
|
@tfmorris are there any updates re: getting solr up to date for this merge? |
|
Sorry for the lack of progress on this. I'll try to get to it in the next few days. |
|
@cdrini @tfmorris @hornc @mekarpeles Meanwhile, without the umlaut, both |
|
cc: @seabelis (so you are aware this fix-in-progress exists) |
|
For clarity, this is blocked by #1067 . We have the fix, but no way to get in into production right now. |
|
PR #2246 includes support for the ICUFoldingFilter that I mentioned. |
|
I'm going to go ahead and reject this; it's been open for a very long time, and this isn't the way I'd do it now, anyways. I can always look at the closed PR for reference :) |
|
Re-opening as a result of discussion on #3290 (see #3290 (comment) ). We can use ASCII Folding as a temporary patch until we update to solr 8 and use the ICUFolding filtter. |
6fdb1c4 to
8b00120
Compare
|
As I mentioned at least a couple of times in 2017, this isn't an adequate solution. The real solution can be found in c7026ff and is only a few lines. Since the bug has been open for over a decade, let's fix it right. |
Meant to address #178
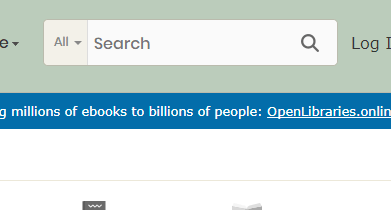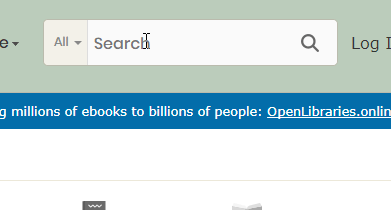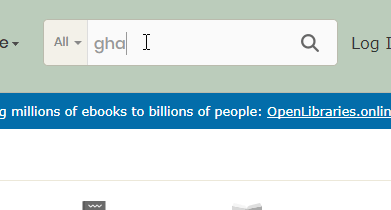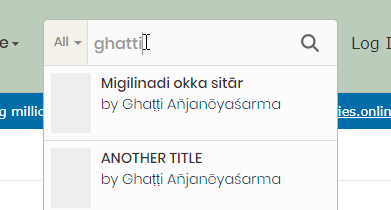
Do note I'm not too experienced with solr, so please review carefully :)
The following fields will now map any ascii-able (see below) characters down to ascii before indexing and querying:
Here are the ascii mappings that will be applied: https://www.apt-browse.org/browse/ubuntu/trusty/universe/all/solr-common/3.6.2+dfsg-2/file/etc/solr/conf/mapping-FoldToASCII.txt (this file might not be exactly the one we use depending on what version is in solr, but should be similar).
Note this will replace whatever file is currently at
/etc/solr/conf/schema.xmlwith a symlink to the schema file in$OL_ROOT/conf/solr/conf/schema.xml.Note: to fully reindex solr from the vagrant environment:
sudo /etc/init.d/tomcat6 restart # restart solr's server sudo -u vagrant make reindex-solr