- Java SE
- JavaWeb
- 剑指Offer75
- 苍穹外卖
- 代码随想录
- Java并发编程
- JavaGuide
- Raft协议
- 备战秋招
- 代码随想录
- JAVA虚拟机
- 黑马商城(SpringCloud微服务)
- JUC并发编程
- JavaGuide
- Raft协议
- 华为软件精英挑战赛
- 备战秋招
- 24.11.26 ~ 24.12.15
- 整理资料
- 24.12.16 ~ 24.12.30
- 整理资料
- 24.12.11 ~ 24.12.29
- 整理资料
- 25.01.02 ~ 25.01.14
- 整理资料
- 24.12.31 ~ 25.02.19
- 25.02.14 ~ 25.02.25
- 整理资料
- 25.02.26 ~ 25.06.14
- 25.03.03 ~ 25.05.01
- 25.07.20 ~ 至今
- 25.01.02 day1
- 25.01.03 day2
- 25.01.04 ~ 25.01.05 day3 ~ day4
- 25.01.06 day4 ~ day5
- 25.01.07 day6 (前端部分略过)
- 25.01.08 day7 (Redis)
- 25.01.09 ~ 25.01.10 day8 ~ day9 (支付功能略过)
- 25.01.12 day10
- 25.01.13 day11
- 25.01.14 day12
- 前端部分略过
- 24.12.31 ~ 25.02.19
-
24.12.30 数组 -- 二分查找 双指针
-
24.12.31 数组 -- 滑动窗口
-
25.01.05 数组 -- 螺旋矩阵 前缀和 链表 -- 1 ~ 5
-
25.01.06 链表 -- 6 ~ 8 哈希表 -- 1 ~ 6 ,8
- 重点 哈希表 -- 8 三数之和
-
25.01.07 字符串 -- 1 ~ 6
- 重点 字符串 -- 6 kmp算法(如果要从j=0开始匹配,那么next[0] = -1)
-
25.01.08 字符串 -- 7 栈和队列 -- 1 ~ 8
- 重点 栈和队列 -- 7 滑动窗口
-
25.01.10 二叉树 -- 1 ~ 10
-
25.01.12 二叉树 -- 11 ~ 21
- 重点 二叉树 -- 12 平衡二叉树(递归记录高度+判断时,可以用-1表示否逻辑 这样只需返回Integer一个变量)
- 重点 二叉树 -- 18 从中序和后序遍历序列构造二叉树(HashMap 记录 inorder的信息 , 利用中序确定左右子树信息,利用后序/前序确定根节点)
-
25.01.13 二叉树 -- 22 ~ 34
- 重点 二叉树 -- 23 验证二叉搜索树(左右子树都是二叉搜索树并不能判断跟子树也是 利用中序遍历判断前后即可)
- 重点 二叉树 -- 26 二叉树的最近公共祖先(递归判断左右子树是否包含p或q,如果包含则返回当前节点,否则返回null
- 重点 二叉树 -- 30 删除二叉搜索树的节点(递归删除左右子树,如果当前节点等于val,分情况讨论 利用有返回的递归)
-
25.01.14 回溯算法 -- 1 ~ 10
- 重点 回溯算法 -- 1 8 组合总和Ⅱ(排序 + 使用used 判断上一个数用没用过 如果没用过但是值相同直接跳过)
-
25.01.15 回溯算法 -- 11 ~ 21
- 重点 回溯算法 -- 14 递增子序列(层级递归)*
- 重点 回溯算法 -- 19 重新安排行程(递归+ 栈的思想)*
-
25.01.16 贪心算法 -- 1 ~ 8
-
25.01.17 贪心算法 -- 9 ~ 16
-
25.01.22 贪心算法 -- 17 ~ 23
- 重点 贪心算法 -- 23 监控二叉树(可以理解为树状dp)(递归返回三种状态: 0:未被覆盖 2:已被覆盖 1:已安装摄像头)
-
25.01.23 动态规划 -- 1 ~ 14
- 重点 动态规划 -- 9 不同的二叉搜索树(以i为)根节点,左子树有i-1个节点,右子树有n-i个节点,所以以i为根节点的二叉搜索树的个数为左右子树的笛卡尔积))
- 重点 动态规划 -- 14 最后一块石头的重量(对于分成最接近的两部分问题,可以转换成总体积一半的背包最多能装的价值问题 01背包问题 价值即为体积)
-
25.01.24 动态规划 -- 15 ~ 25
-
25.01.25 动态规划 -- 26 ~ 36
-
25.01.27 动态规划 -- 37 ~ 47
-
25.01.30 动态规划 -- 48 ~ 54 单调栈 -- 1 ~ 5
- 重点 动态规划 -- 52 回文字串(dp[i][j] = dp[i+1][j-1] && s[i] == s[j]))
- 重点 单调栈 -- 4 接雨水(双指针想法和单调栈想法)
- 重点 单调栈 -- 5 柱形图中最大的矩形(双指针和单调栈)
-
25.01.31 图论 -- 1 ~ 10
-
25.02.01 图论 -- 11 ~ 18
-
25.02.04 图论 -- 19 ~ 23
-
25.02.05 图论 -- 24 ~ 29
- 重点 图论 -- 27 bellmen-ford算法求最多k次中转的最短路径(层级更新 额外记录上次迭代时的距离)
- 重点 图论 -- 29 A*算法(启发式搜索 估计函数+优先队列 强化版BFS)
-
25.02.13 额外题目 -- 数组 哈希表 字符串
- 重点 额外题目 -- 重排链表(找到中点+反转后半部分+合并两个链表)
- 重点 额外题目 -- 回文链表(找到中点+反转后半部分+比较两个链表)
-
25.02.14 额外题目 -- 二叉树 贪心
-
25.02.18 额外题目 -- 动态规划 图论
-
25.02.19 额外题目 -- 并查集 模拟 位运算
- 重点 额外题目 -- 并查集 冗余运算Ⅱ(两种条件:入度为2 或者成环)
- 重点 额外题目 -- 模拟 下一个排列(从后往前找到第一个升序对,然后从后往前找到第一个比升序对大的数,交换后翻转后面的数)
- 25.01.09 ~ 至今
- 25.01.09 第二章 -- Java内存区域与内存溢出异常
- 25.01.13 ~ 25.01.15 第三章 -- 垃圾收集器与内存分配策略
- 25.01.16 ~ 25.02.12
- 整理资料
- 25.01.16 ~ 25.01.17 MybatisPlus
- 25.01.21 Docker
- 25.01.22 ~ 25.01.23 微服务(Nocus OpenFeign)
- 25.01.24 微服务(登录校验) 重点复习
- 25.01.25 ~ 25 01.26 微服务保护与分布式管理
- 25.01.27 MQ消息队列基础
- 重点 利用
MessageConverter将消息转换为jsn格式,并利用重写fromMessage和toMessage方法在请求头传递和解析用户Id,实现类似于拦截器的功能
- 重点 利用
- 25.01.31 MQ消息队列高级 (代码实现没有细看和操作)
- 25.02.01 ElasticSearch基础
- 25.02.02 ElasticSearch高级
- 25.02.04 ElasticSearch作业
- 25.02.05 Redis面试相关
- 25.02.06 微服务面试相关
- 25.02.10 ~ 25.02.12 复习黑马商城微服务资料
- 25.03.03 ~ 25.03.08 docker compose 部署上云
- 25.02.14 ~ 25.02.25
- 整理资料
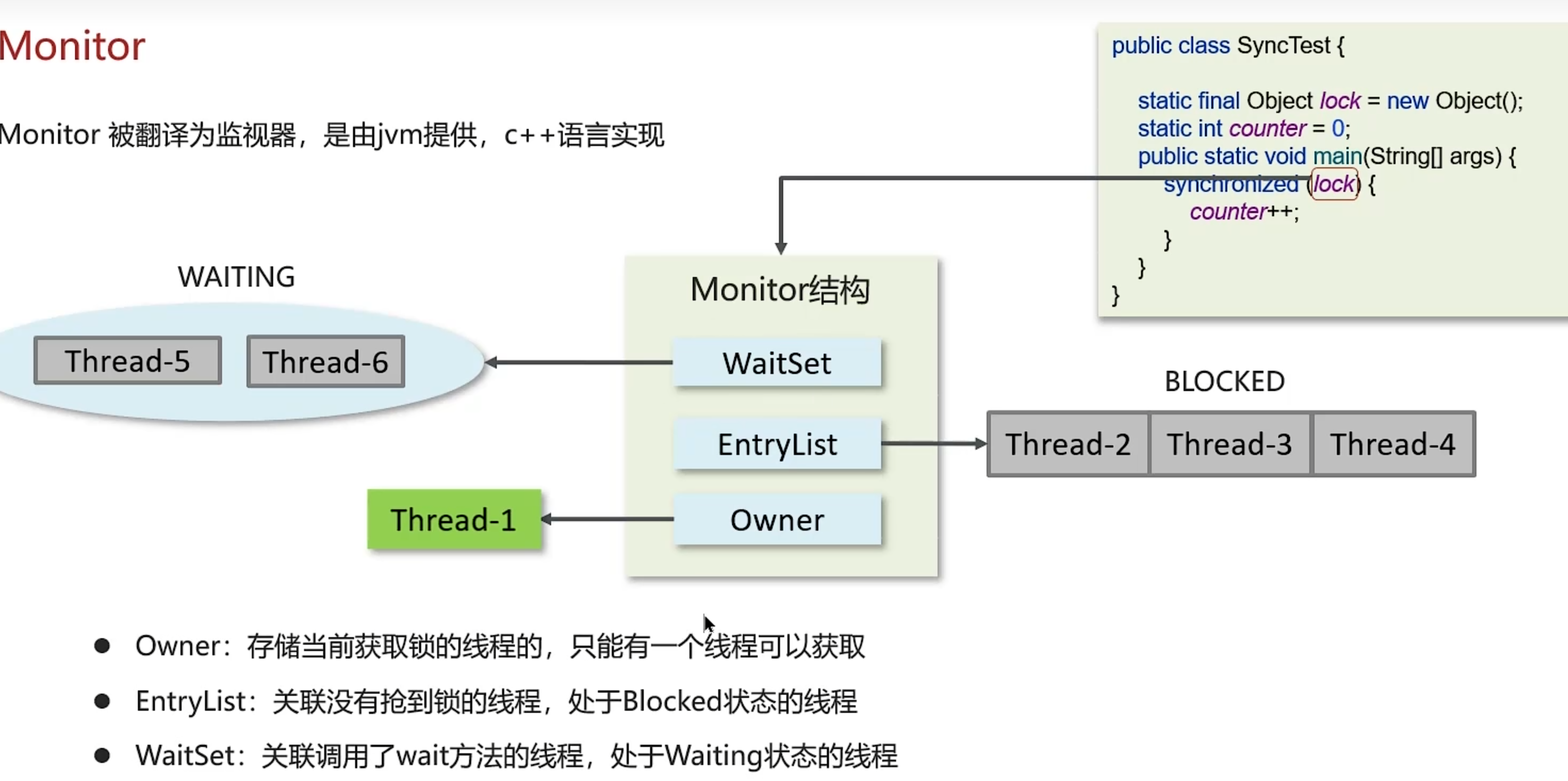
- 25.02.14 JUC并发编程 -- 1 ~ 42
- 主要学习内容 线程的创建和启动,线程的状态,常见方法
- 25.02.15 JUC并发编程 -- 43 ~ 96
- 主要学习内容 线程安全、线程同步,对象锁synchronized(重量级锁,自旋锁,偏向锁,轻量级锁)
- 重点 synchronized的锁升级过程
- 主要学习内容 线程安全、线程同步,对象锁synchronized(重量级锁,自旋锁,偏向锁,轻量级锁)
- 25.02.18 JUC并发编程 -- 97 ~ 133
- 主要学习内容 锁ReentrantLock, Park和Unpark(信号量机制)、保护性暂停(同步 一对一)、生产者消费者模式(异步 多对多)、顺序控制
- 重点 ReentrantLock的使用和原理
- 重点
wait()和notify()的使用和原理
- 主要学习内容 锁ReentrantLock, Park和Unpark(信号量机制)、保护性暂停(同步 一对一)、生产者消费者模式(异步 多对多)、顺序控制
- 25.02.19 JUC并发编程 -- 134 ~ 168
- 主要学习内容 volatile关键字(读屏障、写屏障)-> 可见性、有序性、不保证原子性
- 重点 volatile的使用和原理
- 重点 volatile的内存屏障
- 重点 单例设计模式(懒汉式、饿汉式、双重检查、静态内部类、枚举)
- 重点 缓存优化 -> 影响可见性 指令重排序 -> 影响有序性
- 主要学习内容 volatile关键字(读屏障、写屏障)-> 可见性、有序性、不保证原子性
- 25.02.20 JUC并发编程 -- 169 ~ 204
- 主要学习内容 CAS、原子、自定义线程池
- 重点 原子类的使用和原理
- 重点 自定义线程池的使用和原理
- 主要学习内容 CAS、原子、自定义线程池
- 25.02.21 JUC并发编程 -- 205 ~ 232
- 主要学习内容 ThreadPoolExecutor、设计模式-工作线程-饥饿(解决办法:不同工作不同线程池)、Tomcat线程池(自旋重试、核心线程->救急线程->阻塞队列) )
- 25.02.22 JUC并发编程 -- 233 ~ 270
- 主要学习内容 ForkJoinPool(递归线程池 分治)、CountDownLatch、Semaphore(信号量)、reenTrantReadWriteLock(读写锁)
- 25.02.26 ~ 25.06.14
- 整理资料
- 25.02.26 并发编程 -- 常见面试题(上)(中)AQS详解
- 25.02.27 并发编程 -- 常见面试题(下) 乐观锁和悲观锁 CAS详解 JMM详解
- 25.04.20 JAVA IO
- 25.04.21 Java集合
- 25.04.22 JVM
- 25.04.23 数据库 -- 基础 ~ SQL常见面试题总结(2)
- 25.04.24 数据库 -- MySQL常见面试题总结 高性能优化规范 计算机基础 计算机网络常见面试题(上)
- 25.03.03 ~ 25.05.01
- 25.03.08 ~ 25.03.30 初赛第二名
- 25.03.31 ~ 25.04.14 复赛滑跪
- 25.07.20 Java数据比较
public static void main(String[] args) {
Long a = new Long(42);
Integer b = new Integer(42);
BigInteger c = new BigInteger("42");
// System.out.println(b == c); // false, because a is Long and b is Integer, different types
// System.out.println(a == b); // false, because a is Long and b is Integer, different types
System.out.println(a.equals(b)); // true, because Long's equals method checks for value equality
int d = 10;
double e = 10.0;
System.out.println(d == e); // true, because d is int and e is double, but they are both 10
System.out.println(e == d);
System.out.println(e ==10); // true,
Boolean f = new Boolean(true);
String g = new String("true");
// System.out.println(f == g); // 不可比较
System.out.println(f.equals(g)); // false, because f is Boolean and g is String, different types
// String s = null;
// System.out.println("s= " + s); // s= null
// String s ;
// System.out.println("s= " + s); //报错 未初始化s
int i = 1;
int j = i++;
if((i>++j)&&(i++ ==j)) // &&后不执行
{
i+=j;
}
System.out.println("i= "+i); // i= 2
}
-
25.07.21
- 代码随想录
- 重点 验证二叉搜索树
- 分布式事务
- SEATA 提供XA(cp),AT(ap), TCC(ap)三种事务模型
- MQ
- 代码随想录
-
25.07.22
- 接口幂等性
- 幂等性:多次执行同一操作,结果相同
- 新增操作:数据库唯一索引解决
- 更新操作:使用版本号或时间戳 或者reids+token 以及分布式锁
- Kafka
- 结构
- 防止消息丢失
- 消息生产阶段: 生产者确认机制+ 重试
- 消息传输阶段: 消息副本机制+ ISR机制(in-sync_replicas + leader_follower + HW 高水位机制)
- 消息消费阶段: 接受消息+消息处理之后再回复ACK,对于kafka来说可以改为手动提交偏移量
- 结构
- 接口幂等性
-
25.07.24
- 代码随想录
- 重点 二叉搜索树的插入操作
- 重点 修剪二叉搜索树
- 对于二叉搜索树的递归理解
-
- 利用中序遍历的特性,记录previous节点,用当前节点和previous节点比较大小
-
- 根据当前节点是否满足要求,对左子树或右子树进行有返回值的递归
-
- HashMap
- Synchronized
- Lock : ReentrantLock,ReentrantWriteReadLock
- 可超时 tryLock(long timeout, TimeUnit unit)
- 可中断 lockInterruptibly()
- 可重入
- 公平锁和非公平锁
- 多条件变量
- 代码随想录
-
25.07.27
- ThreadLocal
- 运行时常量池
- ThreadLocal
-
25.07.28
- 工厂设计模式
- 主要作用:解耦
- 策略设计模式
- 主要作用:替换if-else或switch-case
- 单点登录(SSO)
*
- 权限认证
- RBAC(Role-Based Access Control)基于角色的访问控制 + Spring Security 电商项目可以描述
- 棘手问题
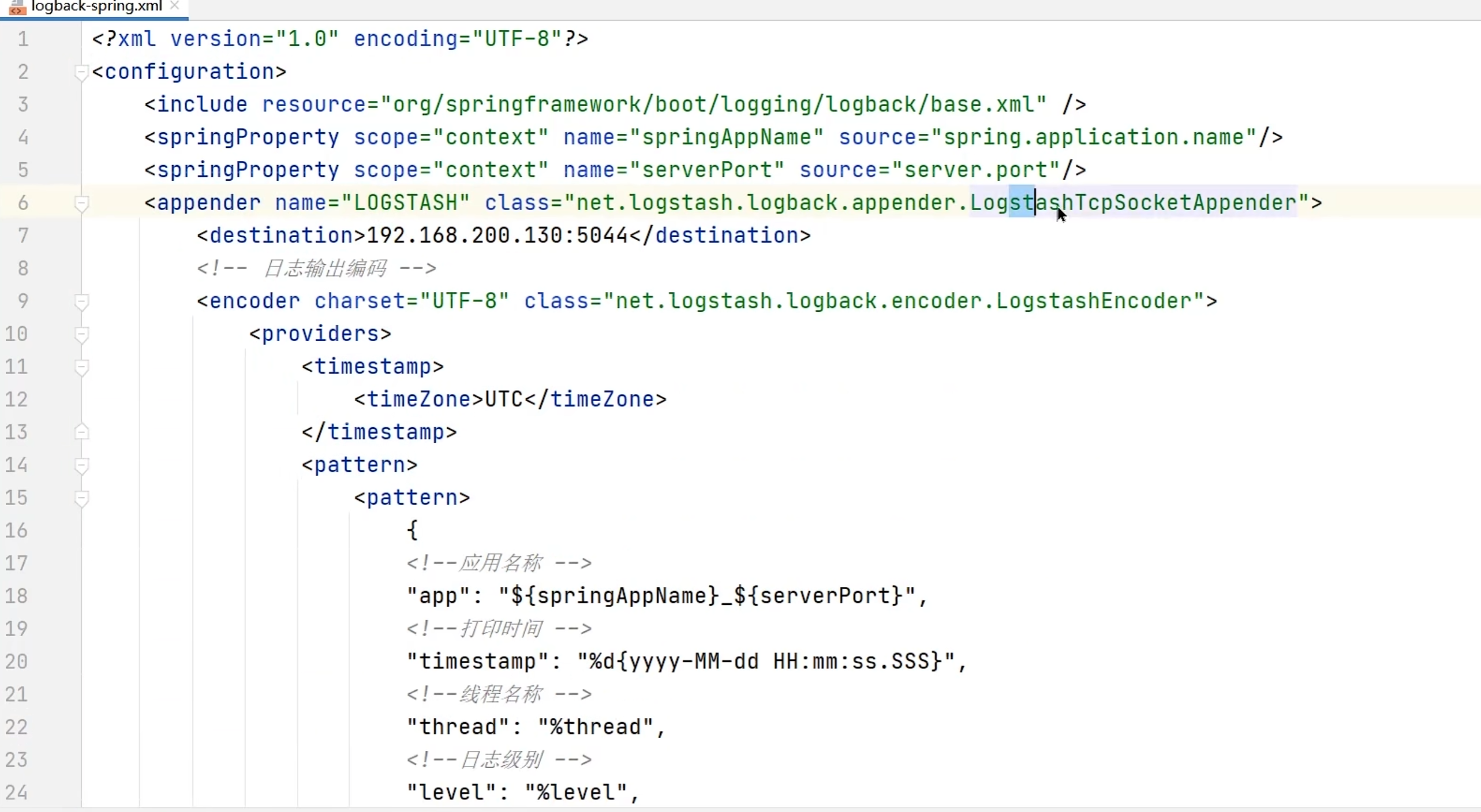
- 日志采集
- 在
logback-spring.xml中配置日志采集(logStash的相关配置) - 在
kibana中的discover中筛选日志,dashboard中可视化日志
- 在
- 查看日志
- 如何定位性能瓶颈
- 工厂设计模式
-
25.07.29
- 代码随想录
- 重点 根据身高重建队列
- 给某个人排队时需要保证所有比他高的人都已经排好,只需要在指定位置插入即可
- 因此对身高进行降序排序,身高相同的按照k值升序排序
- 重点 根据身高重建队列
- Raft协议
- 如何解决脑裂问题
- 不发生网络分区时,基于任期号机制+心跳检测,确保只有一个leader
- 发生网络分区时,基于多数派投票机制,确保只有多数派分区能选举出leader
- 即使分区后原leader位于少数派分区,也会因为心跳检测超时而失去leader资格,自动退位
- 如何实现配置变更( 两阶段配置变更 )
- 一阶段:联合共识
- 分别记录新旧配置的节点信息
- 使用日志复制传输配置信息
- 需要同时满足新旧配置的多数派要求后,将联合共识配置加入到状态机中
- 二阶段:新配置生效
- 满足新配置的多数派要求后,状态机将新配置生效
- 旧配置的节点会被新配置的节点踢出集群
- 核心优势
- 通过联合共识,确保新旧配置的节点都能参与到共识中,避免了脑裂问题
- 新配置生效后,旧配置的节点会被踢出集群,确保集群的一致性
- 一阶段:联合共识
- 项目用到了哪些JUC组件
- 自定义线程池
RaftThreadPool和RaftThreadPoolExecutor- 定时线程池:心跳检测,投票选举重试
- 普通线程池:日志复制,RPC调用
- 自定义线程池执行器:记录任务执行时间和释放
ThreadLocal资源
- 阻塞队列
BlockingQueue- 限制队列长度用于线程池
CountDownLatch- 用于等待所有投票选举RPC完成
- 原子变量
AtomicInteger- 用于记录日志复制成功数和投票数,确保线程安全
ReentrantLock- 用于保护日志写入和状态机操作的线程安全
ConcurrentHashMap- Leader节点记录每个Follower节点的下一个日志索引和已提交日志索引
- 自定义线程池
- 项目中对于threadLocal的使用
- ThreadLocal的作用是在线程池(RaftThreadPoolExecutor)执行任务时,为每个线程维护一个独立的时间戳,用来计算任务的执行耗时。在beforeExecute方法中获取时间戳,在afterExecute方法中计算耗时并清理ThreadLocal,这样可以避免线程间的数据竞争,确保每个线程都有自己独立的时间记录
- 日志压缩
- 日志压缩的目的:减少日志存储空间,提高日志复制效率
- 日志压缩的方式:快照(Snapshot)
- 快照的核心信息
- 最后日志索引
- 最后日志任期
- 状态机数据
- 快照策略(SnapshotStrategy)
- 快照版本
- 使用策略模式实现了不同的快照策略
- 基于日志条数的快照策略(1000条)
- 基于时间的快照策略(每隔7天)
- 基于日志大小的快照策略(1G)
- 快照的核心信息
- 为什么用RocksDB
- RocksDB是一个高性能的键值存储数据库
- 底层使用了LSM树(Log-Structured Merge Tree)数据结构
- LSM树的核心思想是将写操作先写入内存中的MemTable,然后定期将MemTable中的数据合并到磁盘上的SSTable中
- 用顺序写入代替随机写入(SkipList 快表的有序行保证查询性能,为顺序写入提供有序的数据源),减少磁盘寻址时间,适合写入密集型场景(频繁追加日志的分布式系统)
- 采用分层存储:热数据在内存中,冷数据在磁盘上
- 支持压缩和合并操作,减少存储空间
- 项目的RPC框架
- 项目基于阿里巴巴开源的
SOFA-Bolt框架构建,底层使用Netty作为网络传输层,整个框架的设计思路是提供一个高性能、低延时的分布式通信解决方案。 - 从架构上看,我们采用了经典的分层设计模式,为客户端和服务端分别封装了接口,通过
Request和Response这两个统一的消息格式来进行 数据交换 - 在具体实现上,我们定义了几种核心的请求类型,比如选举投票、日志复制、客户端请求、成员变更等,每种请求类型都有对应的处理器, 服务端会根据请求类型分发到不同的业务逻辑处理器上。
- 在性能方面,首先Netty本身就是一个高性能的网络框架,它的事件驱动模型和零拷贝技术大大提升了网络传输效率。我们使用了连接池来复用连接,
避免频繁建立连接的开销。序列化这块我们主要使用
Hessian,它在性能和兼容性之间取得了很好的平衡。 - 在实际使用中,这个RPC框架支撑了整个Raft集群的通信。比如Leader选举时,候选人会向其他节点发送投票请求;日志复制时,Leader会向Follower发送追加日志请求;客户端操作时,会通过RPC调用Leader节点。所有这些通信都通过这个统一的RPC框架来完成。
- 项目基于阿里巴巴开源的
- 为什么使用
SOFT-Bolt框架- 第一个是性能优势。SOFA-Bolt基于Netty构建,采用了同步非阻塞的I/O模型,在高并发场景下性能表现优异。对于Raft协议这种需要频繁进行节点间通信的分布式系统来说,网络性能是至关重要的。从日志可以看到,项目中的RPC调用都是通过"Bolt-default-executor"线程池来处理的,这说明SOFA-Bolt能够很好地处理并发请求。
- 第二个是稳定性。SOFA-Bolt是阿里巴巴内部大规模使用的RPC框架,经过了生产环境的充分验证。在分布式系统中,网络通信的稳定性直接影响到整个系统的可用性。Raft协议要求节点间能够可靠地进行心跳检测、日志复制、选举投票等操作,SOFA-Bolt的稳定性为这些核心功能提供了保障。
- 第三个是易用性。从代码实现可以看到,SOFA-Bolt的API设计非常简洁。比如在DefaultRpcServiceImpl中,只需要几行代码就能启动RPC服务器并注册处理器
- 总的来说,选择SOFA-Bolt作为RPC框架,主要是看中了它的高性能、高稳定性、易用性以及良好的生态支持。这些特性使得SOFA-Bolt能够很好地满足Raft分布式系统对网络通信的要求,为整个系统的可靠运行提供了坚实的基础。
- 如何解决脑裂问题
- 代码随想录
-
25.07.30
- TCP/IP
- HTTP 1.1
- 长连接:Connection: keep-alive
- 断点重传:
- 客户端:
Range - 服务端:
Content-Range,Accept-Ranges,Content-Length
- 客户端:
- TLS/SSL
- 四次握手
- 客户端发起
ClientHello请求,发送TLS版本、加密套件、第一个随机数等信息 - 服务端响应
ServerHello,发送证书、加密套件、第二个随机数等信息 - 客户端验证证书后,发送
ClientKeyExchange,用公钥加密生成的第三个随机数,并生成摘要发送给服务器,表示客户端握手结束 - 服务端收到后,解密第三个随机数,,获得会话密钥,生成摘要并发送给客户端,表示服务端握手结束
- 客户端发起
- 非对称加密算法: RSA、ECC
- 对称加密算法: AES、DES
- 哈希算法: SHA-256、SHA-512,MD5(不安全)
- 四次握手
- HTTP 2.0
- 二进制分帧:将请求和响应分成多个二进制帧进行传输
- 多路复用:引入了Stream概念,在一个TCP连接上同时发送多个请求和响应,避免了HTTP 1.1的队头阻塞问题
- 服务器可以乱序返回,浏览器再按ID组装
- 头部压缩:使用HPACK算法对请求和响应头进行压缩,减少传输数据量
- 服务端推送:服务端可以主动向客户端推送资源,减少客户端的请求次数
- HTTP 3.0
- 基于QUIC协议,放弃了TCP,基于UDP实现的可靠传输协议
- 在UDP上实现了多路复用,丢包重传,拥塞控制等功能,彻底解决应用层+传输层(TCP按序交付)的队头阻塞问题
- QUIC更快的建立连接:QUIC内部包含了TLS,它在自己的帧会携带TLS里的”记录”,再加上QUIC使用的是TLS/1.3,因此仅需1个RTT就可以「同时」完成建立连接与密钥协商
- QUIC支持连接迁移:使用连接id而不是tcp的四元组
- JWT
- JSON Web Token(JWT)是一种开放标准(RFC 7519),用于在网络应用环境间以JSON对象的形式安全地传递信息
- JWT由三部分组成:头部(Header)、载荷(Payload)、签名(Signature)
- JWT可以解决集群部署的问题(单点登录)
- JWT是无状态的,服务端不需要存储会话信息
- JWT缺点:没办法及时撤销
- 解决办法:使用短期有效的JWT和刷新令牌(Refresh Token)或者使用黑名单机制
- TCP为什么三次握手
- 避免历史连接,造成资源混乱和浪费
- TCP四次挥手为什么要等待2MSL
- MSL是指TCP连接的最大报文段生命周期,确保所有数据包都能被正确接收和处理
- 如果不等待2MSL,可能会导致数据包丢失或重复,影响连接的可靠性
- HTTP 1.1
- TCP/IP
-
25.07.31
- Jgit项目
- JGit核心概念
- JGit是一个纯Java实现的Git版本控制系统库
- Git对象模型
- Git对象分为四种类型:Blob(文件内容),Tree(目录结构),Commit(提交记录),Tag(标签)
- 每个Git对象都有一个唯一的SHA-1哈希值作为标识
- Ref(引用)
- HEAD:当前分支的引用
- 分支引用
- 标签引用
- 远程引用
- 实现功能
- 创建和管理Git仓库
- 提交和回滚版本
- 分支管理:获取分支和标签信息
- 差异比较:比较两个提交之间的差异
- 文件操作:读取和写入文件内容
- 远程操作:克隆、推送、拉取等
- 权限控制:结合Gitolite实现权限控制
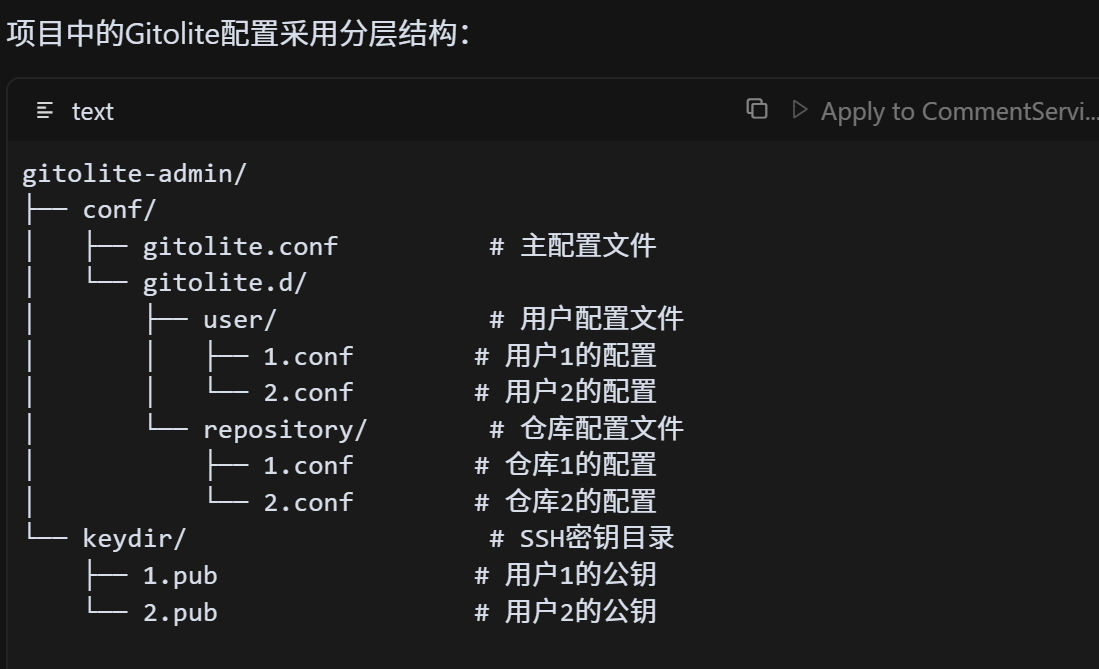
- Gitolite
- Gitolite是一个基于SSH的Git服务器管理工具,可以实现细粒度的Git仓库权限控制
- 仓库级别的权限控制
- 分支级别的权限控制
- 用户组和仓库组管理
- 项目配置结构
- 项目中的Gitolite集成
- 当创建新用户/仓库/协作者时,系统会自动在Gitolite中创建配置
- 所有Git操作都通过Gitolite进行权限验证
- 所有Gitolite操作都是事务性的,失败会回滚
- Gitolite是一个基于SSH的Git服务器管理工具,可以实现细粒度的Git仓库权限控制
- 为什么项目使用PostgreSQL,而不是MySQL
- PostgreSQL是一个功能强大的关系型数据库,支持复杂查询和事务处理
- 对象关系映射(ORM)支持更好,支持自定义符合数据类型
- PostgreSQL的ACID特性和MVCC(多版本并发控制)使其在高并发场景下表现更好
- 在复杂查询和大数据量处理方面,PostgreSQL的性能通常优于MySQL
- JGit核心概念
- Jgit项目
-
25.08.01
- 代码随想录
- 组合计数
- 先遍历数组则为完全背包问题(不考虑顺序)
- 先遍历目标值就是组合问题(考虑顺序)
- 组合计数
- Maven的依赖管理,如果出现了A依赖B和C,然后C依赖B会怎么样
- 当A依赖B和C,而C又依赖B时,Maven会通过依赖传递机制来处理这种情况。具体来说,Maven会构建一个依赖树,然后根据一些规则来决定最终使用哪个版本的B。 首先,Maven会按照"最近优先"的原则来处理。在这个场景中,A直接依赖B,而C也依赖B,那么A到B的路径是A→B,A到C到B的路径是A→C→B。显然A→B的路径更短,所以Maven会优先选择A直接依赖的B版本。
- 但是实际情况可能更复杂一些。比如如果A依赖B的1.0版本,C依赖B的2.0版本,这时候Maven会通过依赖调解机制来解决冲突。Maven有几种调解策略,默认是"第一声明优先",也就是在pom.xml中先声明的依赖会优先。
- 我们项目中就遇到过类似的情况。比如我们的common模块依赖了hessian,client模块也依赖了hessian,同时client还依赖了common模块。 这时候Maven会确保整个项目使用同一个hessian版本,避免类加载冲突。
- 另外,Maven的dependencyManagement也是一个很重要的机制。在父pom中定义版本号,子模块就可以直接引用而不需要指定版本, 这样就能统一管理依赖版本,避免版本冲突。
- 总的来说,Maven的依赖管理机制是通过依赖树、依赖传递、依赖调解和dependencyManagement等多种方式来确保项目中依赖的正确性和一致性。
- 访问www.baidu.com的时候用到什么缓存
- 浏览器缓存:通过
Cache-control头控制缓存静态资源 - DNS缓存:浏览器会缓存域名解析结果,减少DNS查询次数
- CDN缓存:如果使用了CDN加速,CDN会缓存静态资源,减少源站压力
- 服务端缓存:如果服务端配置了缓存策略,可能会缓存动态内容
- 数据库缓存:如果访问的内容涉及数据库查询,可能会使用Redis、Memcached等缓存热点数据,比如热搜词、用户信息等
- HTTP缓存:浏览器会缓存HTTP响应头中的
ETag和Last-Modified,用于条件请求,减少不必要的数据传输
- 浏览器缓存:通过
Redis:String和Hash的区别,为什么购物车不用String- 从存储结构来看,
String是简单的key-value结构,而Hash是key-field-value的三层结构。比如存储用户信息, 用String的话可能是"user:1"对应一个JSON字符串,而用Hash的话是"user:1"下面有多个field,比如"name"、"age"、"email"等。 - 购物车不用String而选择Hash,主要有几个原因。
- 第一个是部分更新效率。购物车经常需要添加商品、修改数量、删除商品等操作。如果用String存储,每次修改都需要序列化整个购物车数据, 然后重新写入。而用Hash的话,可以只更新某个商品的字段,比如"cart:user123"下面的"product:456"字段,这样效率就高很多。
- 第二个是内存使用效率。Hash在存储小对象时比String更节省内存。因为String存储JSON时会有很多重复的字段名,而Hash的field名是共享的, 不会重复存储。比如购物车有100个商品,用String存储会有100个"price"、"quantity"这样的字段名,而Hash只需要存储一次。
- 第三个是原子性操作。Hash提供了很多原子操作,比如HINCRBY可以原子地增加某个商品的数量,HGETALL可以原子地获取整个购物车。 如果用String的话,需要先读取、修改、再写入,这个过程中可能会有并发问题。
- 第四个是查询效率。购物车经常需要查询某个商品的信息,用Hash可以直接用HGET获取特定商品,而用String需要先GET整个字符串, 然后解析JSON,再找到对应的商品,效率明显低很多。
- 从存储结构来看,
Redis:为什么哈希槽为16384- CRC16算法产生的哈希值是16bit的,最大可以产生65536个哈希值
- redis节点发送心跳包需要包含哈希槽信息,使用16bit的哈希值会导致心跳包过大,所以为了节省内存网络开销,redis将哈希槽数量限制为16384
- 哈希槽如果太小,会导致哈希冲突严重
Redis: cluster集群如果实例上没有相应的数据会怎样杨- Moved重定向:哈希槽计算重新转移到其他节点
- Ask重定向:发生数据迁移时吗,重定向
- 代码随想录
-
25.08.03
- IO模型
- 首先是阻塞IO,这是最传统的模型。当应用调用read或者write这些系统调用时,线程会被阻塞,直到数据准备好或者操作完成。这种模型实现简单,但是效率比较低,因为一个线程只能处理一个连接,如果要处理大量并发连接就需要创建大量线程,而线程的创建和切换开销都很大。
- 然后是非阻塞IO,在这种模型下,系统调用不会阻塞,而是立即返回。如果数据还没准备好,就返回一个错误码,应用需要不断轮询来检查数据是否准备好。这种模型虽然不会阻塞线程,但是轮询会消耗大量CPU资源,效率也不高。
- 第三种是IO多路复用,这是现在比较常用的模型。通过select、poll、epoll这些系统调用,一个线程可以同时监听多个文件描述符。当某个文件描述符就绪时,系统会通知应用,应用再去处理对应的IO操作。这样就能用一个线程处理多个连接,大大提高了并发处理能力。
- 异步IO模型是最高效的,在这种模型下,应用发起IO请求后立即返回,当IO操作完成时,系统会通过回调函数或者信号来通知应用。这样应用线程完全不会被阻塞,可以去做其他事情。
- 在Java中,我们主要用的是NIO,它底层就是基于IO多路复用的。通过Selector可以同时监听多个Channel,当Channel就绪时,Selector会通知我们,然后我们再去处理对应的IO操作。这样就能用一个线程处理多个连接,实现高并发。 当然还有Netty这样的框架,它在NIO基础上做了很多优化,比如零拷贝、内存池、事件驱动模型等等,让网络编程变得更加高效和易用。
- Selete,Poll和Epoll的区别
select是最早的IO多路复用模型,它通过一个文件描述符集合来监听多个文件描述符的状态变化。当有文件描述符就绪时,应用可以通过遍历集合来处理对应的IO操作。select的缺点是每次调用都需要遍历整个集合,效率较低,并且有最大文件描述符数量限制(通常是1024)。poll是对select的改进,它使用一个数组来存储文件描述符和事件类型,避免了select的最大限制问题。poll的效率比select高,但是仍然需要遍历整个数组。epoll是Linux特有的IO多路复用模型,它使用事件驱动的方式来处理文件描述符。当有文件描述符就绪时,内核会通知应用,而不是让应用去轮询,在内核里使用红黑树来关注进程所有待检测的Socket。epoll支持边缘触发和水平触发两种模式,可以大大提高性能。epoll还支持注册和注销文件描述符,避免了每次调用都需要重新设置的问题。
- 水平触发(Level Triggered)和边缘触发(Edge Triggered)的区别
- 水平触发:当文件描述符的状态满足条件时,内核会一直通知应用,直到应用处理完毕。这种模式比较简单,适合大多数场景。
- 边缘触发:当文件描述符的状态发生变化时,内核只会通知一次,之后需要应用主动去处理。这种模式效率更高,但需要应用更小心地处理状态变化。
- 算法题: 模拟LRU缓存
- LRU(Least Recently Used)缓存是一种常用的缓存淘汰策略,主要用于限制缓存的大小,淘汰最久未使用的数据。
class LRUCache { // 双向链表节点 class DLinkedNode { int key; int value; DLinkedNode prev; DLinkedNode next; public DLinkedNode() {} public DLinkedNode(int key, int value) { this.key = key; this.value = value; } } private Map<Integer, DLinkedNode> cache = new HashMap<>(); private int size; private int capacity; private DLinkedNode head, tail; public LRUCache(int capacity) { this.size = 0; this.capacity = capacity; // 使用虚拟头尾节点 head = new DLinkedNode(); tail = new DLinkedNode(); head.next = tail; tail.prev = head; } public int get(int key) { DLinkedNode node = cache.get(key); if (node == null) { return -1; } // 如果key存在,先通过哈希表定位,再移到头部 moveToHead(node); return node.value; } public void put(int key, int value) { DLinkedNode node = cache.get(key); if (node == null) { // 如果key不存在,创建一个新节点 DLinkedNode newNode = new DLinkedNode(key, value); // 添加进哈希表 cache.put(key, newNode); // 添加至双向链表的头部 addToHead(newNode); ++size; if (size > capacity) { // 如果超出容量,删除双向链表的尾部节点 DLinkedNode tail = removeTail(); // 删除哈希表中对应的项 cache.remove(tail.key); --size; } } else { // 如果key存在,先通过哈希表定位,再修改value,并移到头部 node.value = value; moveToHead(node); } } private void addToHead(DLinkedNode node) { node.prev = head; node.next = head.next; head.next.prev = node; head.next = node; } private void removeNode(DLinkedNode node) { node.prev.next = node.next; node.next.prev = node.prev; } private void moveToHead(DLinkedNode node) { removeNode(node); addToHead(node); } private DLinkedNode removeTail() { DLinkedNode res = tail.prev; removeNode(res); return res; } }
- 索引是否越多越好,有什么问题
- 先是存储空间,每个索引都需要额外的存储空间。比如一个表有100万行数据,如果建了10个索引,每个索引可能都要占用几GB的空间,这样整个表的存储空间就会翻好几倍。
- 其次是写入性能,每次插入、更新、删除数据时,MySQL都需要维护所有的索引。比如插入一条数据,如果有10个索引,MySQL就要更新10次索引结构,这样写入性能就会明显下降。特别是B+树索引,每次更新都可能涉及到节点的分裂和合并,开销比较大。
- 还有就是查询优化器的负担,当表有很多索引时,优化器需要分析更多的执行计划。比如一个查询可能涉及多个字段,优化器要考虑是用索引A还是索引B,或者要不要用复合索引,这样会增加查询计划生成的时间。
- 还有一个问题是维护成本,索引越多,数据库维护的工作量就越大。比如重建索引、更新统计信息这些操作,索引越多耗时就越长。
- 在实际项目中,我通常会遵循一些原则。比如只为经常用于查询条件的字段建立索引,特别是WHERE子句、JOIN条件、ORDER BY、GROUP BY这些地方用到的字段。对于很少查询的字段,就不建索引。
- 还有就是考虑复合索引,如果经常同时查询多个字段,可以建立复合索引而不是单独为每个字段建索引。复合索引的顺序也很重要,要把选择性高的字段放在前面。
- 实现类似英雄联盟的进度条机制,等待所有玩家加载完成后开启游戏,应该用juc下的什么实现
- CountDownLatch非常适合这种场景,它的核心思想是等待一组线程完成某个操作。具体实现是这样的,创建一个CountDownLatch,计数器初始化为玩家数量。每个玩家加载完成后调用countDown()方法,计数器减1。主线程调用await()方法等待所有玩家加载完成。
- 还可以用CyclicBarrier来实现,它的特点是计数器可以重置,适合多轮游戏场景。但是CountDownLatch更适合这种一次性的等待场景。
- 僵尸进程
- 僵尸进程是指子进程已经结束,但其父进程没有调用wait()或waitpid()来获取子进程的退出状态,导致子进程的资源没有被回收。
- 解决方法是父进程在适当的时候调用wait()或waitpid()来回收子进程资源,或者在父进程中设置SIGCHLD信号处理函数,当子进程结束时自动回收资源。
- 在Linux中,可以通过
ps aux | grep Z命令查看僵尸进程,僵尸进程的状态标识为Z。
- 场景题:给定一个4TB的文件,文件每行为一个int32整数。你有一个有2GB内存的设备,并给你一个随机的int32整数,你该如何判断该整数是否存在与文件中?你的方法需要占用多少内存?
- 4TB的文件包含int32整数,每个int32占4字节,加上换行符,大约每行5字节。所以文件大约包含8000亿个整数。 如果直接用哈希表存储,需要8000亿个int32,大约需要3.2TB内存,显然2GB内存不够。
- 我推荐使用位图(bitMap)解决,为每个int32数设置标志位,如果存在则置1。
- 位图需要2^32个bit位来表示所有可能的int32值 2^32 bit = 2^29 byte = 512MB
- Mysql为什么不可以给不存在的记录加记录锁
- 因为行级锁是加载在索引上的,数据不存在也就不存在索引,自然没办法加记录锁
- Mysql如何避免死锁
- IO模型
-
25.08.06
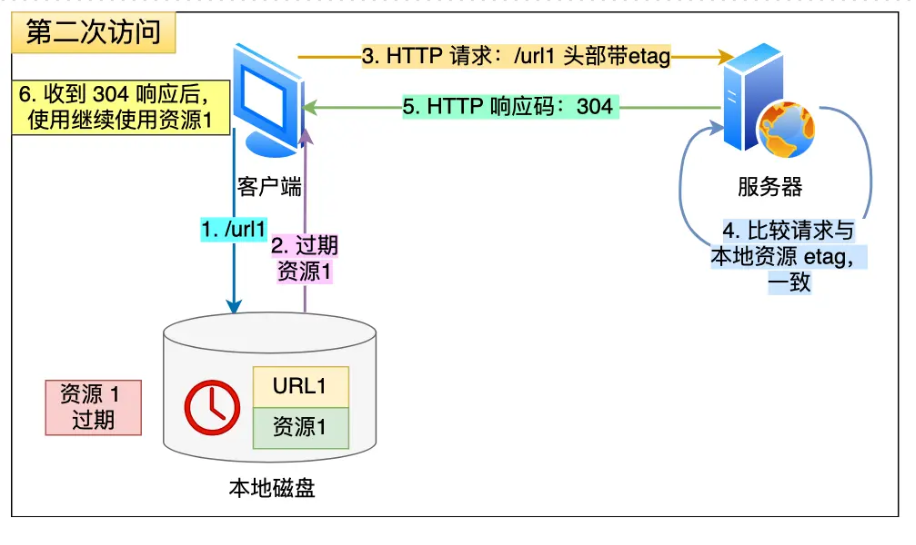
- HTTP缓存方式
- 强制缓存
- 协商缓存(304协商重定向状态码)
- 安全验证
- 哈希值校验:确保消息没有被修改
- 数字签名:保证消息的来源可靠性(能确认消息是由持有私钥的一方发送的)
- 数字证书:校验公钥的身份验证(依赖第三方CA机构)
- TLS1.2四次握手RES的缺点
- 所有数据传输都是相同的密钥加密,一旦服务器的私钥被获取,前面的所有通信都会被破解(不具有前向保密性)
- 解决方法:使用ECDHE算法做握手协议(TLS1.3 椭圆曲线)
- 为什么有了HTTP协议还要有RPC协议
- RPC又叫远程过程调用,它本身并不是一个协议,他的实现方法例如gRPC,thrift才是具体的协议。在早期, Http用于B/S架构,RPC用于C/S架构。而现在两者区分度不是很高,所以一般对外通信都是用HTTP,RPC用于微服务之间的相互调用。
- HTTP用JSON序列化,RPC用体积更小的 Protobuf 或其他序列化协议去保存结构体数据。
- 此外,它本质上就是个泛指调用远程函数的概念,很多框架依旧可以基于高性能的HTTP/2或3去实现新的RPC框架。
- HTTP缓存方式
-
25.08.08
- 代码随想录
- 虚拟内存
- 虚拟内存可以使得进程对运行内存超过物理内存大小,因为程序运行符合局部性原理,CPU访
问内存会有很明显的重复访问的倾向性,对于那些没有被经常使用到的内存,我们可以把它换出到物理
内存之外,比如硬盘上的swap区域。
- 时间上: TLB(传输旁路缓存) 记录最常使用的内存空间
- 空间上:多级页表 不是所有一级页表都会有二级页表
- 由于每个进程都有自己的页表,所以每个进程的虚拟内存空间就是相互独立的。进程也没有办法 访问其他进程的页表,所以这些页表是私有的,这就解决了多进程之间地址冲突的问题。
- 页表里的页表项中除了物理地址之外,还有一些标记属性的比特,比如控制一个页的读写权限, 标记该页是否存在等。在内存访问方面,操作系统提供了更好的安全性。
- 虚拟内存可以使得进程对运行内存超过物理内存大小,因为程序运行符合局部性原理,CPU访
问内存会有很明显的重复访问的倾向性,对于那些没有被经常使用到的内存,我们可以把它换出到物理
内存之外,比如硬盘上的swap区域。
- 线程崩溃了,进程一定崩溃吗
- 不一定,JAVA中线程崩溃就不会导致进程崩溃
- 一般来说,线程访问非法越界内存的时候就会崩溃,因为线程是共享资源的,操作系统怕内存的不确定性影响到 其他线程,就会让线程崩溃
- 线程崩溃后,会发出信号,进程收到操作系统发的信号,CPU 暂停当前程序运行,并将控制权转交给操作系统
- 操作系统根据情况执行相应的信号处理程序(函数),一般执行完信号处理程序逻辑后会让进程退出
- 但是,信号处理程序可以自定义,JVM 自定义了自己的信号处理函数,拦截了 SIGSEGV 信号,针对这两者不让它们崩溃。
- 传输文件
- 小文件用零拷贝技术
- 大文件用异步IO + 直接IO(不走pageCache)
- Reactor与Proactor模式
- Reactor -- 同步非阻塞
- 分为单/多reactor 单/多线程/进程
- 主Reactor -- 从reactor -- Acceptor(建立连接) -- handler -- processor(逻辑处理)
- Proactor -- 异步IO
- 相比与Reactor,减少了从内核态到用户态拷贝数据的同步操作,相当于对已完成的IO事件处理
- 真正的异步 I/O 是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程都不用等待。
- Reactor -- 同步非阻塞
- 一致性哈希(负载均衡的一种策略)
- 使得相同的数据一直落在同一个节点上
- 避免添加或移除节点时数据的大量迁移 -- 将「存储节点」和「数据」都映射到一个首尾相连的哈希环(2^32-1)上,如果增加或者移除一个节点,仅影响该节点在哈希环上顺时针相邻的后继节点,其它数据也不会受到影响。
- 引入虚拟节点 -- 每个真实节点对应多个虚拟节点,虚拟节点均匀分布在哈希环上,避免数据倾斜,提高节点的均衡度
-
25.08.09
- Redis大key删除
- lazyFree线程可以异步释放内存
- 使用unlink命令由lazyFree线程删除,而不是用del命令阻塞主线程
- AOF重写
- AOF重写是为了减少AOF文件的大小,提高Redis的性能
- 重写过程是将当前内存中的数据重新写入一个新的AOF文件,旧的AOF文件会被替换掉
- 重写过程中,Redis会使用一个子进程(fork 写时复制)来执行,主进程继续处理客户端请求,避免阻塞,将这时的新写入更新到AOF 重写缓冲区
- 重写完成后,再将缓冲区的内容进行追加,然后覆盖原有AOF文件(类似JVM并发回收 + 最终回收)
- Redis Stream消息队列
- 相比于List,可以自动生成唯一全局ID,消费者确认机制,支持消费组
- 与专业消息队列差距
- 中间件可能丢失数据(AOF异步刷盘,主从复制宕机)
- 消息积压超过队列丢失数据(内存存储, 专业的消息队列它们的数据都是存储在磁盘上)
- Redis大key删除
-
25.08.10
- 索引下推
- 索引下推是指在查询时,先通过索引过滤掉不满足条件的行,然后再去表中查询剩余的行。这样可以减少不必要的表扫描,提高查询效率。
- 在存储引擎层根据索引条件判断是否需要读取行数据,而不是在Server层回表后判断(即使索引未命中也能使用)
- 执行一个SQL语句的过程
- 客户端发送SQL请求到MySQL服务器,建立连接
- 解释器解析SQL语句,进行词法分析和语法分析,生成解析树
- 预处理对
*进行展开,对别名进行替换 - 查询优化器生成执行计划,选择最优的执行路径(索引)
- 执行引擎根据执行计划执行查询(索引下推减少不满足搜索条件的回表操作)
- 字符集
- ASCII :1
- GBK:2
- UTF-8:1-4
- UTF-16:2-4
- UTF-32:4
- 联合索引的最左匹配原则,在遇到范围查询(如>、<)的时候,就会停止匹配,也就是范围查询的字段可以用到联合索引,但是在范围查询字段的后面的字段无法用到联合索引。注意,对于>=、<=、BETWEEN、like前缀匹配的范围查询,并不会停止匹配
- 索引下推
-
25.08.11
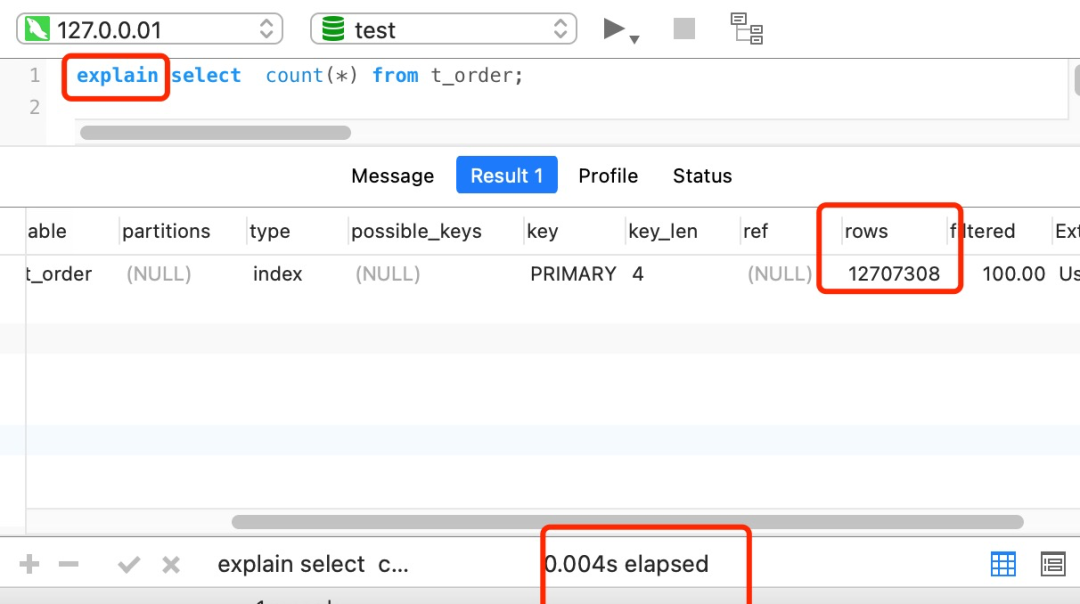
- count()性能
- count() 是一个聚合函数,函数的参数不仅可以是字段名,也可以是其他任意表达式,该函数作用是统计符合查询条件的记录中,函数指定的参数不为 NULL 的记录有多少个。
- count(*) = count(1) > count(主键) > count(字段)
- count(*)和 count(1)不需要查询字段值,只需要查询行数,所以性能最好。
- count(主键)需要查询主键字段的值,走索引,性能次之。
- count() 如果有二级索引,优先走二级索引(占空间小,IO成本低)
- 用大表查询count()性能可能会比较差,一般采用近似查询(explain)
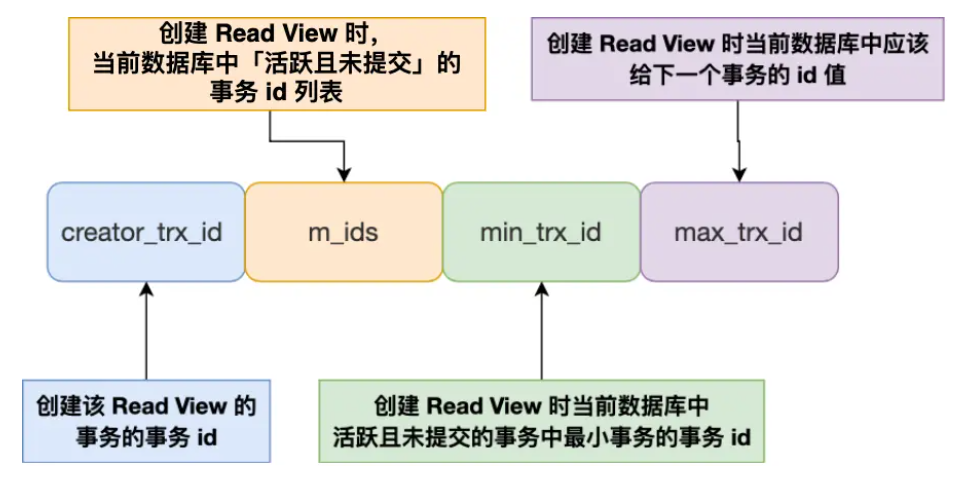
- Read View 在 MVCC 里如何工作的?
- 提交读(每条语句执行前创建)和可重复读(事务开启前创建)会用到 Read View
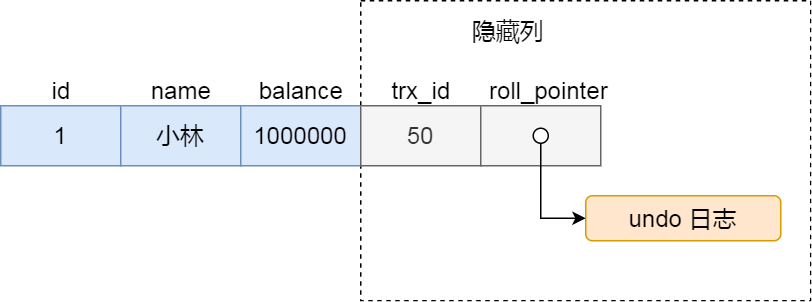
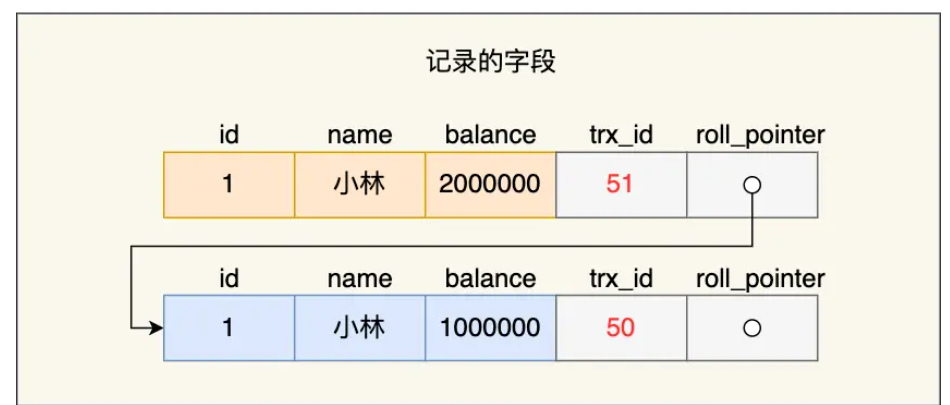
- 聚簇索引记录中的两个隐藏列
- trx_id: 记录最后一次被哪个事务修改
- roll_pointer: 指向回滚段的指针,用于获取该记录的历史版本(undo_log)
- 在可重复读+ MVCC下,仍可能出现幻读
- 对于快照读, MVCC 并不能完全避免幻读现象。因为当事务 A 更新了一条事务 B 插入的记录,那么事务 A 前后两次查询的记录条目就不一样了,所以就发生幻读
- 对于当前读,如果事务开启后,并没有执行当前读,而是先快照读,然后这期间如果其他事务务插入了一条记录,那么事务后续使用当前读进行查询的时候,就会发现两次查询的记录条目就不一样,发生幻读
- MDL锁(元数据锁)
- 保证当用户对表执行 CRUD 操作时,防止其他线程对这个表结构做了变更
- 对一张表进行 CRUD 操作时,加的是 MDL 读锁;
- 对一张表做结构变更操作的时候,加的是 MDL 写锁;
- 具体更新一条记录UPDATE t_user SET name ='xiaolin' WHERE id =1;的流程如下:
- undo_log - > redo_log - > binlog
- redo log 可以在事务没提交之前持久化到磁盘,但是 binlog 必须在事务提交之后才能持久化到磁盘
- 两阶段提交的问题
- 磁盘IO开销大,因为每个事务都要写两次日志
- 阻塞问题,事务在准备阶段会持有锁,直到提交阶段完成
- 解决方法:使用三阶段提交,增加一个预提交阶段
- flush 阶段队列的作用是用于支撑 redo log 的组提交
- sync 阶段队列的作用是用于支持 binlog 的组提交
- count()性能
-
25.08.13
- 为什么说java是编译性和解释性语言的结合
- 编译性:Java源代码首先被编译成字节码,JIT 会把编译过的机器码保存起来,以备下次使用。
- 解释性:JVM中一个方法调用计数器,当累计计数大于一定值的时候,就使用JIT进行编译生成机器码文件。否则就是用解释器进行解释执行,然后字节码也是经过解释器进行解释运行的。
- GCRoot
- 虚拟机栈中引用的对象
- 本地方法栈中引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
- 为什么说java是编译性和解释性语言的结合
-
25.08.14
- Nginx如何解决跨域问题
- 跨域是指浏览器的同源策略限制,当协议、域名、端口三者中任意一个不同时,就会产生跨域问题。这是浏览器的安全机制,不是服务器端的限制。
- Nginx可以通过设置CORS(跨域资源共享)头来解决跨域问题。在location块中添加Access-Control-Allow-Origin、Access-Control-Allow-Methods、Access-Control-Allow-Headers等头信息。这些头信息告诉浏览器允许跨域访问,以及允许的请求方法和请求头。
- 正确处理OPTIONS预检请求。当浏览器发送复杂请求时,会先发送一个OPTIONS请求来检查服务器是否允许跨域。nginx需要正确响应这个预检请求,设置相应的CORS头,并返回204状态码。如果预检请求失败,后续的实际请求也会失败。
- 表达式计算为什么会使索引失效
- 表达式计算导致索引失效的根本原因是MySQL无法在索引中直接查找计算后的结果。索引存储的是列的原始值,而表达式计算会改变这些值,使得MySQL无法利用索引的有序性和快速查找特性。
- where 条件 in(10个数) 和exists 谁更快
- 外表的行数少,in更快(走外表的索引)
- 外表的行数多,exists更快(走内表的索引)
- 如果外表的行数和内表的行数都很大,in和exists性能差不多
- 对于not in和not exists
- 如果查询语句使用了not in那么内外表都进行全表扫描,没有用到索引;而not exist的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快
- 线程池动态调整参数和队列持久化,自己做过用过没
- 线程池动态调整参数 *通过JMX(Java Management Extensions)暴露了线程池的核心参数。创建了一个继承自ThreadPoolExecutor的可监控线程池类,重写了setCorePoolSize、setMaximumPoolSize等方法,在这些方法中增加了参数验证和日志记录。同时,我们实现了ThreadPoolMXBean接口,将线程池的关键指标暴露给JMX,包括当前活跃线程数、队列大小、已完成任务数等。 这样运维人员就可以在运行时通过JConsole来调整这些参数。
- 队列持久化
- 线程池的任务队列使用了RocketMQ作为持久化存储。每当有新任务提交时,将任务序列化后存入RocketMQ的列表中。当线程池空闲时,定时从Redis中拉取任务并执行,执行完成后返回确认,从消息队列中移除消息。这样即使应用重启,任务也不会丢失。
- 本地测试没问题,上线之后出问题了,怎么排查是哪方面的问题
- 最常见的问题是环境差异导致的。有一次我们的系统在本地测试完全正常,但上线后出现了数据库连接超时的问题。经过排查发现,本地环境使用的是本地数据库,连接很快,而上线环境使用的是云数据库,网络延迟较高。我们的连接超时时间设置得太短,在本地测试时根本不会触发,但在生产环境就暴露出来了。
- 首先,我会检查系统日志,包括应用日志、系统日志、数据库日志等。日志中通常会包含错误信息和异常堆栈,这是最直接的线索。比如刚才提到的数据库连接问题,就是在日志中发现了大量的连接超时异常。
- 其次,我会对比本地环境和生产环境的配置差异。包括数据库连接参数、JVM参数、系统环境变量、依赖版本等。有时候问题就出在这些配置上,比如本地使用的是MySQL 8.0,而生产环境使用的是MySQL 5.7,某些SQL语法在低版本中不支持。
- 第三,我会检查生产环境的资源情况。包括CPU使用率、内存使用率、磁盘空间、网络带宽等。有一次我们的系统上线后响应很慢,排查发现是生产服务器的内存不足,导致频繁的垃圾回收,影响了系统性能。
- 第四,我会分析生产环境的数据特点。本地测试通常使用的是少量测试数据,而生产环境可能有大量的真实数据。数据量的差异可能导致某些算法或查询的性能问题。比如本地测试时数据库表只有几百条记录,查询很快,但生产环境有几十万条记录,同样的查询就变得很慢。
- 第五,我会检查网络环境。本地测试通常是在局域网内,网络延迟很低,而上线后可能涉及跨地域、跨运营商的网络访问。网络延迟、丢包、带宽限制等问题都可能影响系统性能。
- 第六,我会分析并发情况。本地测试通常是单用户测试,而上线后可能有大量用户同时访问。并发访问可能导致资源竞争、死锁、内存泄漏等问题。比如本地测试时线程池工作正常,但上线后高并发访问导致线程池队列积压,最终导致系统响应缓慢。
- 第七,我会检查第三方服务的依赖。本地测试时可能使用的是测试环境的第三方服务,而上线后使用的是生产环境的第三方服务。第三方服务的性能、稳定性、接口差异等都可能导致问题。
- 具体的排查工具和方法,我通常会使用以下几种。首先是日志分析工具,比如ELK Stack(Elasticsearch、Logstash、Kibana),可以集中收集和分析日志。其次是监控工具,比如Prometheus + Grafana,可以实时监控系统的各种指标。再次是性能分析工具,比如JProfiler、MAT(Memory Analyzer Tool)等,可以分析JVM的性能和内存使用情况。
- 对于数据库问题,我会使用慢查询日志、执行计划分析、连接池监控等工具。对于网络问题,我会使用ping、telnet、traceroute等命令来诊断网络连通性和延迟。对于系统资源问题,我会使用top、iostat、netstat等命令来监控系统状态。
- 还有一个重要的排查思路是灰度发布和回滚。当我们发现问题后,可以先将流量切回到旧版本,然后逐步分析问题。这样可以避免问题影响所有用户,同时给我们足够的时间来排查和修复问题。
- 线上sql执行很慢是如何排查的
- 首先,我会检查慢查询日志,找出执行时间较长的SQL语句。通过分析这些SQL语句,可以初步判断是查询条件不合理、缺少索引还是数据量过大等问题。
- 其次,我会使用EXPLAIN命令查看SQL的执行计划。执行计划可以告诉我们MySQL是如何执行这条SQL的,包括使用了哪些索引、扫描了多少行数据等。通过分析执行计划,可以发现是否存在全表扫描、索引未命中等问题。
- 索引问题(索引失效、回表查询)
- 锁等待问题(长事务、锁粒度)
- 系统资源问题(CPU、内存、磁盘IO、网络带宽)
- 数据分布问题(表结构、分库分表)
- 深度分页问题(子查询、连续翻页)
- Nginx如何解决跨域问题
-
25.08.16
- SQL语句
- SQL语句的执行顺序是:FROM -> JOIN -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY -> LIMIT
- Group By 要包含在 Select 中的所有非聚合字段,否则会报错
- SQL语句
-
25.08.17
- ConcurrentHashMap实现大小获取的size()函数是怎么实现的
- 通过sumCount()方法设置了volatile修饰的baseCount变量和countCells数组来计算size,当执行put()或remove()方法时,会通过CAS更新baseCount,如果失败则会添加到countCells数组中。
- 计算size()时,会先获取baseCount的值,然后遍历countCells数组,累加每个cell的值。
- 回答下对于AI的看法
- AI的本质是通过大量数据训练模型,提取出数据中的模式和规律,然后用这些模式来生成新的内容或做出决策。
- AI的优势在于它可以处理海量数据,快速找到规律,并且可以自动化完成很多重复性工作。
- 从技术角度来说,AI确实给软件开发带来了很多变化。比如代码生成、自动化测试、性能优化等方面,AI工具能大大提高开发效率。像GitHub Copilot这样的工具,在写一些模板代码或者重复性代码时确实很有帮助。但是我觉得AI目前还无法完全替代程序员的思考。编程不仅仅是写代码,更重要的是理解业务需求、设计架构、解决复杂问题。AI可能在代码层面提供帮助,但在系统设计、性能调优、问题排查等核心能力上,还是需要程序员的经验和判断。
- 从职业发展角度,我觉得程序员需要拥抱AI,把它当作工具来使用,而不是威胁。比如用AI来写单元测试、生成文档、优化SQL等,这样可以让我们把更多精力放在更有价值的工作上。不过我也担心AI可能带来的一些问题。比如过度依赖AI可能导致编程能力退化,或者AI生成的代码可能存在安全隐患。所以我觉得关键是要保持学习能力,理解AI工具的原理和局限性。
- 从行业角度,AI确实会改变一些低端编程工作的需求,但高端的系统设计、架构优化、问题解决等能力仍然稀缺。我觉得程序员应该专注于提升这些核心能力,同时学会利用AI工具提高效率。
- 总的来说,我认为AI是工具,不是替代品。关键是要找到AI和人类能力的结合点,让AI处理重复性工作,人类专注于创造性工作。
- 讲一下RAG
- RAG是Retrieval-Augmented Generation的缩写,中文叫检索增强生成,是AI领域的一个热门技术。
- 简单来说,RAG就是结合了信息检索和文本生成的技术。传统的AI模型,比如GPT,只能基于训练时的知识来回答问题,如果问一些训练数据中没有的信息,比如最新的新闻或者特定的文档内容,AI就回答不上来或者会编造答案。
- RAG解决了这个问题。它的工作流程是这样的:首先,当用户提问时,系统会先从知识库中检索相关的文档或信息片段;然后,把这些检索到的信息作为上下文,一起输入给AI模型;最后,AI模型基于检索到的信息来生成答案。
- 这样有几个好处:一是答案更准确,因为是基于真实信息生成的;二是可以处理训练数据中没有的新信息;三是可以引用具体的文档来源,提高可信度。
- 在实际应用中,RAG有很多场景。比如客服系统,可以把产品手册、FAQ等文档作为知识库,AI就能准确回答用户问题。再比如企业内部的知识管理系统,员工可以问各种业务问题,AI基于公司内部文档来回答。
- 技术实现上,RAG主要包含三个部分:检索器、生成器和知识库。检索器负责从知识库中找到相关文档,可以用向量数据库、倒排索引等技术;生成器就是大语言模型,负责生成答案;知识库存储各种文档和知识。
- 不过RAG也有一些挑战,比如检索的准确性、知识库的更新维护、检索和生成的协调等。如果检索不到相关信息,或者检索的信息不准确,最终生成的答案质量也会受影响。
- 讲一下Agent
- Agent是AI领域的一个概念,中文叫智能体或者代理。简单来说,Agent就是一个能够自主执行任务的AI系统。 传统的AI模型,比如ChatGPT,主要是对话式的,用户问什么就回答什么。但Agent不一样,它可以主动规划、执行、监控任务,就像一个虚拟的助手或者员工。 Agent的核心能力包括几个方面:一是感知能力,能够理解用户的需求和外部环境;二是规划能力,能够把复杂任务分解成多个步骤;三是执行能力,能够调用各种工具和API来完成具体操作;四是学习能力,能够从执行结果中总结经验,改进策略。 举个例子,比如用户说"帮我订一张明天去北京的机票",传统的AI可能只是提供一些订票建议。但Agent会主动执行:先查询明天的航班信息,然后比较价格和时间,选择合适的航班,最后完成订票操作。整个过程不需要用户一步步指导。 在实际应用中,Agent有很多场景。比如客服Agent,可以自动处理用户的咨询、投诉、退款等请求;比如数据分析Agent,可以自动收集数据、清洗数据、生成报告;比如代码开发Agent,可以理解需求、设计架构、编写代码、测试部署。 技术实现上,Agent通常包含几个组件:任务规划器、工具调用器、状态管理器、学习模块等。任务规划器负责分解任务和制定执行计划;工具调用器负责调用各种外部API和服务;状态管理器负责跟踪任务执行进度;学习模块负责优化执行策略。 不过Agent也面临一些挑战,比如任务规划的准确性、工具调用的稳定性、错误处理的能力等。如果规划不当或者工具调用失败,整个任务可能就会失败。 从发展趋势看,Agent代表了AI从被动响应到主动服务的重要转变。未来可能会有更多复杂的任务由Agent来完成,比如项目管理、产品设计、市场分析等。
- 讲一下MCP
- MCP是Model Context Protocol的缩写,是OpenAI提出的一种协议标准,用于大语言模型与外部工具和服务的交互。
- 简单来说,MCP就是一个标准化的接口协议,让AI模型能够安全、高效地调用各种外部工具和服务。传统的AI模型,比如GPT,只能基于训练数据来回答问题,无法访问实时的外部信息或者执行具体的操作。
- ConcurrentHashMap实现大小获取的size()函数是怎么实现的
-
25.08.19
- 内存型数据库
- Redis
- Memcached
- Redis提供更加丰富的数据结构和持久化选项,而Memcached更专注于简单的键值存储。
- Redis支持AOF, RDB持久化,支持事务,支持多种数据结构(字符串、哈希、列表、集合、有序集合等),支持发布订阅、Lua脚本等功能。
- 内存型数据库
-
25.08.20
- RocketMQ和Kafka都是拉取模型
- RocketMQ和Kafka都是利用“长轮询”来实现拉模式。所谓的“长轮询”具体的做法都是通过消费者去Broker拉取消息时,当有消息的情况下Broker会直接返回消息,如果没有消息都会采取延迟处理的策略,即保持连接,暂时hold主请求,然后在对应队列或者分区有新消息到来的时候都会提醒消息来了,通过之前hold主的请求及时返回消息,保证消息的及时性。
- 如何实现订单超时取消
- RocketMQ会提供延迟消息功能,仅需在下单的时候发送一条延迟10分钟取消订单的消息。10分钟后,消费者会接受到这条消息,如果这条订单还未支付则取消订单,若已支付则忽略这条消息。可以看到这种方案不会对数据库产生压力,因为消息队列本身天然实现削峰填谷,消费者可以按照自己的能力来把控消费速率,并且可以横向扩展,通过加机器的方式加快消费速度。相对而言超时时间的控制能更精确,且对系统压力不大。
- JWT如何保证安全性,如何避免其他人获取你的token后就能直接使用
- 使用HTTPS加密传输,防止中间人攻击
- 在jwt的负载中加入ip地址,浏览器信息(UA)等,使用时比对
- 设置合理的过期时间,定期刷新token
- 设置黑名单
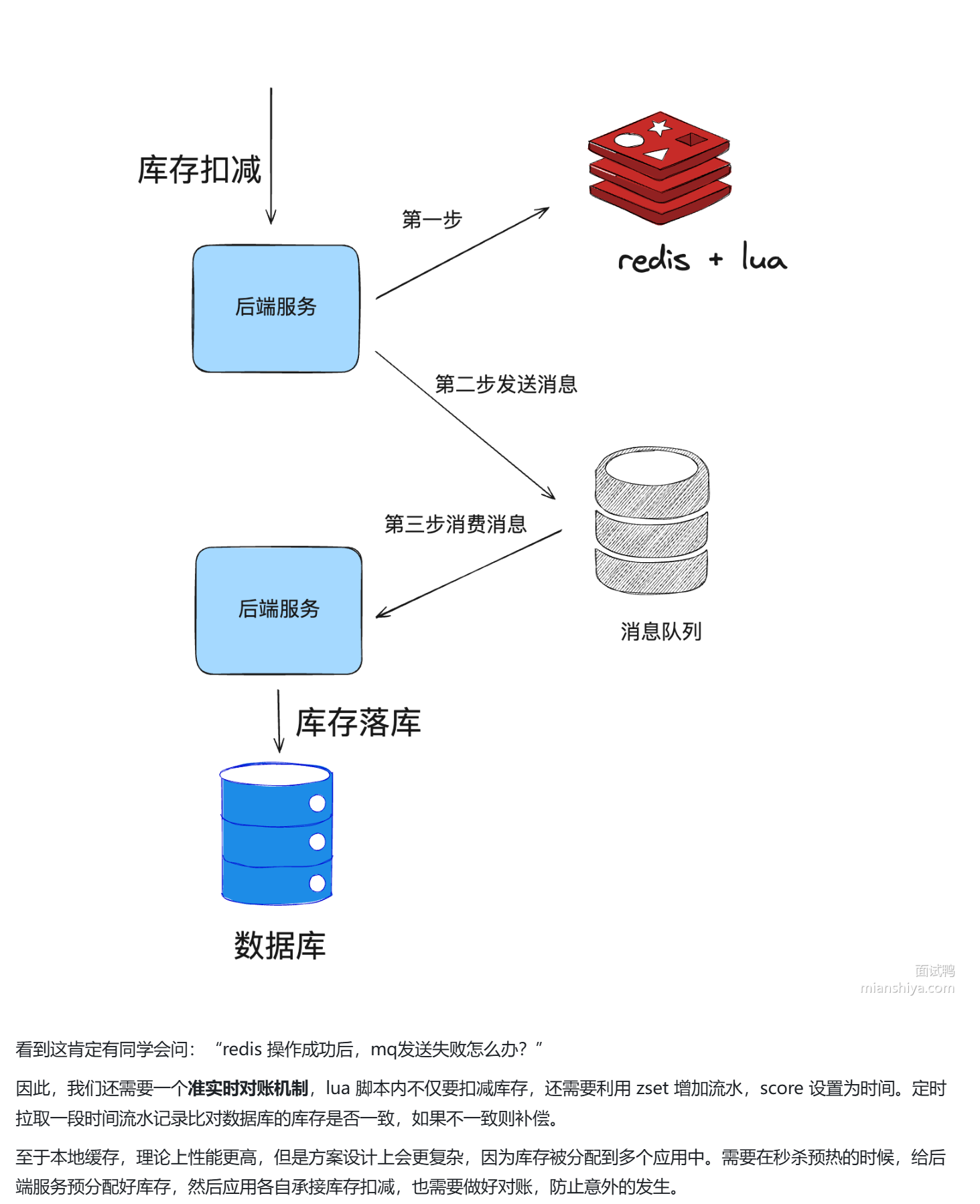
- 秒杀防止超卖
- 以redis数据为准,异步落库
- redis记录库存,用zset记录流水信息(超时时间),做定时准对账功能
- RocketMQ和Kafka都是拉取模型
-
25.08.22
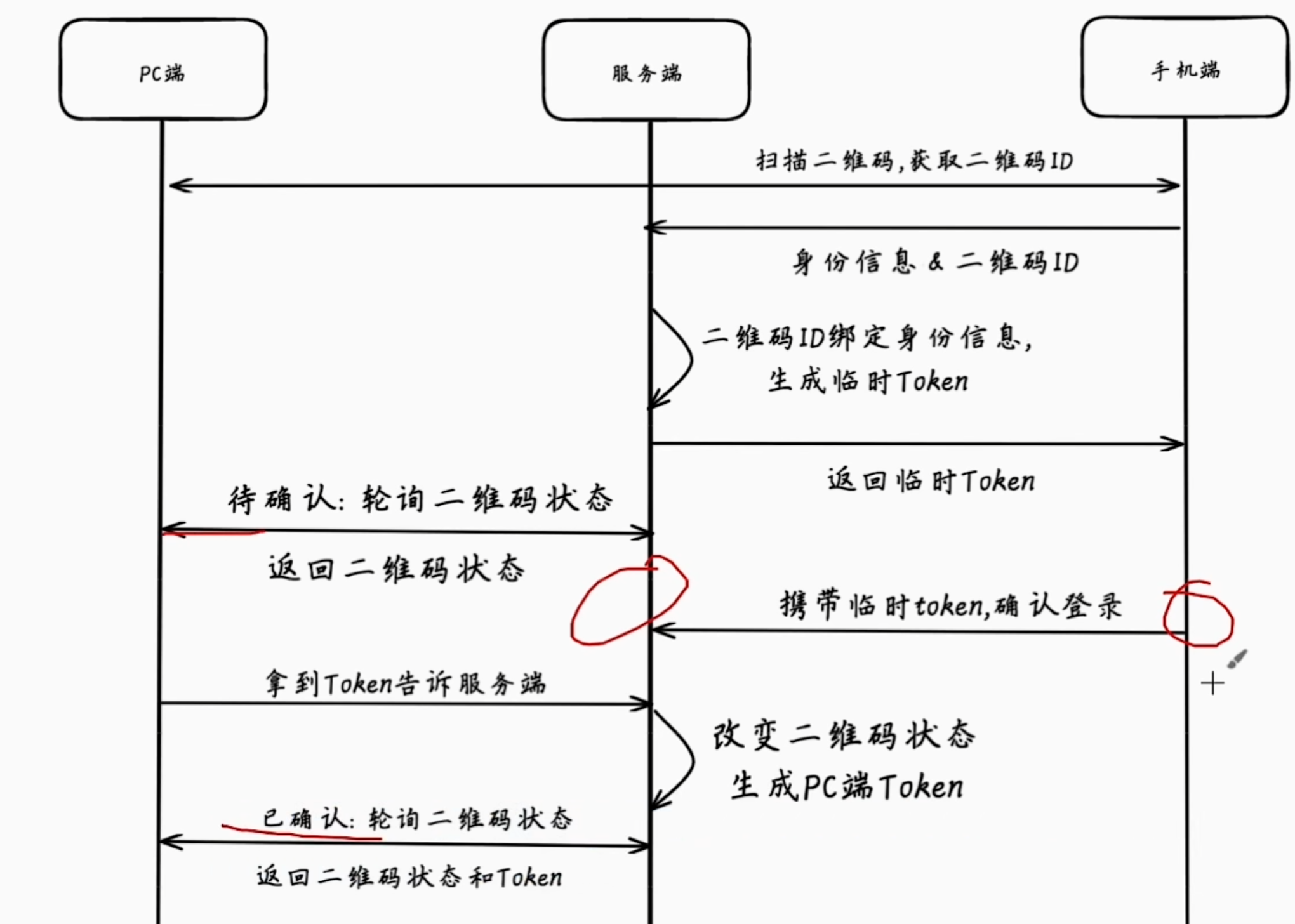
- 二维码登录的原理
- 大量消息堆积在MQ的解决方案
- 事前处理逻辑
- 预估请求量,根据压测结果和历史数据,合理配置消息队列的分区数和消费者数量
- 事中处理逻辑
- 请求量激增,使用k8s的弹性伸缩功能,动态增加消费者实例
- 事后处理逻辑
- 并行消费,使用多线程或多进程来提高消费速度
- 批量消费,使用批量拉取消息的方式来减少网络开销
- 优化消费逻辑,避免长事务
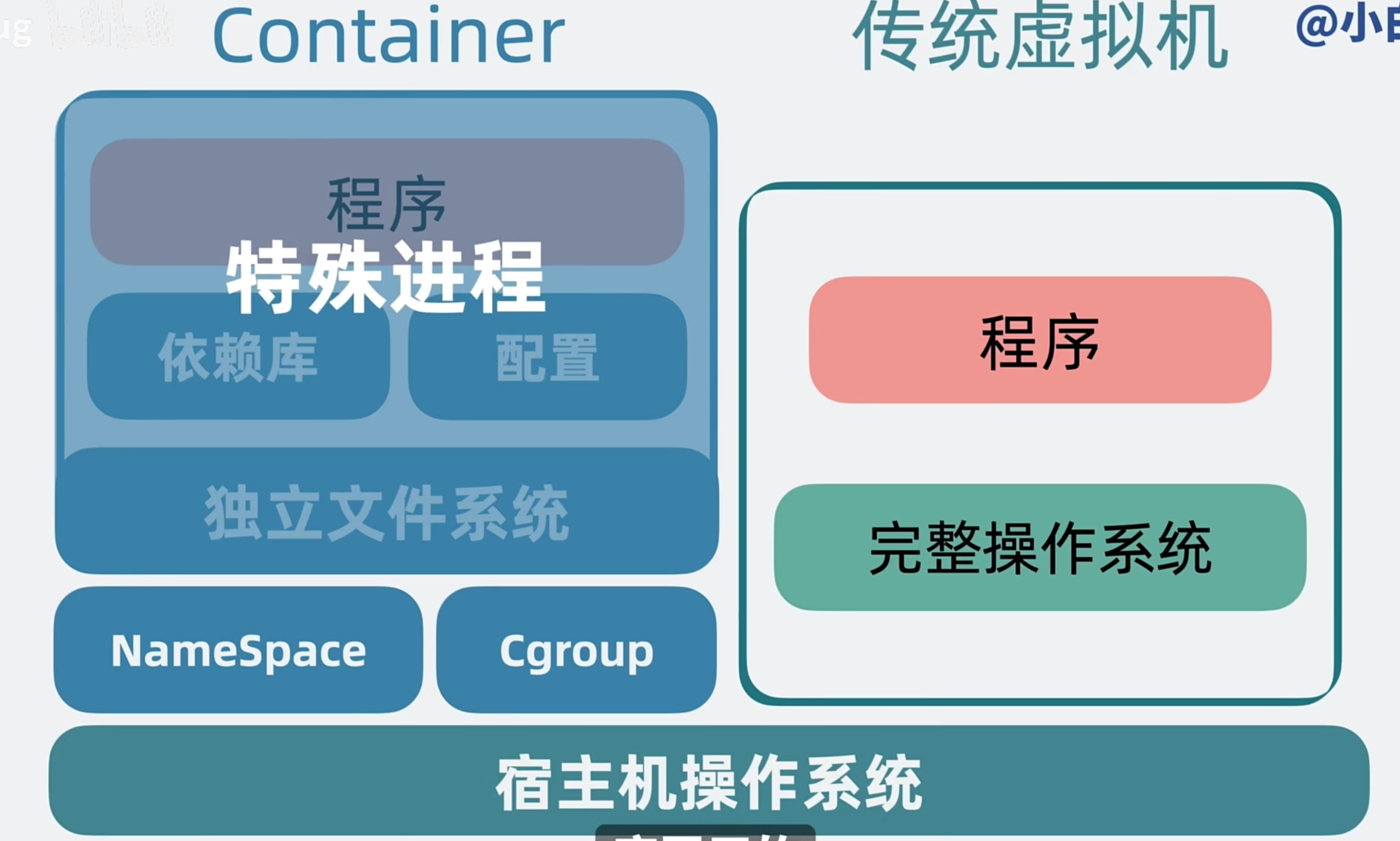
- 容器和传统虚拟机的区别
- 容器是轻量级的虚拟化技术,直接运行在宿主机的操作系统上,共享宿主机的内核和资源。相比传统虚拟机,容器启动更快,占用资源更少,适合微服务架构和云原生应用。
- docker和k8s的关系
- docker compose可以定义容器的启动顺序,其实就相当于k8s里的Pod
- k8s是容器编排工具,可以实现对pod中容器的管理、调度、扩缩容等功能。k8s可以看作是对docker的一个管理层,提供了更强大的功能和灵活性。
- 事前处理逻辑
- 二维码登录的原理
-
25.08.25
- TCP粘包怎么解决
- TCP粘包是指在TCP协议中,多个数据包被合并成一个数据包发送,接收端无法区分每个数据包的边界。
- 第一种是固定长度法,就是每条消息都使用固定的长度,比如每条消息都是100字节,不足的部分用0填充。这种方案实现简单,但是会造成空间浪费,而且如果消息长度超过固定长度,就需要额外的处理逻辑。
- 第二种是分隔符法,在每条消息后面加上特殊的分隔符,比如换行符"\n"或者自定义的分隔符"$$$"。服务端收到数据后,按照分隔符来分割消息。这种方案实现也比较简单,但是分隔符本身不能出现在消息内容中,否则会造成消息分割错误。
- 第三种是长度字段法,在消息前面加上消息长度的字段,比如用4个字节表示消息长度,后面跟着实际的消息内容。服务端先读取长度字段,然后根据长度读取对应的消息内容。这种方案比较灵活,可以处理变长消息,但是需要处理长度字段的字节序问题。
- 我在实际项目中采用的是长度字段法,因为我们的消息长度是变长的,而且需要处理二进制数据。具体实现时,我们先定义一个消息头结构,包含消息类型、消息长度、时间戳等字段,然后按照这个结构来解析消息。
- G1垃圾回收器的最小单元
- G1垃圾回收器的最小单元是Region(区域),每个Region的大小可以在1MB到32MB之间动态调整。G1将堆内存划分为多个Region,这些Region可以独立进行垃圾回收,从而提高了垃圾回收的效率和并发性。
- TCP粘包怎么解决
-
25.08.27
- Redis + Token 如何实现多设备同时登录同一账号
- 使用Redis的Hash数据结构。key是用户ID,field是设备标识(比如设备ID、设备类型等),value是对应的token信息。
- 基于活跃度的token续期机制,只有活跃的设备才能续期token,不活跃的设备token会逐渐过期。(记录最后活跃时间,活跃次数等)
- 在token中加入设备信息,比如设备ID、设备类型等,这样在验证token时可以同时验证设备信息,防止token被盗用。
- 在token中加入ip地址,当检测到ip地址变化时,要求二次验证。
- 设置最大登录设备数,比如限制同一账号最多允许5个设备同时登录,超过后需要踢掉最早登录的设备。
- 可以实现一个设备管理功能,用户可以在个人中心查看所有在线设备,包括设备类型、登录时间、最后活跃时间等信息,并且可以主动踢掉某个设备。这样既提高了用户体验,又增强了安全性。
- 线程之间什么是共享的
- 同一进程内的线程共享进程的内存空间 -> 全局变量、静态变量、堆内存 -> 线程安全问题
- 文件描述符,线程可以共享进程打开的文件。当主线程打开一个文件后,其他线程也可以访问这个文件,它们共享同一个文件偏移量。
- 信号处理器也是共享的,所有线程共享进程的信号处理函数。当进程收到信号时,会调用相应的处理函数,这个处理函数会在线程中执行。
- 网络连接也可以共享,比如数据库连接池、HTTP连接池等。多个线程可以从连接池中获取连接,使用完后归还给池,这样可以提高系统的并发性能。
- MySQL自增id的缺陷
- 当发生事务回滚、插入失败等情况时,自增ID会出现空缺,导致ID不连续。
- 分布式环境下,自增ID可能会出现冲突,需要额外的协调机制来保证唯一性。
- 数据迁移时,自增ID可能会重复,导致数据冲突。
- 自增ID暴露了数据的插入顺序,可能会泄露业务信息。
- 解决办法:使用雪花算法
- 雪花算法生成的ID是64位的长整型,包含时间戳、机器ID、序列号等信息,既保证了唯一性,又具有时间顺序性。
- Redis + Token 如何实现多设备同时登录同一账号
-
25.08.31
- RocksDB的读放大问题
- RocksDB的读放大问题主要是由于其多层次存储结构和数据压缩机制引起的。RocksDB将数据分为多个层次(Level),每个层次存储不同大小的数据文件。当读取数据时,可能需要访问多个层次的文件,导致读操作需要进行多次磁盘I/O,从而引发读放大问题。
- 具体来说,RocksDB使用了LSM树(Log-Structured Merge Tree)结构,数据首先写入内存中的MemTable,当MemTable满时,会将其刷新到磁盘形成一个新的SST文<++>件,这个过程称为Compaction。随着时间的推移,RocksDB会有多个SST文件分布在不同的层次上。当进行读操作时,RocksDB需要检查每个层次的SST文件,以找到所需的数据。如果数据分布在多个层次上,读操作就需要访问多个文件,增加了I/O开销。
- 解决方法
- 减少层次数:通过调整RocksDB的配置参数,减少层次的数量,可以降低读操作需要访问的文件数量,从而减少读放大。
- 优化Compaction策略:通过优化Compaction算法,减少不必要的数据移动和合并,可以降低读放大的影响。
- 使用Bloom Filter:RocksDB支持使用Bloom Filter来加速读操作,通过在每个SST文件中维护一个Bloom Filter,可以快速判断某个键是否存在于该文件中,从而减少不必要的文件访问。
- 调整数据布局:通过合理设计数据的存储布局,尽量将相关的数据存储在同一层次或相邻层次上,可以减少读操作需要访问的文件数量。
- 协程
- 协程是一种轻量级的用户态线程,它允许在单个线程内实现多任务并发。与传统的线程相比,协程具有更低的创建和切换开销,因为它们不需要操作系统的调度和上下文切换。
- java中的虚拟线程,由JVM管理,而不是操作系统管理。可以通过Thread.startVirtualThread()来创建,或者使用ExecutorService来管理。虚拟线程在执行I/O操作时会自动让出CPU,让其他虚拟线程执行,这样可以大大提高系统的并发性能。
- 堆内内存和堆外内存泄露的定位方法
- 堆内存泄露
- 使用JVM自带的工具,比如jmap、jstack、jvisualvm等,来生成堆内存快照(heap dump),然后使用Eclipse MAT(Memory Analyzer Tool)等工具来分析堆内存快照,找出占用内存较多的对象和引用链,从而定位内存泄露的原因。
- 通过代码审查,检查是否存在未关闭的资源(比如数据库连接、文件流等)、未注销的监听器、静态集合类等,这些都是常见的内存泄露源。
- 使用Java Profiler工具,比如YourKit、JProfiler等,来监控应用程序的内存使用情况,找出内存增长较快的对象和方法,从而定位内存泄露的原因。
- 堆外内存泄露
- 使用JVM参数-XX:+UnlockDiagnosticVMOptions -XX:+PrintNMTStatistics来启用Native Memory Tracking(NMT),这样可以监控JVM的堆外内存使用情况,并生成堆外内存快照,从而分析堆外内存泄露的原因。
- 检查是否存在JNI(Java Native Interface)代码中未释放的本地资源,比如本地内存分配、文件句柄、网络连接等,这些都是常见的堆外内存泄露源。
- 使用操作系统的工具,比如Linux下的pmap、top、vmstat等,来监控进程的内存使用情况,找出堆外内存增长较快的部分,从而定位堆外内存泄露的原因。
- 堆内存泄露
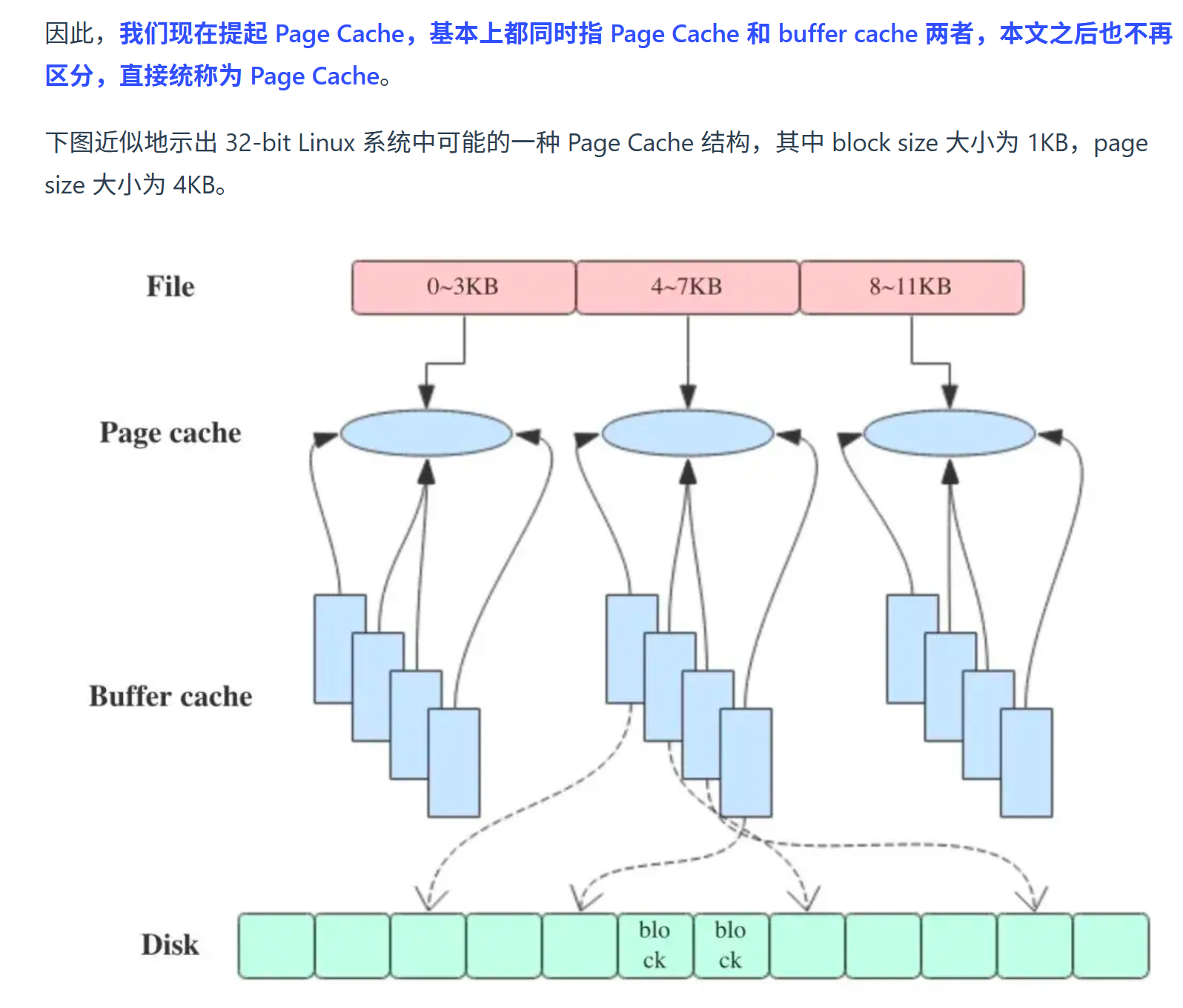
- PageCache和BufferCache
- 用一句话来解释:PageCache用于缓存文件的页数据,buffercache用于缓存块设备(如磁盘)的块数据。
- RocksDB的读放大问题