MRG: Simplify LCMV whitening #5979
Conversation
Codecov Report
@@ Coverage Diff @@
## master #5979 +/- ##
==========================================
+ Coverage 88.94% 88.94% +<.01%
==========================================
Files 401 401
Lines 72977 73011 +34
Branches 12132 12135 +3
==========================================
+ Hits 64912 64943 +31
- Misses 5183 5188 +5
+ Partials 2882 2880 -2 |
|
@wmvanvliet or @britta-wstnr can you do a first pass of review? |
 britta-wstnr
left a comment
britta-wstnr
left a comment
There was a problem hiding this comment.
Do we know whether lcmv without a noise cov matrix gives same answer here as it does in master? If not it might be good to ensure that - I can look at it tomorrow for example.
In principle it should and the tests still pass. But yes it would be good if you could test it and make sure. |
6e74a52 to
d7d50b4
Compare
|
Hi @larsoner I did a quick check of your branch against master.
I didn't have the time yet to track what exactly is happening, only looked at the outputs of sample data yet. Can you reproduce this? I might have more time tomorrow to have a more thorough look. |
That's a bit surprising. The |
|
... in other words / to express it numerically, on And it passes. |
|
I checked with |
|
Whoops, yes |
eafb8e1 to
71af0f3
Compare
|
Okay @britta-wstnr it still passes with the enhanced tests from #5984, this is ready for review/merge from my end. This makes it very close to being able to use |
|
@larsoner awesome - I would like to do another check beyond the implemented tests to examine what I found before, if that's okay. I can get to that tomorrow. |
|
Ping @britta-wstnr |
|
Reporting back: the order of magnitude in the output has def. changed:
This is with |
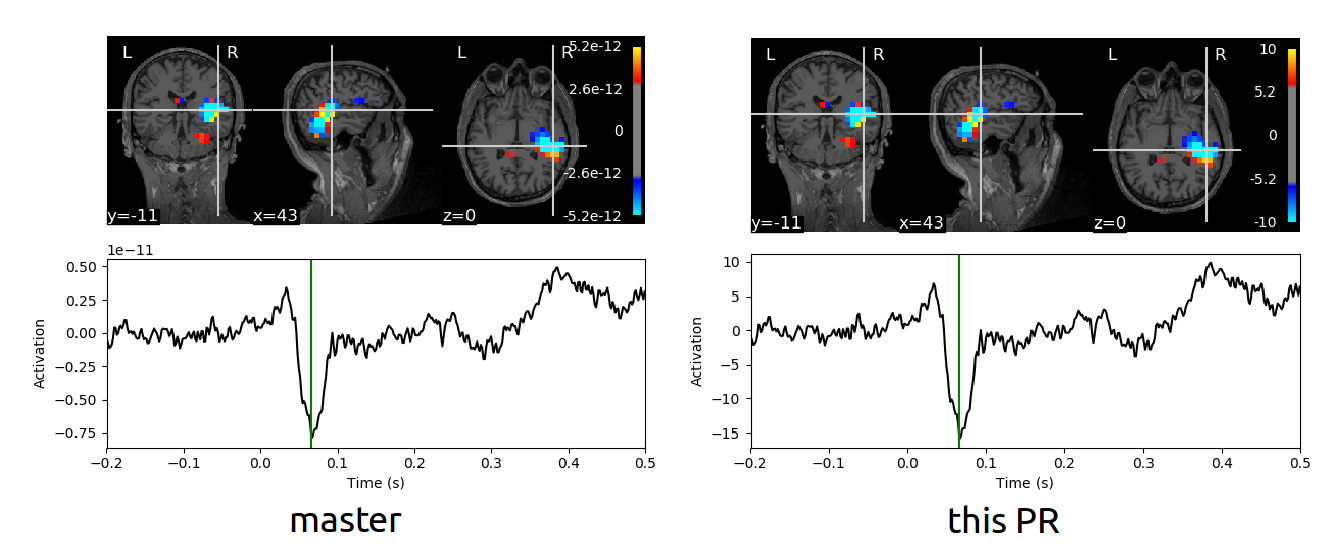
But is this a bad thing? It seems like the output is more correct now, along the lines of what you get if you use an empirical noise cov (rather than |
|
... and at least now there is some reference for what the "unit-noise-gain" is referenced to -- before it was "nothing" and now it's "an ad-hoc diagonal noise covariance". I think this a usability/understandability gain, and a note in If it's not, I can set |
|
Mh, I am hesitant about doing this implicitly, especially with regard to comparability towards other toolboxes and expectations of signal magnitude. |
71af0f3 to
40a6755
Compare
|
I agree with @britta-wstnr -- the NAI variant already serves the purpose of scaling according to noise covariance. The plain unit-noise-gain should therefore remain unscaled, to preserve a noise gain of... unity. ;-) This also would also preserve direct comparability of results with, e.g., FieldTrip and other UNG implementations. |
| stc_nocov = apply_lcmv(evoked, filters_nocov) | ||
| stc_adhoc = apply_lcmv(evoked, filters_adhoc) | ||
|
|
||
| # Compare adhoc and nocov: scale difference is necessitated by using std=1. |
There was a problem hiding this comment.
@britta-wstnr let's figure it out later. For now I've added tests that the amplitudes are as expected for None, NAI and unit-noise-gain (the first two not depending on noise_cov, the last being normalized or not depending on whether or not noise_cov is None). The amplitudes you get now should be like the ones you get in master, can you check?
If we think it makes sense, we can remove the std=1. from the _check_one_ch_type function. I think it would since it makes things more consistent (as shown now by the tests, I think), but let's do it later so this PR isn't held up.
My point is that:
If this is the intended behavior, it's fine with me. |
|
@britta-wstnr can you check one more time that the amplitudes are now the same as in |
|
Hi @larsoner, I think there might be a misunderstanding concerning "weight normalizing". The unit-noise-gain beamformer does not rely on a noise covariance matrix to normalize the weights. This normalization refers to constraints that the beamformer implements (cf. the unit gain constraint for the "vanilla" LCMV beamformer). I will look at the output and report back! |
|
Makes sense! These relationships should already be tested (and probably not commented 100% correctly) in the PR now. Feel free to suggest better wordings for the comments around the tests if they're not precise enough. But hopefully the outputs are the same as they were before now. If so, once this is in, I can try using |
|
Awesome, I will have a review pass on the PR then! |
42216b1 to
3291265
Compare
britta-wstnr
left a comment
There was a problem hiding this comment.
I tested against master and the unit-noise-gain beamformer now gives the expected output (regarding order of magnitude).
|
@britta-wstnr okay to merge once I make the comment updates (and ensure CIs are happy)? |
|
@larsoner, yes, LGTM except for some clearer comments in the tests! |
|
Azure error is unrelated, merging. Thanks for the reviews @britta-wstnr |
|
Cool! Hopefully, this will being us closer to implementing whitening for DICS. Thanks @larsoner and @britta-wstnr! |
* MAINT: Simplify LCMV whitening * FIX: std=1. * FIX: Revert errant example change * DOC: Better comments
Follow-up to #5947. This first step modifies LCMV to make it easier to eventually use
_prepare_forward, specifically by:noise_cov. This simplifies later calculations and branching (see more - lines than + here). In the case of a single channel type, we can just usemake_ad_hoc_cov, which makes a diagonal matrix. This makes it so we don't need to do anything extra withprojsmanually,compute_whitenerdoes it for us. In principlemake_ad_hoc_covcould also be a solution for the multiple-ch-types-no-cov problem, but we can stick with the error and let users usemake_ad_hoc_covthemselves in that case.GandCm, as noted here.Let's see if tests still pass. They do locally.
One potential problem I foresee is that
make_ad_hoc_covshould be fine with projections, but will create problems with data that has been rank-reduced with SSS whennoise_cov=Noneis used. However, this should be exceedingly rare since most SSS'ed data is Neuromag, which has two sensor types. To cover this, we'd need some way to project ourmake_ad_hoc_covinto the same data subspace asdata_cov, which actually would be pretty straightforward given_smart_eighgives us that projection already and it's used in thecovcode. We can wait to deal with this until we hit a use case. But I'm assuming YAGNI for now.At some point it might be useful regardless not just to check that
data_covandnoise_covmatch rank, but that they actually occupy the same vector subspace (have the same null space). Matching effective rank is a necessary but not sufficient condition for this. But in most cases (projection, even SSS when using baseline cov) it should be okay. The one place I see this being useful is if someone uses SSS and takes a noise cov from the empty room instead of the baseline -- these could have the same effective rank but occupy different subspaces (unless the empty room was processed identically to the data, which is probably not what most people do, properly at least). But in this case, you'll just amplify some near-zero components a bit (so should stay near zero) and drop a few components you otherwise shouldn't from thedata_cov, so this is perhaps not a deal-breaker either.cc @britta-wstnr to see if this makes some sense.
Closes #5882.