MRG: Use overlay compositing #8576
Conversation
|
I would much rather let the GPU deal with all of this if possible because this does not scale as well as the GPU will. But if there are no suitable GPU solutions then I CPU is better than wrong GPU |
|
would this be helpful too for notebook backend? |
I'm starting to think there are no suitable GPU solutions. @GuillaumeFavelier before going too far here, maybe try a basic GPU and basic CPU example, totally outside Or if this compositing is 90% done anyway, you can do the same thing probably by adding STC data, then parcellation, then labels, etc., and profile directly with some repeated calls to I think it's worth going through this exercise even if CPU is our only option at least so we know what we're getting into. Bonus points if you do GPU without depth peeling, GPU with depth peeling, and CPU (no depth peeling, not needed)... EDIT: If you're busy with other priorities I can try this benchmarking |
The artifacts in #7599 (comment) are most likely also present with the
got it 👍
This version is very early work and limited to EDIT: I did a gist for the GPU variant |
Could you create a
It makes the implementation at the You could even start by making this class using the EDIT: I am probably missing a lot of necessary arguments like the |
|
|
|
Just my opinion but I somehow find the design more elegant and it feels like less "hacks" are needed. I updated |
|
The implementation is not exactly what you describe in #8576 (comment) but it's flexible @larsoner Always possible to improve |
|
The plot on master: Looks different from (and more correct than) the one on this PR, and I don't think it's just due to the scale bar difference -- note the odd yellow splotches: Also there is a difference in the automatic scale bar (should be about -100 to 40 and is on So it seems like there is both a blending-logic bug and a data scaling bug? |


I would say data scaling for now because when I click on
|
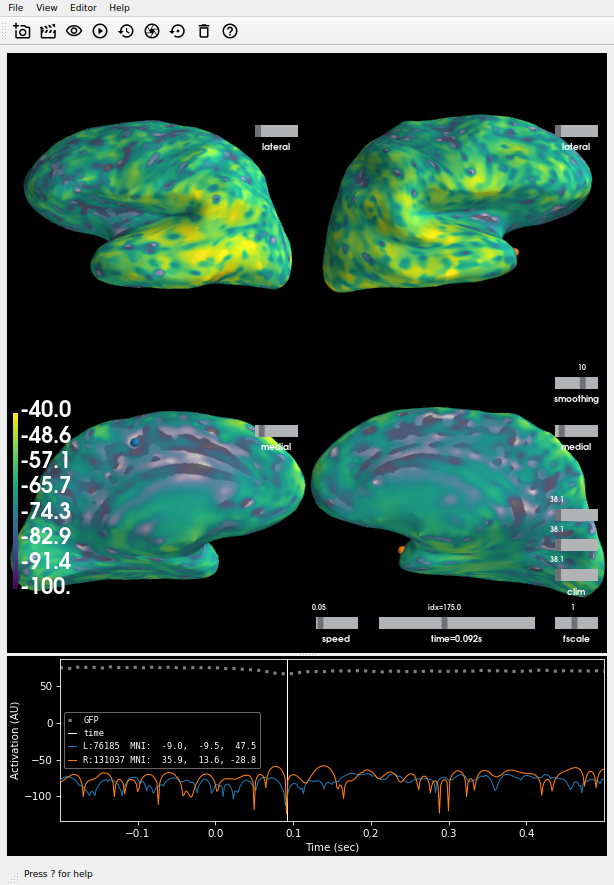
|
The artifacts are available on: I'll work on coverage now |
|
This is ready for reviews @agramfort, @larsoner |
|
I guess unsurprisingly, CircleCI renders faster with this PR, which is neat. And even locally doing |
 larsoner
left a comment
larsoner
left a comment
There was a problem hiding this comment.
LGTM, will merge once CIs are happy. Awesome @GuillaumeFavelier !
|
great !
… |
This PR is a prototype that represents an alternative to VTK alpha blending. It computes the final brain activation as one 'texture map' which is the result of alpha compositing of the overlays.
The pros:
The cons:
_alpha_overfunction to mitigate this (I might need help here). It's also possible to use intermediate results to speedup the computation.This is still very early results.
Closes #7599