This repository was archived by the owner on Jun 4, 2025. It is now read-only.
enable a QATWrapper for non-parameterized matmuls in BERT self attention#9
Merged
enable a QATWrapper for non-parameterized matmuls in BERT self attention#9
Conversation
spacemanidol
approved these changes
Aug 23, 2021
 spacemanidol
left a comment
spacemanidol
left a comment
There was a problem hiding this comment.
Looks good. One thing I wish we had was a way to add QATwrapper without having to update each model.
natuan
approved these changes
Aug 23, 2021
KSGulin
pushed a commit
that referenced
this pull request
Mar 9, 2022
KSGulin
pushed a commit
that referenced
this pull request
Mar 9, 2022
KSGulin
pushed a commit
that referenced
this pull request
Oct 14, 2022
Disable FP16 on QAT start (#12) * Override LRScheduler when using LRModifiers * Disable FP16 on QAT start * keep wrapped scaler object for training after disabling Using QATMatMul in DistilBERT model class (#41) Removed double quantization of output of context layer. (#45) Fix DataParallel validation forward signatures (#47) * Fix: DataParallel validation forward signatures * Update: generalize forward_fn selection Best model after epoch (#46) fix sclaer check for non fp16 mode in trainer (#38) Mobilebert QAT (#55) * Remove duplicate quantization of vocabulary. enable a QATWrapper for non-parameterized matmuls in BERT self attention (#9)
bfineran
added a commit
that referenced
this pull request
Oct 18, 2022
* Update trainer and model flows to accommodate sparseml Disable FP16 on QAT start (#12) * Override LRScheduler when using LRModifiers * Disable FP16 on QAT start * keep wrapped scaler object for training after disabling Using QATMatMul in DistilBERT model class (#41) Removed double quantization of output of context layer. (#45) Fix DataParallel validation forward signatures (#47) * Fix: DataParallel validation forward signatures * Update: generalize forward_fn selection Best model after epoch (#46) fix sclaer check for non fp16 mode in trainer (#38) Mobilebert QAT (#55) * Remove duplicate quantization of vocabulary. enable a QATWrapper for non-parameterized matmuls in BERT self attention (#9) * Utils and auxillary changes update Zoo stub loading for SparseZoo 1.1 refactor (#54) add flag to signal NM integration is active (#32) Add recipe_name to file names * Fix errors introduced in manual cherry-pick upgrade Co-authored-by: Benjamin Fineran <bfineran@users.noreply.github.com>
KSGulin
added a commit
that referenced
this pull request
Jun 19, 2023
* Add recipe_name to default file names * Upgrade to transformers release V4.30.2 (#62) * Update trainer and model flows to accommodate sparseml Disable FP16 on QAT start (#12) * Override LRScheduler when using LRModifiers * Disable FP16 on QAT start * keep wrapped scaler object for training after disabling Using QATMatMul in DistilBERT model class (#41) Removed double quantization of output of context layer. (#45) Fix DataParallel validation forward signatures (#47) * Fix: DataParallel validation forward signatures * Update: generalize forward_fn selection Best model after epoch (#46) fix sclaer check for non fp16 mode in trainer (#38) Mobilebert QAT (#55) * Remove duplicate quantization of vocabulary. enable a QATWrapper for non-parameterized matmuls in BERT self attention (#9) * Utils and auxillary changes update Zoo stub loading for SparseZoo 1.1 refactor (#54) add flag to signal NM integration is active (#32) Add recipe_name to file names * Fix errors introduced in manual cherry-pick upgrade Co-authored-by: Benjamin Fineran <bfineran@users.noreply.github.com> * update build versions for NM fork pypi push (#74) * fix nightly package name (#75) * add make build command (#76) * add GHA workflow files to build nightly and release packages (#77) * add GHA workflow files to build nightly and release packages * fix name --------- Co-authored-by: dhuang <dhuang@MacBook-Pro-2.local> * bump up version to 1.6.0 (#79) Co-authored-by: dhuang <dhuang@MacBook-Pro-2.local> --------- Co-authored-by: Konstantin <konstantin@neuralmagic.com> Co-authored-by: Konstantin Gulin <66528950+KSGulin@users.noreply.github.com> Co-authored-by: dhuangnm <74931910+dhuangnm@users.noreply.github.com> Co-authored-by: dhuang <dhuang@MacBook-Pro-2.local>
dsikka
pushed a commit
that referenced
this pull request
Aug 17, 2023
* Add recipe_name to default file names * Upgrade to transformers release V4.30.2 (#62) * Update trainer and model flows to accommodate sparseml Disable FP16 on QAT start (#12) * Override LRScheduler when using LRModifiers * Disable FP16 on QAT start * keep wrapped scaler object for training after disabling Using QATMatMul in DistilBERT model class (#41) Removed double quantization of output of context layer. (#45) Fix DataParallel validation forward signatures (#47) * Fix: DataParallel validation forward signatures * Update: generalize forward_fn selection Best model after epoch (#46) fix sclaer check for non fp16 mode in trainer (#38) Mobilebert QAT (#55) * Remove duplicate quantization of vocabulary. enable a QATWrapper for non-parameterized matmuls in BERT self attention (#9) * Utils and auxillary changes update Zoo stub loading for SparseZoo 1.1 refactor (#54) add flag to signal NM integration is active (#32) Add recipe_name to file names * Fix errors introduced in manual cherry-pick upgrade Co-authored-by: Benjamin Fineran <bfineran@users.noreply.github.com> * update build versions for NM fork pypi push (#74) * fix nightly package name (#75) * add make build command (#76) * add GHA workflow files to build nightly and release packages (#77) * add GHA workflow files to build nightly and release packages * fix name --------- Co-authored-by: dhuang <dhuang@MacBook-Pro-2.local> * bump up version to 1.6.0 (#79) Co-authored-by: dhuang <dhuang@MacBook-Pro-2.local> --------- Co-authored-by: Konstantin <konstantin@neuralmagic.com> Co-authored-by: Konstantin Gulin <66528950+KSGulin@users.noreply.github.com> Co-authored-by: dhuangnm <74931910+dhuangnm@users.noreply.github.com> Co-authored-by: dhuang <dhuang@MacBook-Pro-2.local>
dsikka
pushed a commit
that referenced
this pull request
Aug 17, 2023
* Add recipe_name to default file names * Upgrade to transformers release V4.30.2 (#62) * Update trainer and model flows to accommodate sparseml Disable FP16 on QAT start (#12) * Override LRScheduler when using LRModifiers * Disable FP16 on QAT start * keep wrapped scaler object for training after disabling Using QATMatMul in DistilBERT model class (#41) Removed double quantization of output of context layer. (#45) Fix DataParallel validation forward signatures (#47) * Fix: DataParallel validation forward signatures * Update: generalize forward_fn selection Best model after epoch (#46) fix sclaer check for non fp16 mode in trainer (#38) Mobilebert QAT (#55) * Remove duplicate quantization of vocabulary. enable a QATWrapper for non-parameterized matmuls in BERT self attention (#9) * Utils and auxillary changes update Zoo stub loading for SparseZoo 1.1 refactor (#54) add flag to signal NM integration is active (#32) Add recipe_name to file names * Fix errors introduced in manual cherry-pick upgrade Co-authored-by: Benjamin Fineran <bfineran@users.noreply.github.com> * update build versions for NM fork pypi push (#74) * fix nightly package name (#75) * add make build command (#76) * add GHA workflow files to build nightly and release packages (#77) * add GHA workflow files to build nightly and release packages * fix name --------- Co-authored-by: dhuang <dhuang@MacBook-Pro-2.local> * bump up version to 1.6.0 (#79) Co-authored-by: dhuang <dhuang@MacBook-Pro-2.local> --------- Co-authored-by: Konstantin <konstantin@neuralmagic.com> Co-authored-by: Konstantin Gulin <66528950+KSGulin@users.noreply.github.com> Co-authored-by: dhuangnm <74931910+dhuangnm@users.noreply.github.com> Co-authored-by: dhuang <dhuang@MacBook-Pro-2.local>
bfineran
added a commit
that referenced
this pull request
Oct 26, 2023
* Add recipe_name to default file names * Upgrade to transformers release V4.30.2 (#62) * Update trainer and model flows to accommodate sparseml Disable FP16 on QAT start (#12) * Override LRScheduler when using LRModifiers * Disable FP16 on QAT start * keep wrapped scaler object for training after disabling Using QATMatMul in DistilBERT model class (#41) Removed double quantization of output of context layer. (#45) Fix DataParallel validation forward signatures (#47) * Fix: DataParallel validation forward signatures * Update: generalize forward_fn selection Best model after epoch (#46) fix sclaer check for non fp16 mode in trainer (#38) Mobilebert QAT (#55) * Remove duplicate quantization of vocabulary. enable a QATWrapper for non-parameterized matmuls in BERT self attention (#9) * Utils and auxillary changes update Zoo stub loading for SparseZoo 1.1 refactor (#54) add flag to signal NM integration is active (#32) Add recipe_name to file names * Fix errors introduced in manual cherry-pick upgrade Co-authored-by: Benjamin Fineran <bfineran@users.noreply.github.com> * update build versions for NM fork pypi push (#74) * fix nightly package name (#75) * add make build command (#76) * add GHA workflow files to build nightly and release packages (#77) * add GHA workflow files to build nightly and release packages * fix name --------- Co-authored-by: dhuang <dhuang@MacBook-Pro-2.local> * bump up version to 1.6.0 (#79) Co-authored-by: dhuang <dhuang@MacBook-Pro-2.local> --------- Co-authored-by: Konstantin <konstantin@neuralmagic.com> Co-authored-by: Konstantin Gulin <66528950+KSGulin@users.noreply.github.com> Co-authored-by: dhuangnm <74931910+dhuangnm@users.noreply.github.com> Co-authored-by: dhuang <dhuang@MacBook-Pro-2.local>
bfineran
added a commit
that referenced
this pull request
Oct 27, 2023
(previous commits) * Add recipe_name to default file names * Upgrade to transformers release V4.30.2 (#62) * Update trainer and model flows to accommodate sparseml Disable FP16 on QAT start (#12) * Override LRScheduler when using LRModifiers * Disable FP16 on QAT start * keep wrapped scaler object for training after disabling Using QATMatMul in DistilBERT model class (#41) Removed double quantization of output of context layer. (#45) Fix DataParallel validation forward signatures (#47) * Fix: DataParallel validation forward signatures * Update: generalize forward_fn selection Best model after epoch (#46) fix sclaer check for non fp16 mode in trainer (#38) Mobilebert QAT (#55) * Remove duplicate quantization of vocabulary. enable a QATWrapper for non-parameterized matmuls in BERT self attention (#9) * Utils and auxillary changes update Zoo stub loading for SparseZoo 1.1 refactor (#54) add flag to signal NM integration is active (#32) Add recipe_name to file names * Fix errors introduced in manual cherry-pick upgrade Co-authored-by: Benjamin Fineran <bfineran@users.noreply.github.com> * update build versions for NM fork pypi push (#74) * fix nightly package name (#75) * add make build command (#76) * add GHA workflow files to build nightly and release packages (#77) * add GHA workflow files to build nightly and release packages * fix name --------- Co-authored-by: dhuang <dhuang@MacBook-Pro-2.local> * bump up version to 1.6.0 (#79) Co-authored-by: dhuang <dhuang@MacBook-Pro-2.local> --------- Co-authored-by: Konstantin <konstantin@neuralmagic.com> Co-authored-by: Konstantin Gulin <66528950+KSGulin@users.noreply.github.com> Co-authored-by: dhuangnm <74931910+dhuangnm@users.noreply.github.com> Co-authored-by: dhuang <dhuang@MacBook-Pro-2.local> minor improvements for build workflow files (#83) Co-authored-by: dhuang <dhuang@MacBook-Pro-2.local> fix minor issue (#84) Co-authored-by: dhuang <dhuang@MacBook-Pro-2.local> OPT with quantizable MatMuls (#85) fix a minor issue for release build (#86) Co-authored-by: dhuang <dhuang@MacBook-Pro-2.local> update version in version.py Testmo (#91) * improve GHA workflow files to build nightly and release, and report status to testmo * clean up * report exit code * Assign value to exit_code --------- Co-authored-by: dhuang <dhuang@MacBook-Pro-2.local> Update trainer.py - fix DistributedSampler import (#93) DistributedSampler is used but not imported in `trainer.py` Research/llama/bmm quantization (#94) * Quantize attention matmuls * Quantize attention matmuls bump base transformers version
bfineran
pushed a commit
that referenced
this pull request
Jun 5, 2024
* Cohere Model Release (#1) Cohere Model Release * Remove unnecessary files and code (#2) Some cleanup * Delete cohere-model directory (#3) * Make Fix (#5) * Pr fixes (#6) * fixes for pr * pr fixes for the format * pr fixes for the format * src/transformers/models/auto/tokenization_auto.py * Tokenizer test (#8) * tokenizer test * format fix * Adding Docs and other minor changes (#7) * Add modeling tests (#9) * Smol Fix (#11) * tokenization tests are fixed * format fixes * fix pr doc tests * fix pr doc tests * fix pr doc tests * fix pr style check * small changes in cohere.md * FIX: Address final comments for transformers integration (#13) * fix modeling final nits and add proper test file * for now leave empty tests * add integration test * push new test * fix modeling cohere (#14) * Update chat templates to use the new API (#15) --------- Co-authored-by: ahmetustun <ahmetustun89@gmail.com> Co-authored-by: Younes Belkada <49240599+younesbelkada@users.noreply.github.com> Co-authored-by: Matt <Rocketknight1@users.noreply.github.com>
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Sign up for free
to subscribe to this conversation on GitHub.
Already have an account?
Sign in.
3 participants
Add this suggestion to a batch that can be applied as a single commit.This suggestion is invalid because no changes were made to the code.Suggestions cannot be applied while the pull request is closed.Suggestions cannot be applied while viewing a subset of changes.Only one suggestion per line can be applied in a batch.Add this suggestion to a batch that can be applied as a single commit.Applying suggestions on deleted lines is not supported.You must change the existing code in this line in order to create a valid suggestion.Outdated suggestions cannot be applied.This suggestion has been applied or marked resolved.Suggestions cannot be applied from pending reviews.Suggestions cannot be applied on multi-line comments.Suggestions cannot be applied while the pull request is queued to merge.Suggestion cannot be applied right now. Please check back later.
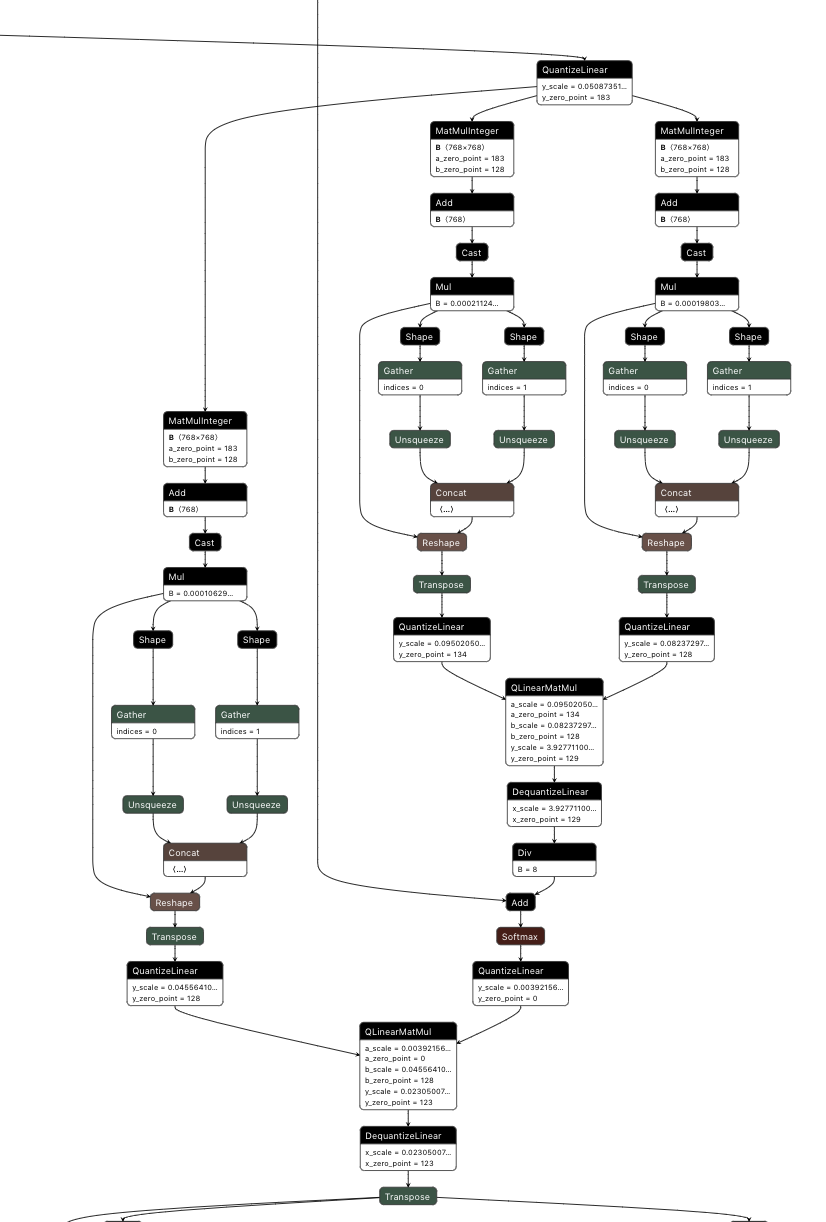
updated quantized self attention block structure (through attention scores matmul):