TiffSaver: Only setLength of output file once#3239
Conversation
| // sets the output file size without having to allocate for each strip iteration | ||
| out.seek(stripStartPos + totalStripSize); | ||
| // return to original position | ||
| out.seek(stripStartPos); |
There was a problem hiding this comment.
This seek is unnecessary and can be removed
|
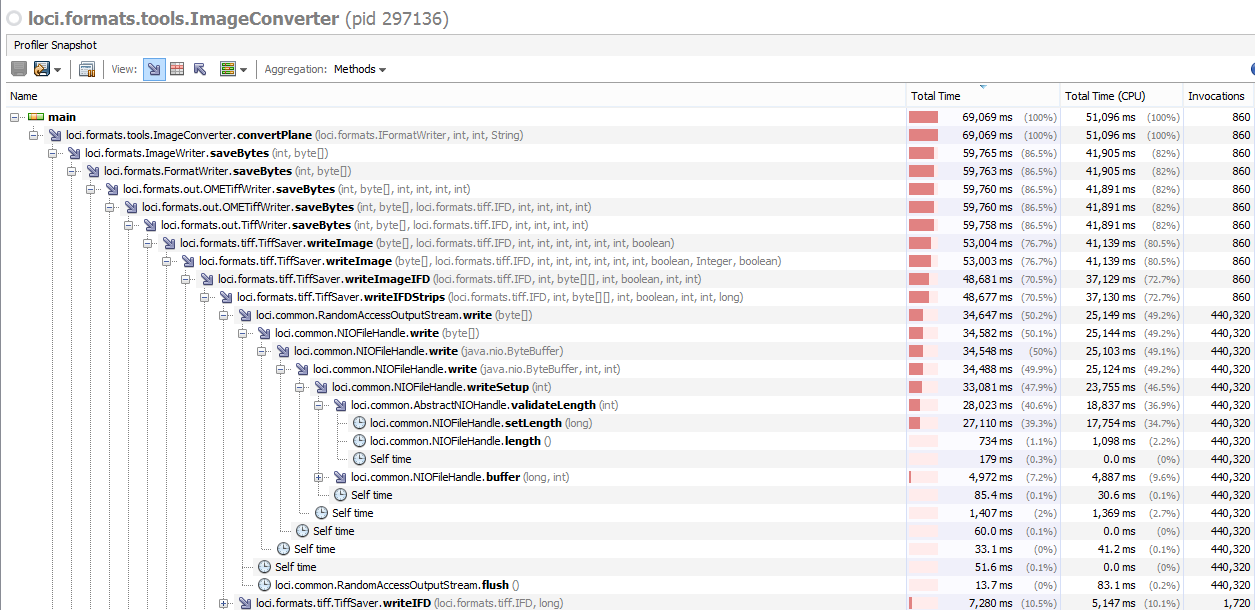
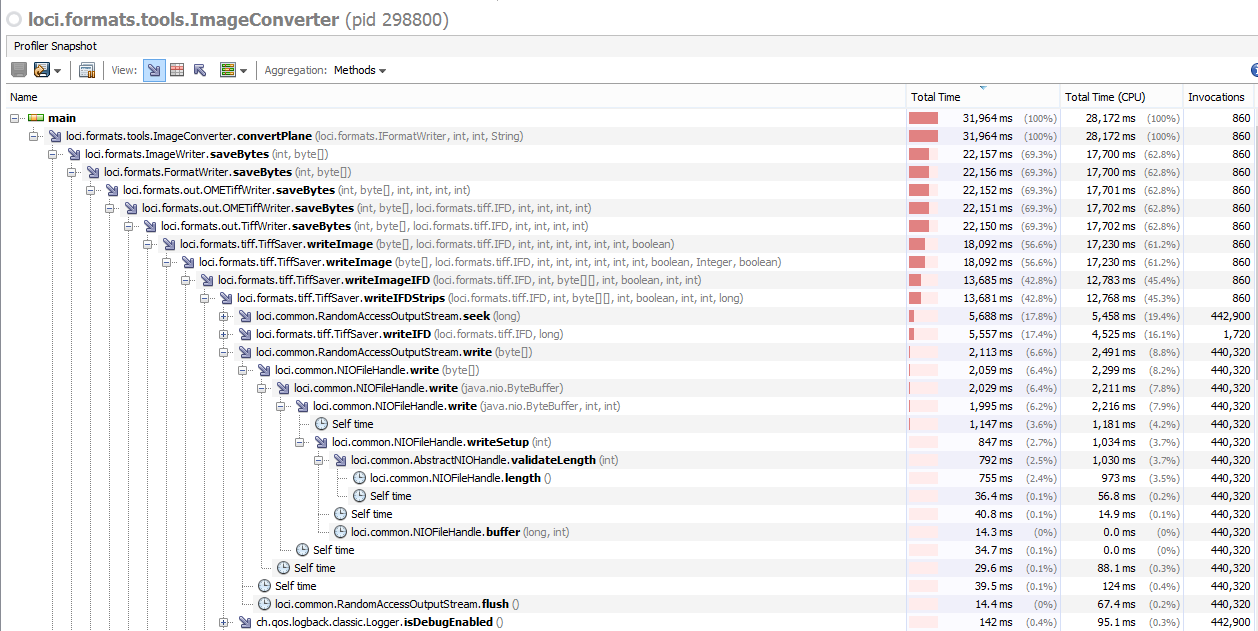
Attached show the before and after of the call stacks: After: Using bfconvert with tubhiswt-4D dataset: Windows - Java 8 Windows - Java 10 (actually not impacted as much as expected) Tiling performance is not improved so that needs to be corrected. |
|
As a follow up, i've been profiling and debugging the tiled scenario further. In the case of tiling there are some differences but the short of it is we are still in a scenario of having to setLength for each tile so performance will remain similar as to before. In saying that the setLength doesnt impact the tiled case as much in the first place, the reading of tiles in ImageConverter is actually adding overhead as opposed to the writing. |
 sbesson
left a comment
sbesson
left a comment
There was a problem hiding this comment.
Change make sense and this has certainly been tested over the last weeks for various conversions without any adverse effect being reported. All unit tests are passing. Merging for the next milestone of Bio-Formats 6.
This is in relation to trying to address performance issues, see https://trello.com/c/OimiHAQY/39-ome-common-profile-tiff-writing and ome/ome-common-java#15
As shown in ome/ome-common-java#15 the problem lies in the repeated calling of setLength on RandomAccessFile.
The issue originally thought to be a Windows issue looks like it may be related to Java versions with RandomAccessFile.setLength being much slower on Java 10 (see https://stackoverflow.com/questions/50450317/randomaccessfile-setlength-much-slower-on-java-10-centos for some info)
In Java 8 setLength does:
While in Java 10 it introduces the much slower fallocate (to fix a bug):
This is particularly problematic for us as the profiling shows we make a large number of calls to setLength. Essentially every time we write a strip we are calling it to increase the length of the output file.
Buffering in NIOFileHandle will help improve this, but as TiffSaver knows the length of data it is writing it might make more sense to make a single call to allocate the length upfront. In this case it is being forced by seeking to length which in turn calls setLength.