Simplify PD node status#474
Conversation
Codecov Report
@@ Coverage Diff @@
## master #474 +/- ##
==========================================
- Coverage 39.84% 38.96% -0.89%
==========================================
Files 201 205 +4
Lines 14847 15386 +539
==========================================
+ Hits 5916 5995 +79
- Misses 8072 8516 +444
- Partials 859 875 +16
Continue to review full report at Codecov.
|

|
From the user perspective do we have differences about unhealthy and down? @HunDunDM PTAL |
|
|
||
| healths, err := curPdAPI.GetHealth() | ||
| // "Down" means all PD nodes don't work, | ||
| // while "Unhealthy" means current PD node doesn't work |
There was a problem hiding this comment.
I'm confused by this, I thought "Down" means the specific PD node is not working, and "Unhealthy" means the PD cluster is not in proper state.
There was a problem hiding this comment.
But according to the old logic, they will be all recognized as "Down" status, we never can go to the return "Unhealthy" + suffix line logic.
|
I don't think we have made a clear distinction between these two different terms. |
|
In fact, my key point is that, according to the code, we use the "Healthy" status to represent the work PD node, so it is natural to think that we should use "Unhealthy" to represent the not work PD node. It is true the "Unhealthy" is used in the code, but unfortunately, its logic never reach, it is always recognized as "Down". (I guess the "Healthy" and "Unhealthy" come from the So, the PD node has 3 main kinds of status: "Healthy", "Unhealthy" and "Down", but only "Healthy" and "Down" happen. Actually, for other components (TiDB / TiKV / TiFlash), we use "Up" to represent work node, and use "Down" to represent not work node. So it seems here exists some inconsistency. Now I don't think this PR is a good solution. Or maybe we can use "Up" to replace "Healthy", remove the unreached "Unhealthy", and keep "Down" for PD node to keep consistency with other components, how about it? |
|
It was because there is a state in PD's API response, it was never clearly documented what those states represent. It's ok to just remove the health/unhealthy term in response body and use up/down for only check response http code. But I would wonder: what on earth does the |
|
What state would a PD node report, if another node in the cluster is down, while itself is still working, health = true or false ? |
|
We determine that the health of an instance is based on that the http server can respond normally. |
Sounds reasonable to me too. |
Thanks for the clarification, my curiosity is that when would a PD node be responding to API calls and return an object with |
|
When you request
|
What if a follower is down, will the leader respond unhealthy state? And if I understand it correctly, in this circumstance, all alive nodes will report the same unhealthy state? |
|
The leader will only mark the node as unhealthy.
yes. |
|
@AstroProfundis , this is an example response for [
{
"name": "pd-10.0.1.14-2379",
"member_id": 4436600309396281139,
"client_urls": [
"http://10.0.1.14:2379"
],
"health": true
},
{
"name": "pd-10.0.1.11-2379",
"member_id": 16310129336451408704,
"client_urls": [
"http://10.0.1.11:2379"
],
"health": true
},
{
"name": "pd-10.0.1.15-2379",
"member_id": 16570216285418057773,
"client_urls": [
"http://10.0.1.15:2379"
],
"health": false
}
] |
|
OK I understand. So there are 2 possible solutions:
I'd prefer 2. |
|
Prefer 2 as well. |
|
Hi @AstroProfundis , I have updated it, PTAL, thanks! btw, I used the besides, I found there are some code in
|
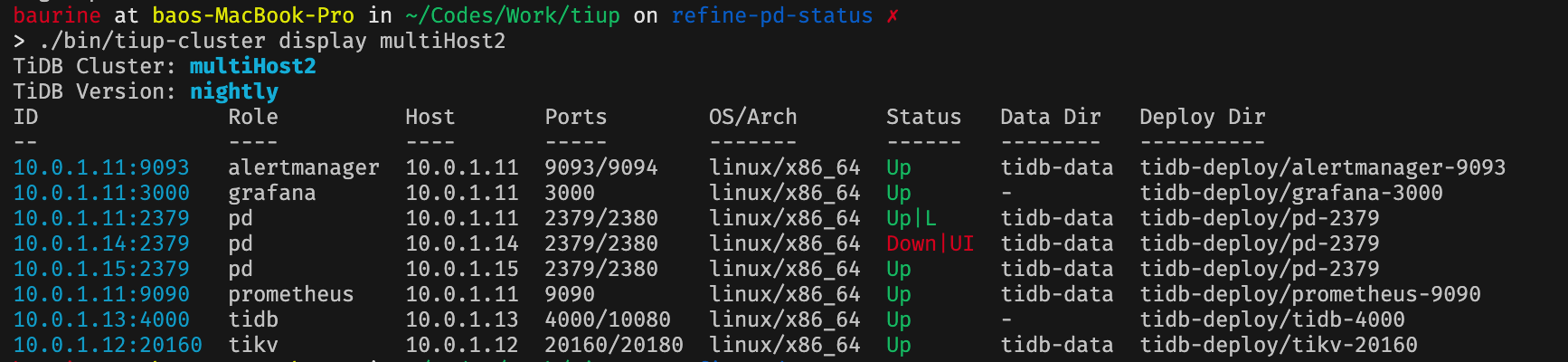
|
ping @AstroProfundis |
What problem does this PR solve?
Resolve a part of #472
Currently, the "Unhealthy" PD node is recognized as "Down" status, and the "Unhealthy" status never displays.
What is changed and how it works?
Differ the "Down" and "Unhealthy" status for PD node, when all nodes don't work, recognize them as "Down", else recognize the not work node as "Unhealthy".
Check List
Tests
Deploy a cluster with 3 PD nodes, pause 1 node.
Before:
After:
Pause 2 PD nodes: