Load model before assign submodule to device to save cpu memory#770
Load model before assign submodule to device to save cpu memory#770kwen2501 merged 6 commits intopytorch:mainfrom
Conversation
|
@kwen2501 @HamidShojanazeri Hi, it would be nice if you can have a look at this PR. This helps save CPU memory, and it is really useful for large language models (like bloom-176b). |
|
Hi @jiqing-feng thanks so much for the PR and sorry about the delay. (We were busy implementing the HF generate support in previous days.) I am reviewing your PR now. |
|
Hi, @kwen2501 thanks for your support. It is nice to support generation in PiPPy and I see that you set I have successfully run the generation task with Of course, I can submit another PR to fix it if you want. BTW, enabling Thanks, hope for your response. |
 kwen2501
left a comment
kwen2501
left a comment
There was a problem hiding this comment.
LGTM!
Thank you SO MUCH for contributing to PiPPy!
I just added some minor comments.
| param_name (`str`): | ||
| The full name of the parameter/buffer. |
There was a problem hiding this comment.
nit: replace param_name with tensor_name so that it is consistent with the API signature.
| if hasattr(model, "lm_head"): | ||
| model.lm_head.weight = torch.nn.Parameter((param.clone()).to(device)) | ||
| if hasattr(model, "encoder_embed_tokens"): | ||
| model.encoder_embed_tokens.weight = torch.nn.Parameter((param.clone()).to(device)) | ||
| if hasattr(model, "decoder_embed_tokens"): | ||
| model.decoder_embed_tokens.weight = torch.nn.Parameter((param.clone()).to(device)) |
There was a problem hiding this comment.
nit: do you mind putting a comment here on why it would be desirable to make a clone of the parameter for these set of parameters?
|
For other readers, an index file may look like this: |
|
@jiqing-feng |
|
Cc @wz337 PyTorch maintainer for distributed checkpointing. |
 HamidShojanazeri
left a comment
HamidShojanazeri
left a comment
There was a problem hiding this comment.
Thanks @jiqing-feng for the contribution, added some inline comments.
| model = RegNetModel.from_pretrained("facebook/regnet-y-10b-seer") | ||
| args.feature_extractor = feature_extractor | ||
| if args.index_filename is not None: | ||
| with init_empty_weights(): |
There was a problem hiding this comment.
@jiqing-feng thanks for the PR!
I wonder if we would be able to implement init_empty_weight as we implemented here, this way we would not need to add accelerate as a dependency.
We are in fact looking to add this to PT, may take a bit time though.
There was a problem hiding this comment.
Thanks for your comments. It would be great if you can add the init_empty_weights to PT. In this case, I only import accelerate in the Huggingface example, it would not be a problem since accelerate is belong to Huggingface and many examples in transformers also used accelerate.
| import torch | ||
| from torch import nn | ||
|
|
||
| def load_checkpoint( |
There was a problem hiding this comment.
@jiqing-feng I wonder if this is specific to HF models? wondering if this would be generalized to cover other dist checkpoints like from FSDP.
There was a problem hiding this comment.
For now, I only tested it on HF models, but I think it should work if the model has a weight map like pytorch_model.bin.index.json
Hi, @kwen2501 thanks for your comments. I have added the README. The model cannot be loaded by the URL since all weights are saved in the model.bin. We can download the model and this method only supports models with pytorch_model.bin.index.json. |
| parser.add_argument('--chunks', type=int, default=1) | ||
| parser.add_argument('--cuda', type=int, default=int(torch.cuda.is_available())) | ||
| parser.add_argument('--pp_group_size', type=int, default=int(os.getenv("WORLD_SIZE", 4))) | ||
| parser.add_argument('--index_filename', type=str, default=None, help="The director or url of model's index.json file") |
There was a problem hiding this comment.
@jiqing-feng can. you pls add an example of " url of model's index.json file" or we might need to have a script to download the model checkpoint that let us run this e2e.
There was a problem hiding this comment.
Sorry, it is a mistake and I have changed it. The model cannot be loaded by the URL since all weights are saved in the model.bin, so we need to download the model anyway. Thanks for your reminder.
|
@jiqing-feng following the readme, I am running into the dtype mismatch here, wondering if I am missing something? |
It is because it does not support float16 and the bloom model's tensors are saved as float16. I am trying to fix it by supporting user-customized data types. |
Hi, @HamidShojanazeri , thanks for your reminder. It should work now, and you can also try bfloat16 with |
|
@jiqing-feng , thanks for the updates, it LGTM, just a minor point I found |
|
@kwen2501 can you pls have final review as per offline discussions to move forward and merge the PR. |
|
@jiqing-feng just one more thing came up for me, trying this model |
|
I just pushed a commit to fix the lint issues complained by the CI. |
|
Hi @jiqing-feng thanks much for this important feature that enables large model loading. I merged this PR to main. As a follow-up, I would like to check with you whether the following API semantic would read more composable: It may be just a matter of style, but can also help |
Thanks for your comment. I will check it |
Hi, @kwen2501 , thanks for your comment. Load checkpoint after all compile may not work. |
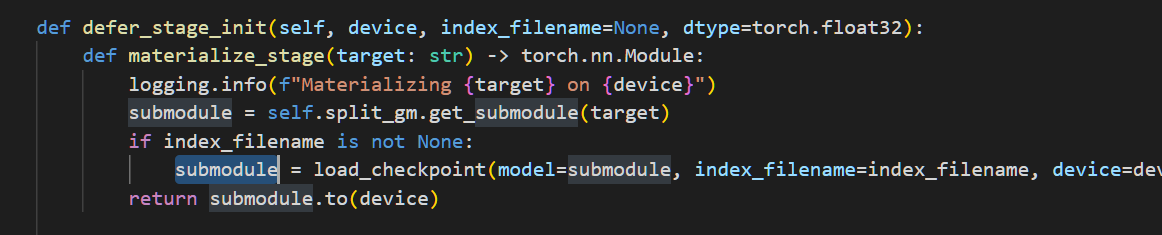
|
Thanks for the reply @jiqing-feng . In this specific case, how about that we delay |
|
I have to admit though the separate API approach would only work for |
Yes, and if we want to keep the all_compile API clean, we can use an environment variable to pass the model directory. And I was wondering if you could have a look on 777 which fixed loading some models. Thanks! @kwen2501 @HamidShojanazeri |
Relate to [770](#770). This PR solved the problem of loading parameters saved in module._parameters by matching the parameters' names. Hi, @HamidShojanazeri , gpt models like cerebras/Cerebras-GPT-13B should work with this PR. BTW, I think we can keep git clone models for now since it is recommended by Huggingface officially. I could have a try on your recommended way and will integrate it if possible. Hi, @kwen2501 @HamidShojanazeri , could you help me review it? Thanks!
@kwen2501 @HamidShojanazeri Hi, related to this issue: #723.
I found a way to reduce CPU memory costs. If I load an empty model in
HF_inference.pyand load the submodule's weights before assigning the submodule to the device, it will save CPU memory because each rank will only load the submodule's weights instead of the whole model. I have tested my code on opt-13b and flan-t5-xxl, and it works well.Would you please help me to review it? Thanks!