- 개발기간
- 2021.09 ~ 2021.11
- 사용 언어 및 라이브러리
구글 Vision API,OpenCV,Jupyter,python,pandas,sklearn
- 램덤포레스트 회귀 모델을 사용하여 중고 가격을 책정해주는 시스템
- 2021년 ‘기계학습’ 교과목 팀 프로젝트
중고거래 앱 사용자가 늘어남에 따라 가격을 책정하는 방법을 제시하는 글이 생겨나는 등 판매 가격을 책정하기 어렵다는 사람들도 늘고 있다. 또한, 중고거래 플랫폼에서 일부 제품이 원가보다 비싼 가격으로 둔갑하여 판매하는 사기도 발생하고 있다. 따라서 중고가격 책정의 어려움을 덜고, 개인 간 일어나는 사기 및 분쟁을 줄이기 위해 가격을 합리적이고 객관적이게 책정해주는 시스템이 필요하다고 생각되어 해당 시스템을 개발하고자 하였다.
- 문제 정의
- 카테고리 분류 API 사용
- 데이터 셋 구축
- 데이터 탐색
- 모델링
- 프로토타입 구현
- 중고나라 크롤링을 통해 구축한 생성날짜와 게시글 제목 2개의 columns와 1493개의 row로 구성된 csv 파일
-
카테고리 분류
- OpenCV를 사용하여 카메라를 실행시키고 붉은색의 직사각형 가이드라인을 제시하여 이미지를 촬영하고 저장함.
- OpenCV를 통해 저장해 놓은 이미지 파일을 구글 Vision API를 사용하여 라벨을 추출.
- 라벨 추출 결과에 label score가 높은 순으로 들어가 있기 때문에 리스트에 담아 label score가 가장 높은 라벨을 사용.
-
데이터 셋 구축
- 중고나라 사이트를 크롤링하여 게시글에서 중고가, 제품, 제목 정보를 얻어 데이터 셋을 구축.
-
EDA
- 날짜 컬럼에서 년과 월까지의 데이터만을 개별 feature로 추출한 후 date형으로 변경
- 그 후 각 feature 별 시각화를 통해 데이터를 탐색
-
일별 거래 횟수
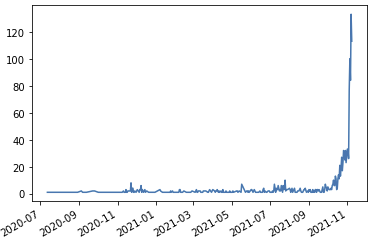
-
가격
-
제품 모델별 가격의 평균과 표준편차를 계산한 후 데이터의 가격이 모델별 평균에 비해 어느정도로 높거나 낮은지 파악하기 위해 z-score를 계산
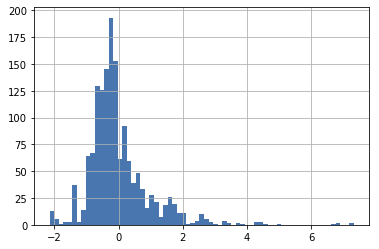
-
-
메이커
- 메이커 별 거래 데이터 개수 파악
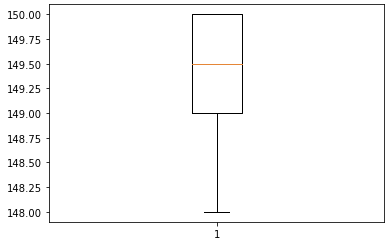
-
-
모델링
- 데이터를 7:3 비율로 분할한 후 랜덤포레스트회귀 모델을 사용하여 학습 시킴.
-
MSE
- Train : 43757717362.710, Test: 21313556238.076
-
R2
- Train : 0.175, Test : -0.086
-
예측결과 Scatter plot
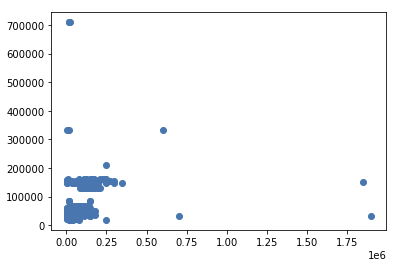
-
- 데이터를 7:3 비율로 분할한 후 랜덤포레스트회귀 모델을 사용하여 학습 시킴.
-
Feature 중요도 분석
-
모델 성능이 MSE는 굉장히 크고 r2는 굉장히 낮은 모습을 보아 학습이 제대로 이루어 지지 않은 것으로 판단하여 Feature 중요도 분석 시행
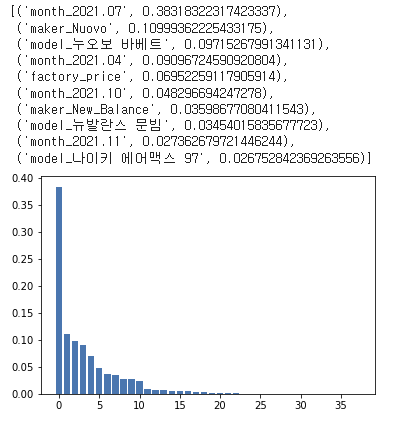
-
‘month’ Feature의 영향력이 높아보임
-
-
예측 모델 개선
-
기존 feature의 가공
-
날짜 데이터를 수치적으로 계산하기 위해 unixtime으로 변환한 후 min-max 정규화를 통해 피처 값의 범위를 0~1로 조정하여 줌.
-
-
가공한 데이터를 다시 학습용과 테스트용으로 분할한 후 랜덤포레스트회귀 모델을 학습
-
MSE
- Train: 18761557779.561, Test: 23899303951.408
-
R2
- Train: 0.646, Test: -0.218
-
예측결과 Scatter plot
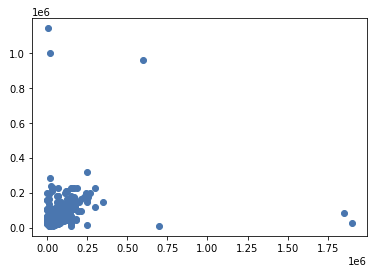
-
-
최적의 모델 파라미터 찾기
-
sklearn의 RandomizedSearchCV를 사용하여 모델의 파라미터를 조정
-
최적 파라미터
{'n_estimators': 200, 'max_features': 'sqrt', 'max_depth': 80, 'bootstrap': False}
-
-
최적 모델 학습 결과
-
MSE
- Train: 17675068278.982, Test: 6212981672.534
-
R2
- Train: 0.667, Test: 0.683
-
예측결과 Scatter plot
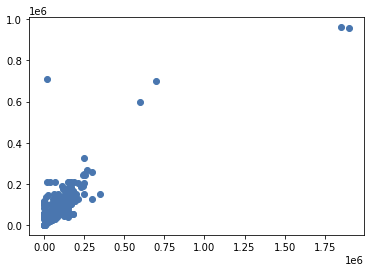
-
-
-
프로토타입 구현
-
모델의 재사용을 위해 pickle 파일로 저장
-
판매 가격을 예측하고자 하는 제품의 메이커, 모델명, 날짜, 제품 상태를 입력하면 판매가격을 예측하여줌.
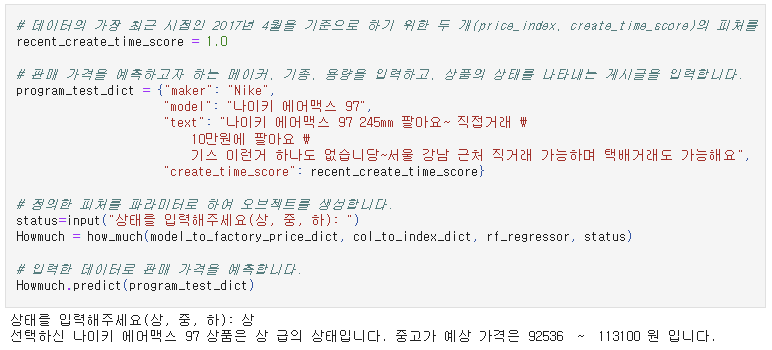
-
-
최종 프로토타입

팀원 4명
- 크롤링 2명
- 구글 API 사용 1명
- 모델링 2명
- 프로토타입 2명
- 구글 API 카테고리 분류
- 랜덤포레스트 모델링
- 프로토타입 제작
Google Cloud Vision API의 사용법을 익힐 수 있었음.OpenCV를 사용하여 이미지를 촬영하고 저장하는 방법을 수행해보았음.Feature Engineering전과 후 모델링 결과를 비교해보며 데이터 전처리의 중요성을 배울 수 있었음.RandomizedSearchCV를 사용하여 모델의 최적의 파라미터를 찾기 위한 시도를 해보았음.