Write ADR for processing / merging #96
Description
We need to document our processing and merging strategy. Our way is to implement a chained approach, where we succeedingly enhance the final data model with more data from sources.
We define an order of mergers collating the data from each of the sources sequentially. The harvesters can run in parallel.
This enables us to benefit from prior knowledge of former processed sources, enabling a ranking by starting with high value sources (CFF, CodeMeta, ...) to lower quality and coarse ones like Git, APIs, etc.
The idea is to use a general merger that has selectable generalized merging strategies. This general merger is fed with data from sources that might have been mangled by a preprocessor (which already builds on former knowledge from sources merged before).
Other approach on the right: push all data into one giant model and cleanup collisions, duplicates etc.
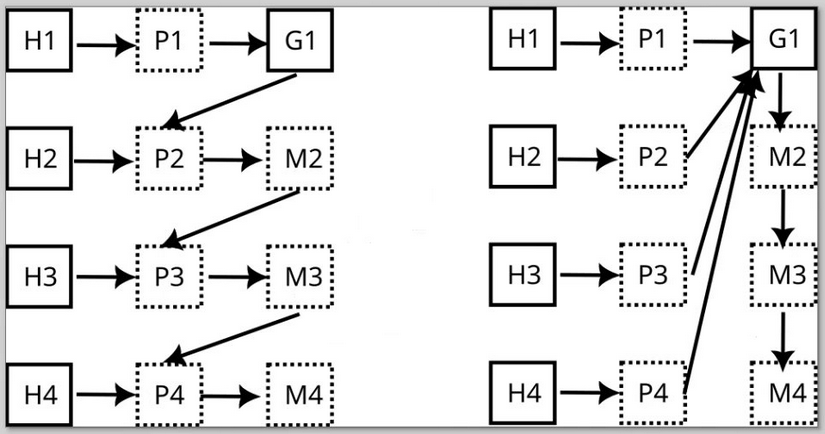
This could also be combined: the general merger might implement such a cleanup and run last in order.