Conversation
These changes take lessons learned from experiments by @gregorycoppola and myself, as well as feedback on various related PRs. It uses the following techniques to improve the speed and scalability of the mempool walk. * Uses rusqlite's `Rows` iterator to read one row at a time * Caches the nonces in memory to avoid repeated lookups * Restarts search from the highest fee-rate transactions after every executed transaction * Caches potential transactions in memory to retry on next pass With this implementation, miners can reliably fill a block in <30s, regardless of how large the mempool gets.
Codecov Report
@@ Coverage Diff @@
## develop #3337 +/- ##
===========================================
- Coverage 32.02% 31.95% -0.08%
===========================================
Files 261 261
Lines 208687 209709 +1022
===========================================
+ Hits 66830 67008 +178
- Misses 141857 142701 +844
📣 We’re building smart automated test selection to slash your CI/CD build times. Learn more |
|
The better numbers from before were when the caching was applied on top of the changes in #3326.
|
This was a typo when refactoring, and caused worse ordering for the transactions.
|
I made a mistake when refactoring this code and the retry list was being processed in the wrong order. The updated benchmarking numbers are here:
It's surprising that the fees collected gets worse when this bug is fixed. That must indicate that the cost estimate (and thus the fee rate) is off. |
|
Ah, I found another bug in this refactoring. Will fix and rerun the experiment. |
|
Ok, after the bug fixes, the benchmark results look better:
Now we get a 100% full block (read count is 15,000), and we get 44.82 STX more fees than the alternate implementation. |
|
The failing unit test, |
src/core/mempool.rs
Outdated
| // Simple size cap to the cache -- once it's full, all nonces | ||
| // will be looked up every time. This is bad for performance | ||
| // but is unlikely to occur due to the typical number of | ||
| // transactions processed before filling a block. |
There was a problem hiding this comment.
How often is this cache cleared? Is it once per block?
Also, it is knowable how many addresses can be loaded per block -- we could, in theory, calculate the maximum number of transactions that could be mined in a block, and use that to derive a maximum number of addresses that block could touch.
There was a problem hiding this comment.
Given how this cache gets used, it might make sense to just use a simple LRU strategy for now. This cache is meant to help minimize the number of times we have to read the MARF to load up a nonce, so eliminating the most-common cases would be a good first attempt.
One day, subsequent refinement might consider the number of nodes that must be visited in the MARF to load the nonce. If the address's nonce was recently changed, then there are fewer tries to visit. It would make sense then to cache a nonce with probability proportional to how long ago it was last changed. It doesn't have to be in this PR, but I'm flagging it here for consideration.
There was a problem hiding this comment.
Should we separate out the cache changes from the non-caching part of this PR?
There was a problem hiding this comment.
@gregorycoppola I believe that because this cache is key to mempool iteration performance, we should get it checked in with this PR.
There was a problem hiding this comment.
@obycode On cache miss, could you instead write the last-known nonce to the mempool DB so we don't hit the MARF more than once per candidate on a call to iterate_candidates()? Then, on a subsequent cache miss, you could first check the mempool DB for the nonce, and then check the MARF it it's not there. You'd probably want to clear all last_known_nonces at the beginning of iterate_candidates().
There was a problem hiding this comment.
On cache miss, could you instead write the last-known nonce to the mempool DB so we don't hit the MARF more than once per candidate on a call to iterate_candidates()?
Yes, we can do this. I'll benchmark again to see what kind of effect this has on performance in the normal case.
There was a problem hiding this comment.
LRU or no, I think you can bound transactions at around 256k using:
pub const MEMPOOL_MAX_TRANSACTION_AGE: u64 = 256;
And a calculation that around 1000 transactions fill a block.
So, the most number of transactions you would "expect" to crawl through before hitting a full block would be 256*1000=256k.
There was a problem hiding this comment.
That accounts for transactions that have already been mined, but not pending transactions that can't yet be mined because of their nonces. There's no way to cap that number.
There was a problem hiding this comment.
i was assuming that, on average, 1/256 transactions would have the right nonce.. i think that in practice the "proportion ready to mine" would actually go up and down a bit.
There was a problem hiding this comment.
also... the height that's used for eviction is independent of chaining, MemPoolDB::tx_submit... it just goes by 256 blocks since the height the tx was submitted, afaiu.
either way, this is just a model.
 jcnelson
left a comment
jcnelson
left a comment
There was a problem hiding this comment.
Thanks for this PR @obycode!
One thing that I think we'll want to see before merging is some test coverage that verifies the following:
-
All transactions are visited at least once on iteration, assuming no time-outs and no out-of-space events occur.
-
We need to see what happens when there are more mempool transactions than the caches have space (maybe the cache sizes could be configurable?). In particular, the test should verify that the caches reduce the number of I/O operations predictably, given their size. The cache could track this information in some internal accounting state.
-
We'll want to know what a good default cache size is for when the chain is under load. I think this could be obtained with live-testing with the mock miner, but it would be ideal if there was a unit test that could show us how to deduce this (or possibly a way for mempool to figure out for us what a good size would be).
-
We'll need to verify in a unit test that the RAM usage does not increase beyond a configured constant. I don't think this is currently happening in the code -- I think you have at least one instance of unbound memory usage. The mempool can have an unbound number of unmineable transactions, so we'll want to make sure the cache doesn't accidentally eat up all the RAM in the process of iteration.
jcnelson
left a comment
There was a problem hiding this comment.
So, one thing about this PR that still gives me pause is that once the caches are full, there's no eviction strategy. This means that it's possible for the miner to exhibit a pathological behavior where the first NonceCache::MAX_SIZE transactions are considered but are unmineable. Then, once we find the first mineable transaction, we'll always be encountering a cache miss on NonceCache::get(), which incurs a MARF read or (if you agree with my comment above) a database read.
As an easy-to-implement stop-gap to avoid thrashing, could you make the cache sizes configurable, and then plumb through that configuration from the node's config file? Then, at least miners could set higher MAX_SIZE values if they had enough RAM for it.
|
I think this PR needs more tests. I can take it over and write the tests that people want. I opened a discussion #3345 that depicts the mempool walk as a pipeline of transformations as follows. These are some levels at which we can add tests, in whichever style. |
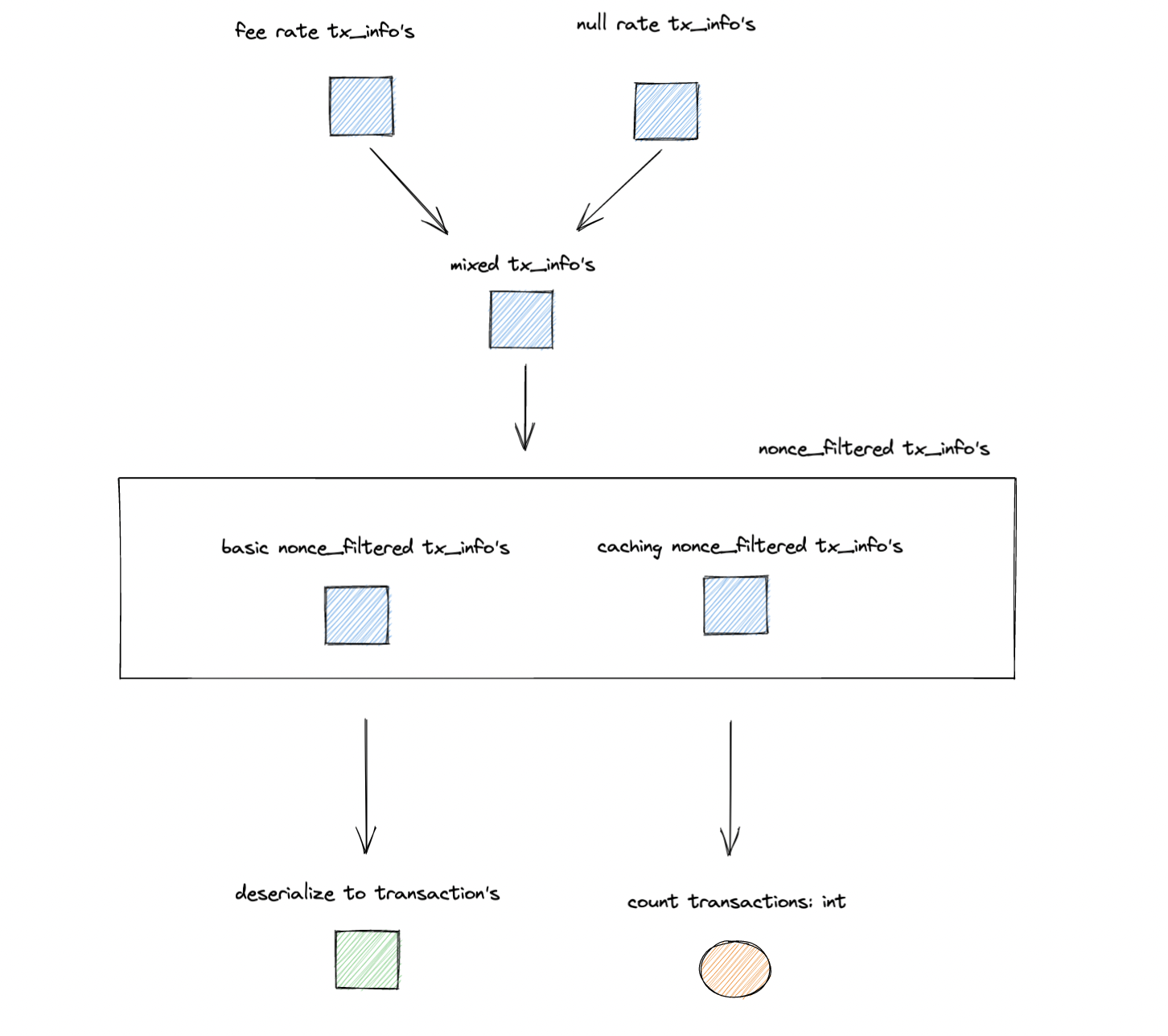
Clarified the "best effort", based on Greg's feedback.
I don't think so. If a transaction from origin address A at nonce N can't be mined, then neither can any transaction from A with nonce N+k. |
Thanks, that was my thought as well. What about |
|
Looks like we should only bump the nonces on |
On `TransactionEvent`s other than `Success`, the nonces should not be bumped because they indicate that the transaction is not included in the block.
src/core/mempool.rs
Outdated
|
|
||
| #[cfg(test)] | ||
| { | ||
| assert!(self.cache.len() <= self.max_cache_size + 1); |
There was a problem hiding this comment.
does this really need to be +1? i might have just put that when hacking.
There was a problem hiding this comment.
No, that should not need to be +1. I'll remove it in my next commit.
| let deadline = get_epoch_time_ms() + (self.settings.max_miner_time_ms as u128); | ||
| let mut block_limit_hit = BlockLimitFunction::NO_LIMIT_HIT; | ||
|
|
||
| mem_pool.reset_last_known_nonces()?; |
There was a problem hiding this comment.
We're not using any of the methods that manipulate the last_nonces columns, right? If so, then can you delete those as well, and add a comment to the schema that added these columns that they are no longer used?
There was a problem hiding this comment.
Sure. Just to be clear, you want to remove those columns from the DB in the latest schema in addition to deleting all of the related code?
There was a problem hiding this comment.
If it's not too much trouble -- i.e. if it can be done with a DROP COLUMN. Sqlite has a bunch of constraints on when you can and cannot do this, however, so don't worry about it if sqlite is preventing you.
There was a problem hiding this comment.
I'm seeing:
thread 'main' panicked at 'Failed to open mempool db: SqliteError(SqliteFailure(Error { code: Unknown, extended_code: 1 }, Some("near \"DROP\": syntax error")))', src/main.rs:739:14
But strangely, I can run the same query from the command line and it works.
ALTER TABLE mempool DROP COLUMN last_known_origin_nonce;
There was a problem hiding this comment.
Maybe sqlite allows it but rusqlite does not?
jcnelson
left a comment
There was a problem hiding this comment.
Overall this LGTM! Thank you for seeing this through @obycode @gregorycoppola!
Do you have new benchmark numbers? Can you instantiate this on a mock miner and see how it does?
 gregorycoppola
left a comment
gregorycoppola
left a comment
There was a problem hiding this comment.
assuming the mock miner and benchmarks are as expected, i approve.
thanks everyone!
I've run informally, but will collect new numbers now.
Yes, it is running now. Last block: |
|
@jcnelson those failing unit tests are due to the fact that they were depending on the fact that the old |
These tests were dependent on the old implementations increment of nonces when a transaction was skipped. The correct response is to only increment the nonces when the transaction is successfully included. Therefore these tests need to simulate a success event in order to get the expected behavior to be tested.
|
Tests updated in 1a65f0f. |
|
I am adding some unit tests to test the behavior with a skipped or problematic transaction. |
The old implementation incremented nonces when there was an error, problematic, or skipped transaction, which would cause it to then attempt to consider later nonces from the same addresses, incorrectly. Three new unit tests are added to check for these cases.
|
New unit tests added in 36690d0. |
|
|
||
| #[test] | ||
| /// This test verifies that when a transaction is skipped, other transactions | ||
| /// from the same address with higher nonces are not included in a block. |
There was a problem hiding this comment.
Specifically, we want it to be the case that these higher-nonce transactions aren't even considered.
There was a problem hiding this comment.
No action needed on this, btw. I'm happy to take it once I merge this to #3335
There was a problem hiding this comment.
That is what the test is checking, but you're right, the comment should be more clear. Thanks for handling that!
|
This pull request has been automatically locked since there has not been any recent activity after it was closed. Please open a new issue for related bugs. |
This is the cleaned up version of
simple-iteratordiscussed in #3326 and #3313.To-do before checking in: