To predict the material type of the to-be published research based on the document. Below are the different material types where the data should be published:
- Book
- Sound disk
- Video Cassette
- Sound Cassette
- Music
- Mixed
- CR
The dataset has been divided into train and test already.
- Train Data has 31,653 rows and 12 columns.
- Test Data has XXX rows and XXX columns.
Below given are the details about the different columns of dataset.
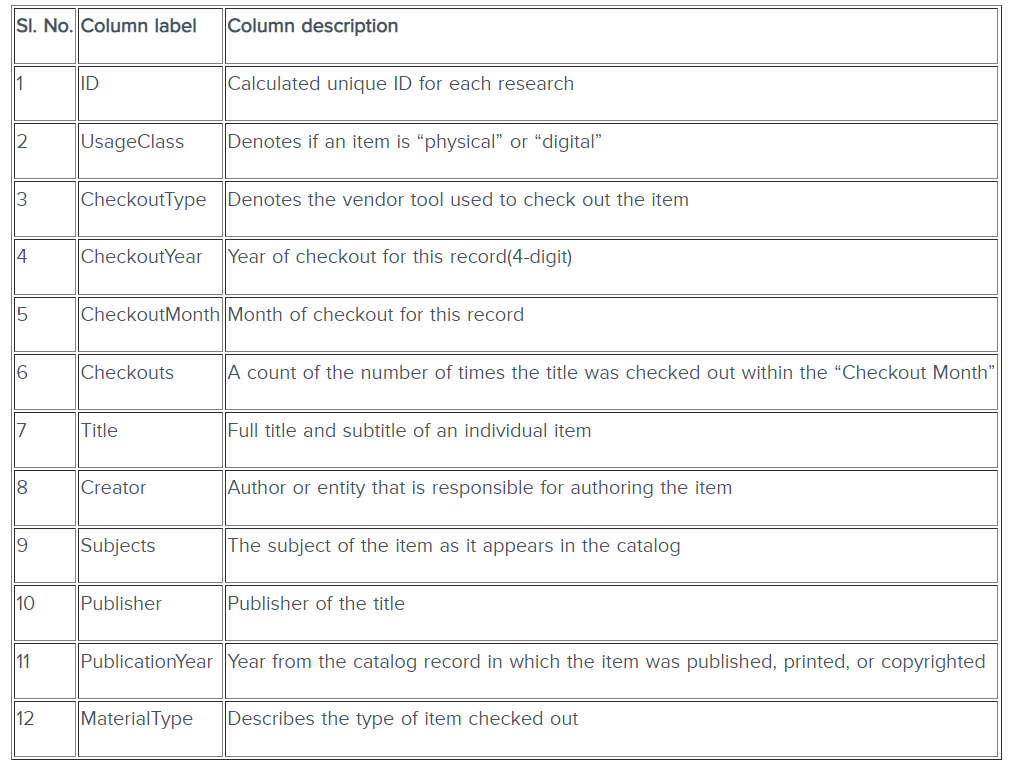
Below are some of the points that we found from the data :
- The full data is from UsageClass=physical, checkouttype=Horizon, and checkoutyear=2005, checkoutmonth=4
- No duplicate data is present in the data.
- Combination of Subject and title should be used to identify the materialtype.
- ~ 69% of the total data are having materialtype as BOOK, followed by SOUNDDISC(~ 13%) and VIDEOCASS(~ 9%).
- Since majority of the data has materialtype as BOOK, if we use this data as it is for model building, it will become imbalanced. For more details Click on Exploratory Data Analysis
First the data has been splitted into training and testing set and the preprocessed/cleaned. Then the data has been converted to TF-IDF matrix post which it has been fed into different machine learning algorithms. SVM and Random forest Classifier seemed to have the best accuracy, recall and precission score. Overall accuracy acheived is ~88%. For more details click on Model Creation
I am always open to suggestions, hence please provide if you have any. Show some love if you have benfitted from this content by starring the content or by following me.