Audio: Select: Optimize data copy operations #5053
Conversation
|
I'm now able to test in device, there's some problem in this version that needs to be fixed. |
40e2560 to
244f466
Compare
|
Here's plot of processing times for s16 and s24 data before and after optimize: |
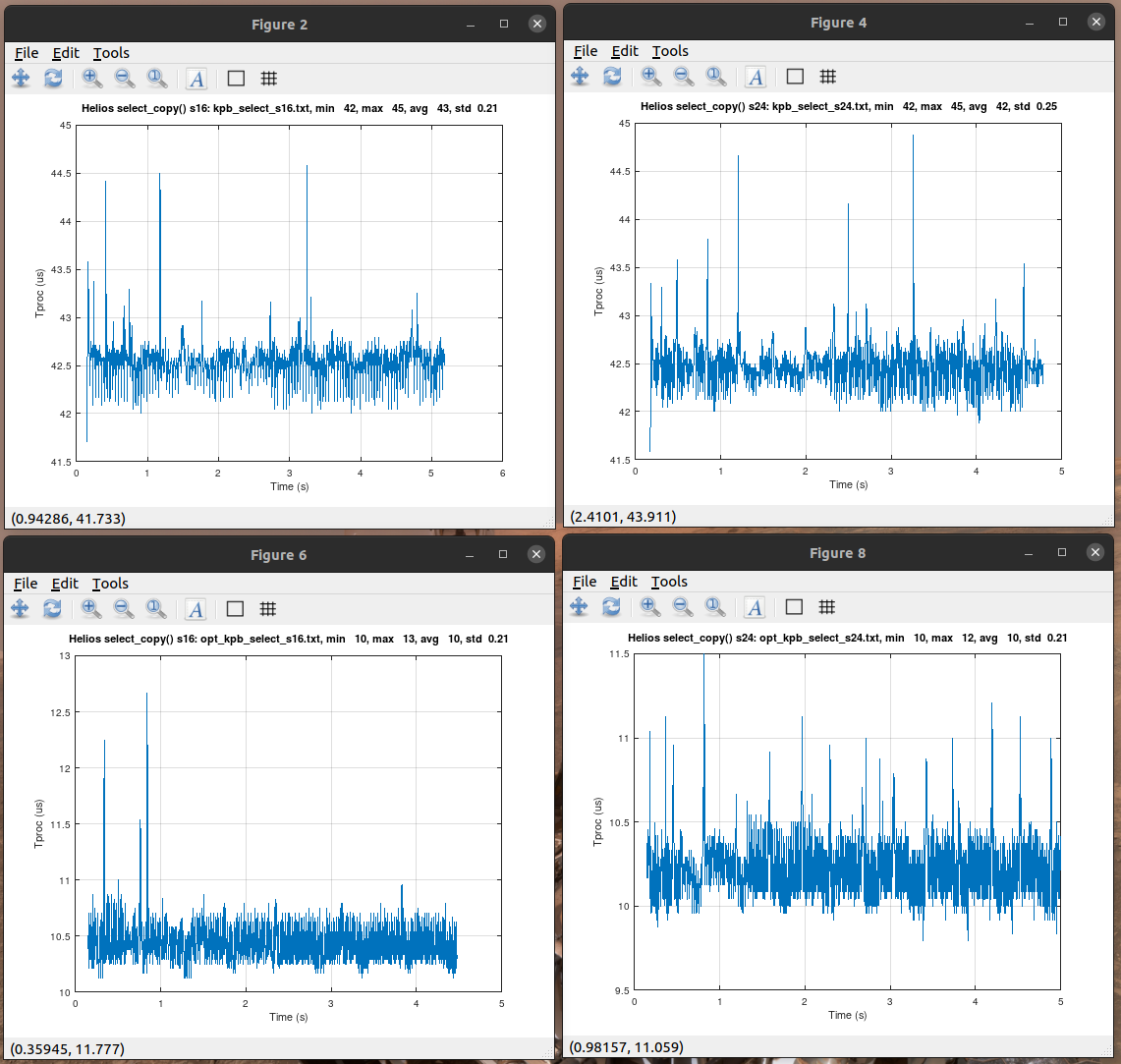
|
For s16 data the processing time dropped from average 43 us to 10 us, or 17 MCPS to 4 MCPS. For s24 data processing times drop is quite similar from 42 us to 10 us. |
There was a problem hiding this comment.
lets not assert here, we should return an error with a trace.
There was a problem hiding this comment.
I'd prefer to have config check before copy() streaming starts in params or prepare. There's some checks against max channel count but I could not find this. I'll see if I can add it there and remove this assert.
There was a problem hiding this comment.
since this will always be a multiple of 2 can we shift by sample_size (2 or 4) and mult by chans ? Means no divide.
There was a problem hiding this comment.
Samples count can be computed with shift but to get frames count would need to divide with channels. I'll see if I can build the inner loop other way to avoid divide here.
There was a problem hiding this comment.
I can't think of way to make this work with e.g. 3 channel to 1 without divide. The inner loop must operate with frames count and I can't change it to bytes (increments of frame bytes) because bytes max from source and sink are not "same thing". At least now I think so. The divide happens only max. twice per copy() so the cost is not high.
 lyakh
left a comment
lyakh
left a comment
There was a problem hiding this comment.
just a minor comment, nice optimisations otherwise!
There was a problem hiding this comment.
not a huge optimisation, but since you're using memcpy() now, src and dst don't need to be 16-bit pointers. You could make them 8-bit pointers and avoid shifting here. It might seem a bit counterintuitive to some, that we use 8-bit pointers in an S16LE copying function, so, it's up to you whether to make this change. There are more cases like this in this PR, possibly also in other your copy optimisation PRs.
There was a problem hiding this comment.
Yep, that would allow in compiled code to go from bytes to samples to bytes. I didn't do it because I was wondering if int8_t would get criticism. Let's re-try with bytes, it's at least most optimal code.
This patch replaces the per sample done circular copies with audio_stream_read/write_frag_s16/32() functions calls with max. length linear copies. The original copy function for >1ch sink is just 1:1 copy from source to sink without controllable channel select. This patch preserves the functionality and implements the copy with memcpy(). Signed-off-by: Seppo Ingalsuo <seppo.ingalsuo@linux.intel.com>
The optimized copy() functions could output data outside source buffer without this check. The test in params() checked only channel select parameter vs. max channels count. The changed code checks it vs. actual stream channels count. There's in params() a channels count check so this one could be modified. Signed-off-by: Seppo Ingalsuo <seppo.ingalsuo@linux.intel.com>
244f466 to
a8c2960
Compare
This patch replaces the per sample done circular copies with
audio_stream_read/write_frag_s16/32() functions calls with
max. length linear copies.
The original copy function for >1ch sink is just 1:1 copy
from source to sink without controllable channel select. This
patch preserves the functionality and implements the copy with
memcpy().
Signed-off-by: Seppo Ingalsuo seppo.ingalsuo@linux.intel.com