Audio: EQFIR: Optimize source and sink buffers use in generic C version #5339
Conversation
|
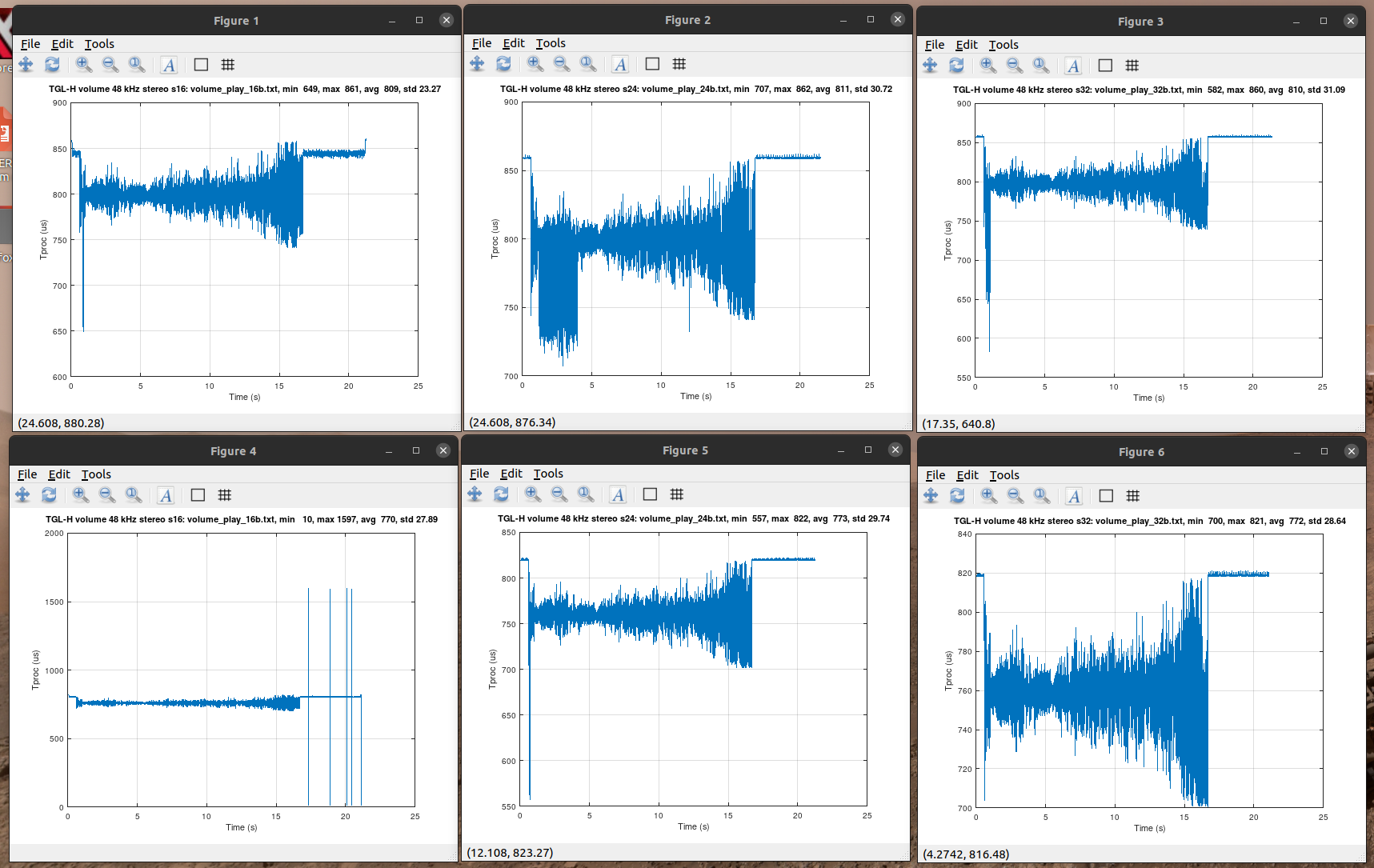
Here's test run with forced generic C version and 250 tap stereo FIR for xtensa build. The gcc build was not fast enough for realtime.
Processing load in original was 324 MCPS, in optimized 309 MCPS, saving is 15 MCPS. The load is nearly same for all formats s16/s24/s32. Note: There's some strange variation in processing times in end of s16 playback with 10 us and 1500 us processing times seen and not steady 770 us. Need to find out why it happens in optimized version. I tried twice and got the same. |
e5f588e to
b279e79
Compare
|
@singalsu GCC generic C build will likely need a reduced TAP count and hence performance. This can be in the Kconfig though so it's spelled out. i.e. a Kconfig setting with TAP count and comments directing users to low tap count for GCC. |
|
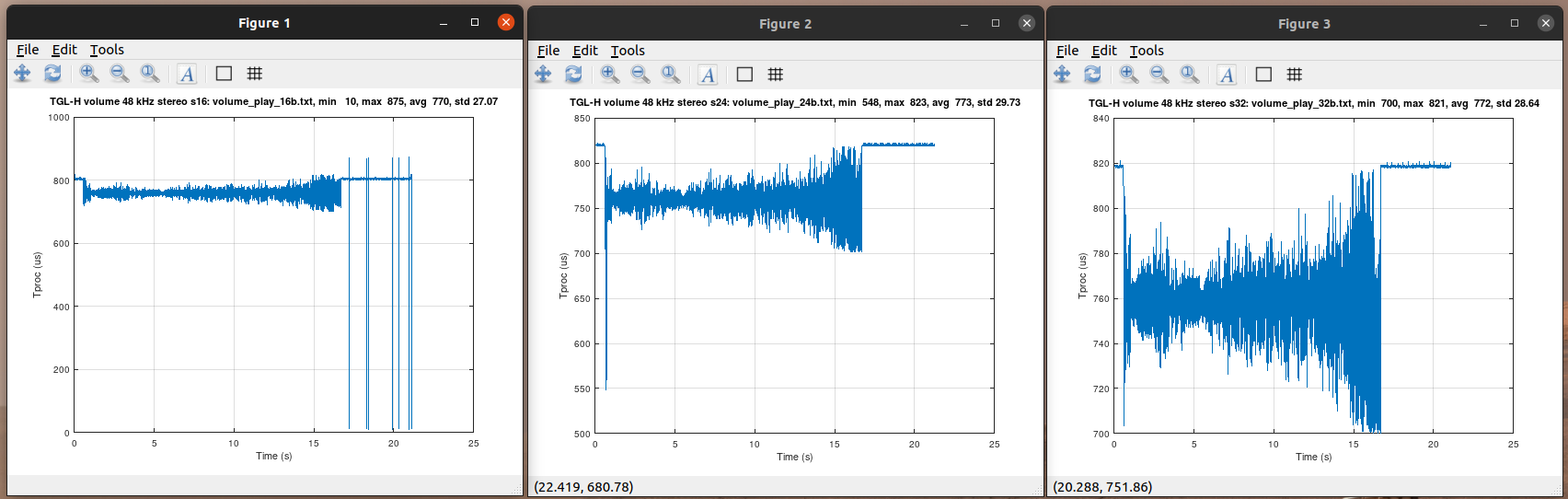
The add of 10% limit over nominal fixed the issue that happened with 16 bit data. Now the max 875 us is hit with a few times 52 frames processed. The plot looks similar as before but no more 1500 us processing. The 10 us processings happen when FIR is scheduled with 0 frames available. This is still with xtos.
|
b279e79 to
fbd8146
Compare
src/audio/eq_fir/eq_fir.c
Outdated
There was a problem hiding this comment.
This should be best coming from topology and be generic. The first patch is fine.
There was a problem hiding this comment.
Sorry, I'm not aware of such. How?
There was a problem hiding this comment.
OK, I'll remove the 2nd commit, configuration that results to high load is unusual. The non-even data flow must originate from host PCM. Other high load components use also this way of limiting processing time: SRC, ASRC, TDFB.
There was a problem hiding this comment.
Done, but this needs a fix somewhere in the framework.
This patch replaces the audio stream read/write frag based access to source and sink by block processing based on audio_stream_bytes_without_wrap() bytes count. In a test with forced generic C for xtensa build processing load in original was 324 MCPS, in optimized 309 MCPS, saving is 15 MCPS. The load is nearly same for all formats s16/s24/s32. The base load was very high in test due to a very long used FIR filter. The MCPS saving should be the same for all stereo 48k streams. Signed-off-by: Seppo Ingalsuo <seppo.ingalsuo@linux.intel.com>
fbd8146 to
4ad3e1f
Compare
|
@marc-hb fyi the test is reporting PASS in the console but a TIMEOUT in the dashboard. https://sof-ci.01.org/sofpr/PR5339/build11990/devicetest/?model=CML_SKU0955_HDA&testcase=check-suspend-resume-with-playback-5 |
 jsarha
left a comment
jsarha
left a comment
There was a problem hiding this comment.
Don't understand about to context too much, but the optimizations themselves make sense and look correct.
This patch replaces the audio stream read/write frag based
access to source and sink by block processing based on
audio_stream_bytes_without_wrap() bytes count.
Signed-off-by: Seppo Ingalsuo seppo.ingalsuo@linux.intel.com