Audio: volume: Optimize source and sink buffers usage #5452
Conversation
 lgirdwood
left a comment
lgirdwood
left a comment
There was a problem hiding this comment.
@andrula-song do you have a before and after MCPS value to show as why this should be merged ?
|
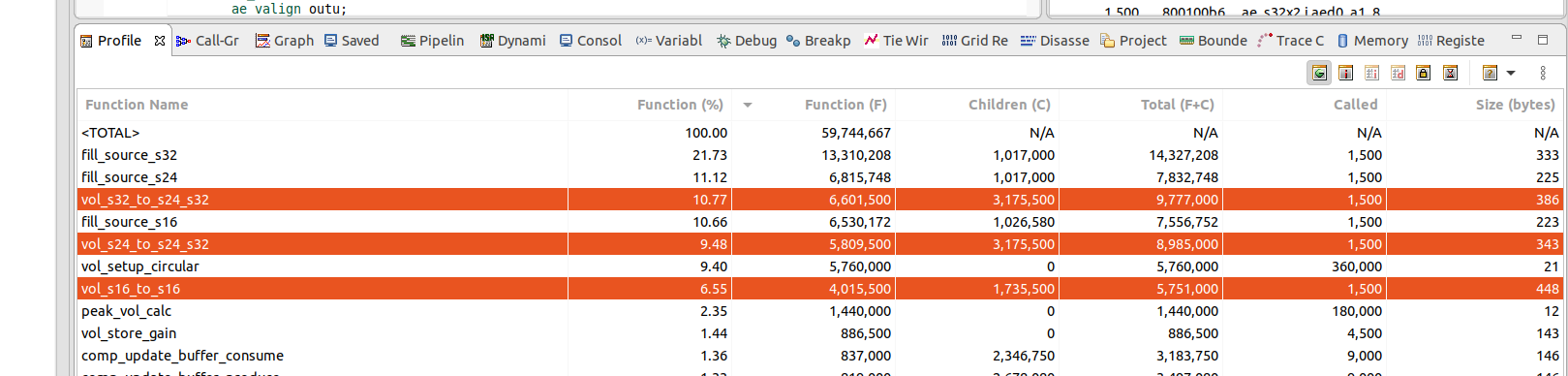
hi @lgirdwood , the specific platforms's statistic have not been measured yet. but by the xtensa simulation testbench Seppo sent me, the cycles the processing function spent would reduce about 25% than now. In this way, there would only be one circular buffer, we only set the begin and end address once in processing function rather than 3 times in every for loop in processing function. I want to make sure there are no other potential bugs before giving specific measurements. |
|
from the xtensa test bench, after this optimization, each format reduce many the cycles the scale_vol function cost. the original result is: for S16 format, opt version cost 4281000 cycles, the original version cost 5751000 cycles, reduce about 25% cycles |

|
@singalsu good for you ? |
 singalsu
left a comment
singalsu
left a comment
There was a problem hiding this comment.
Great that this idea worked. Good work!
|
@andrula-song any reason why this is still draft ? |
|
This patch replaces the audio stream read/write frag based access to source and sink by block processing based on audio_stream_bytes_without_wrap() bytes count. In this way, the copy and scale volume function can reduce about 25% cycles for S16, 34% for S24 and 30% for S32. Signed-off-by: Andrula Song <xiaoyuan.song@intel.com>
|
SOFCI TEST |
|
@plbossart @bardliao CI showing a SDW timeout and a rt711 jack timeout on PM test. |
@lgirdwood It is unrelated to this PR. See thesofproject/linux#3459 |
|
SOFCI TEST |
|
the failure items is unrelated with this PR, because daily test exist, too. |
This patch replaces the audio stream read/write frag based
access to source and sink by block processing based on
audio_stream_bytes_without_wrap() bytes count.
Test all platform first.
Signed-off-by: Andrula Song xiaoyuan.song@intel.com