benchmark for dvc status with different numbers of ignore rules#30
Conversation
1. reduce files in data prevent `dvc add` causing timeout failure. 2. quiet mode
|
|
@karajan1001 would it be better to have |
From my understanding, |
This is because the test runs for several times. And in each time calculating md5 and adding files to the cache took server seconds. Now I put |
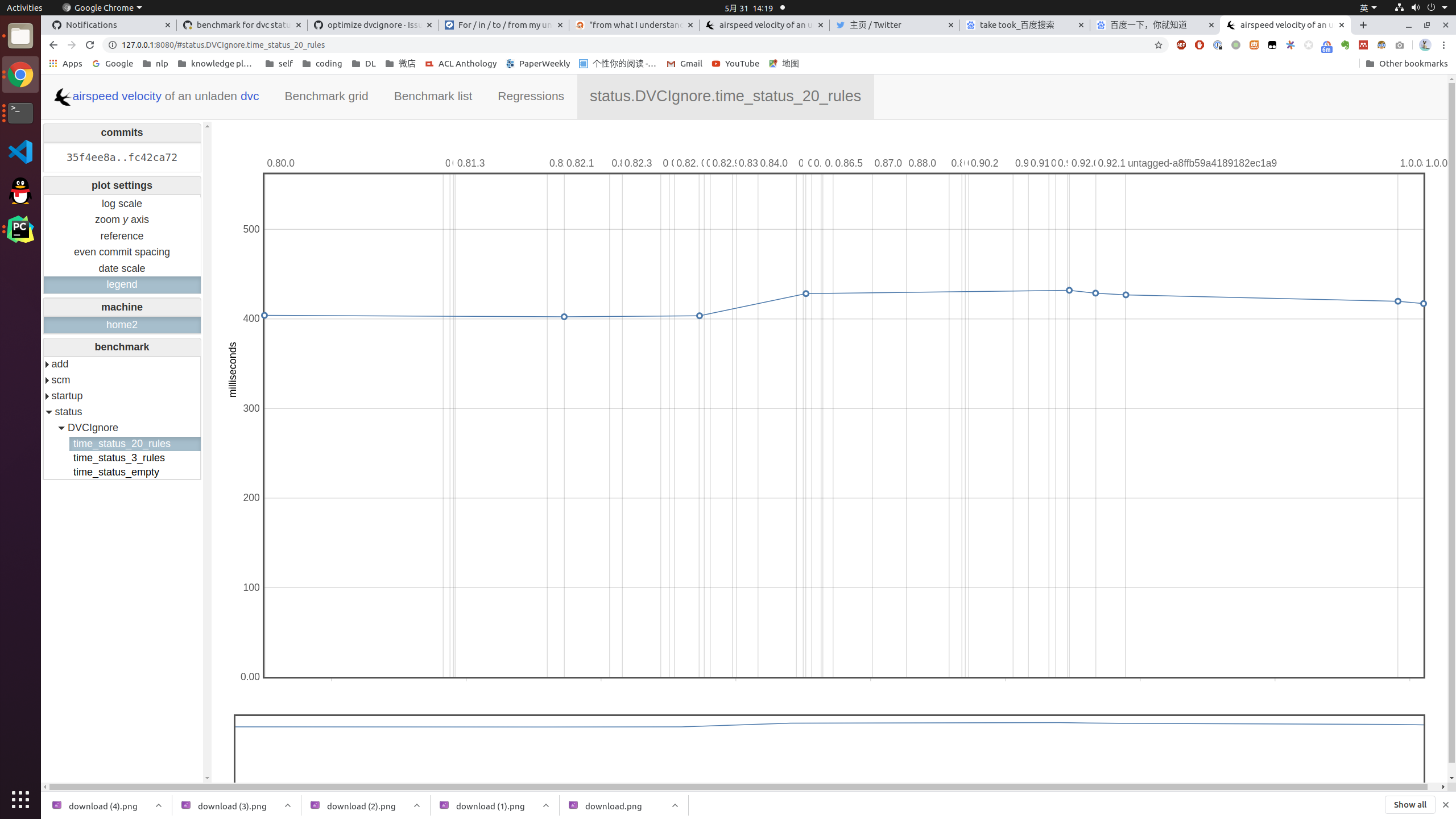
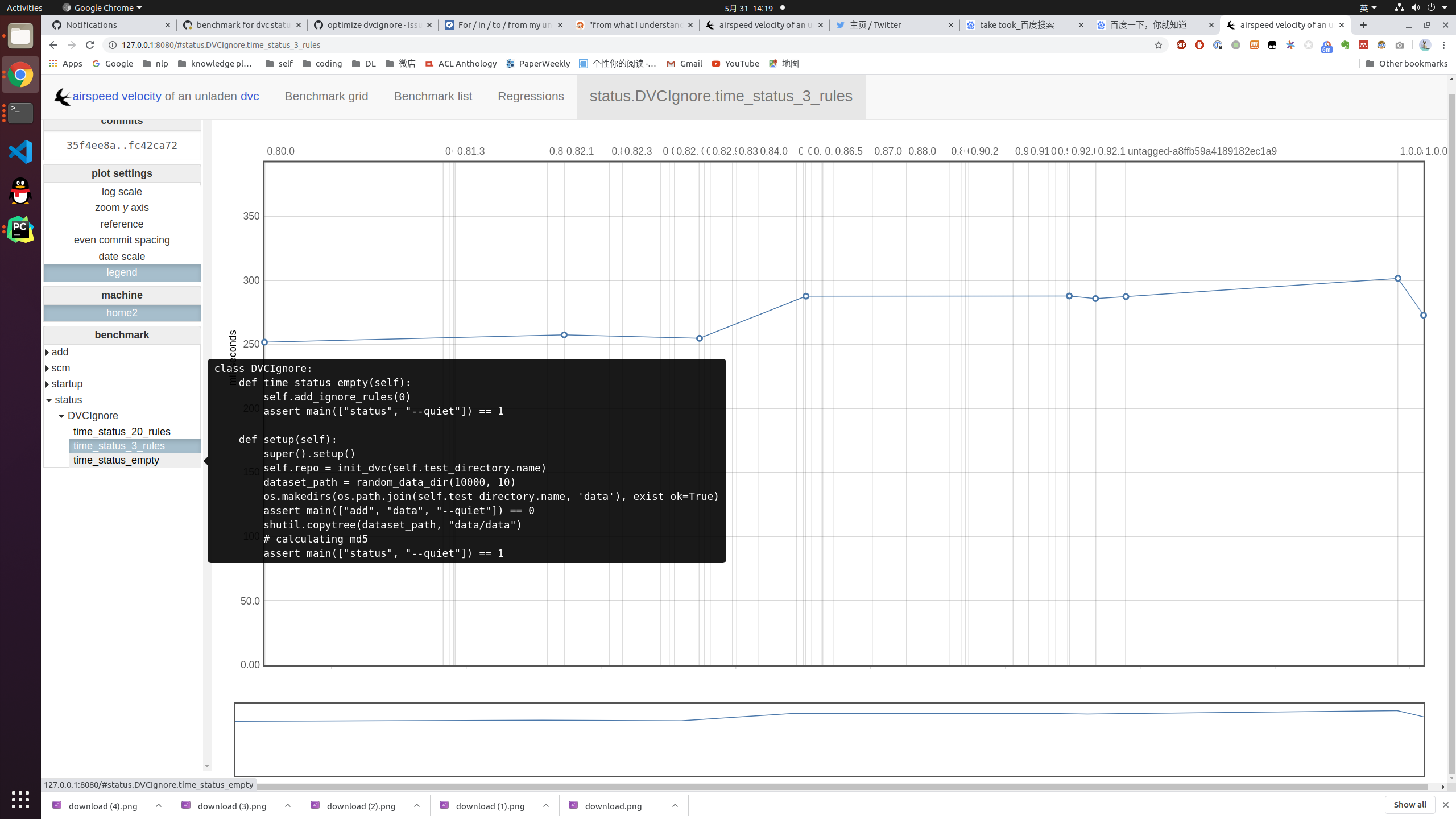
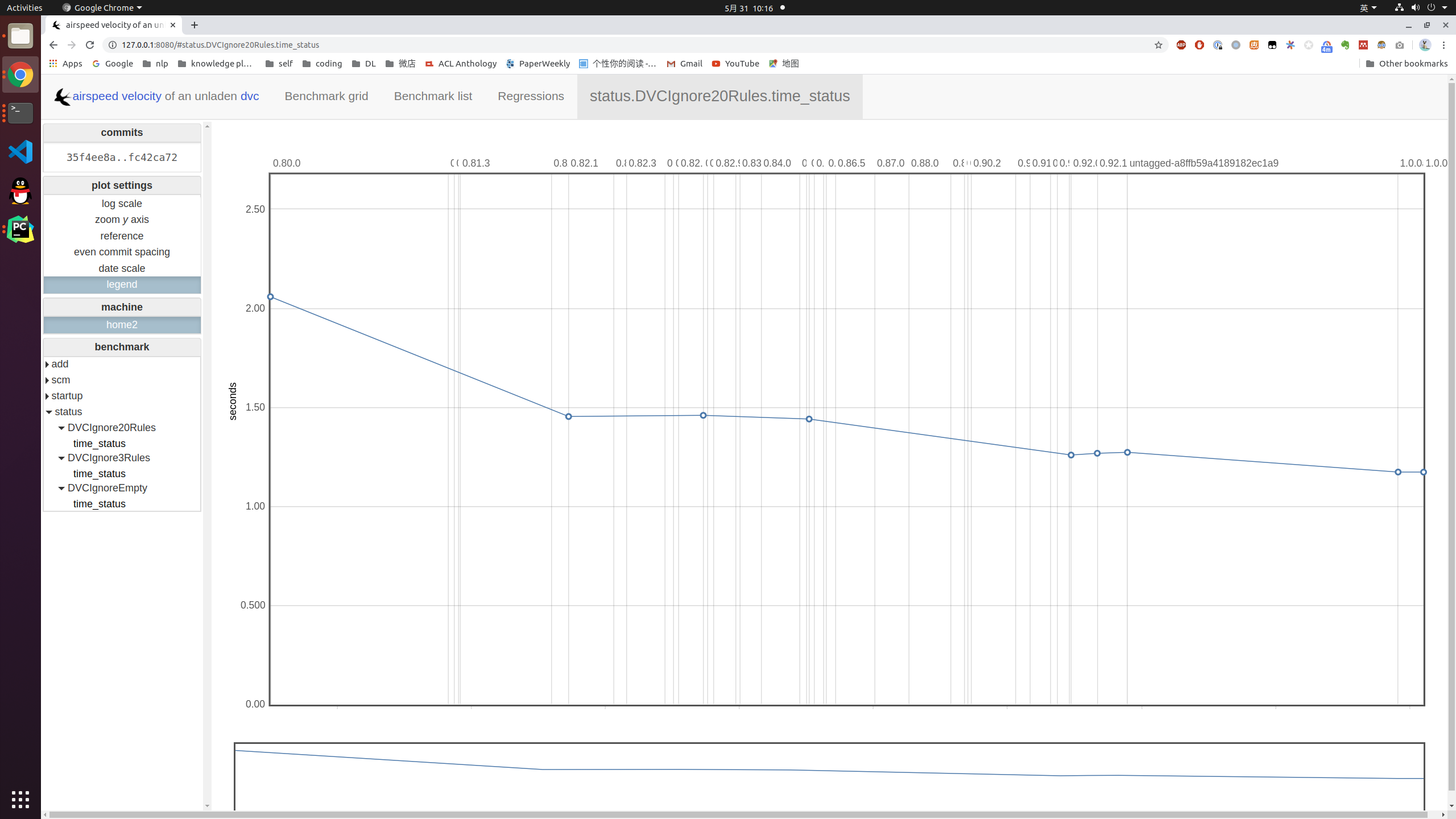
After these changes, here is the result. 20 ignore rules with 10k files tracked
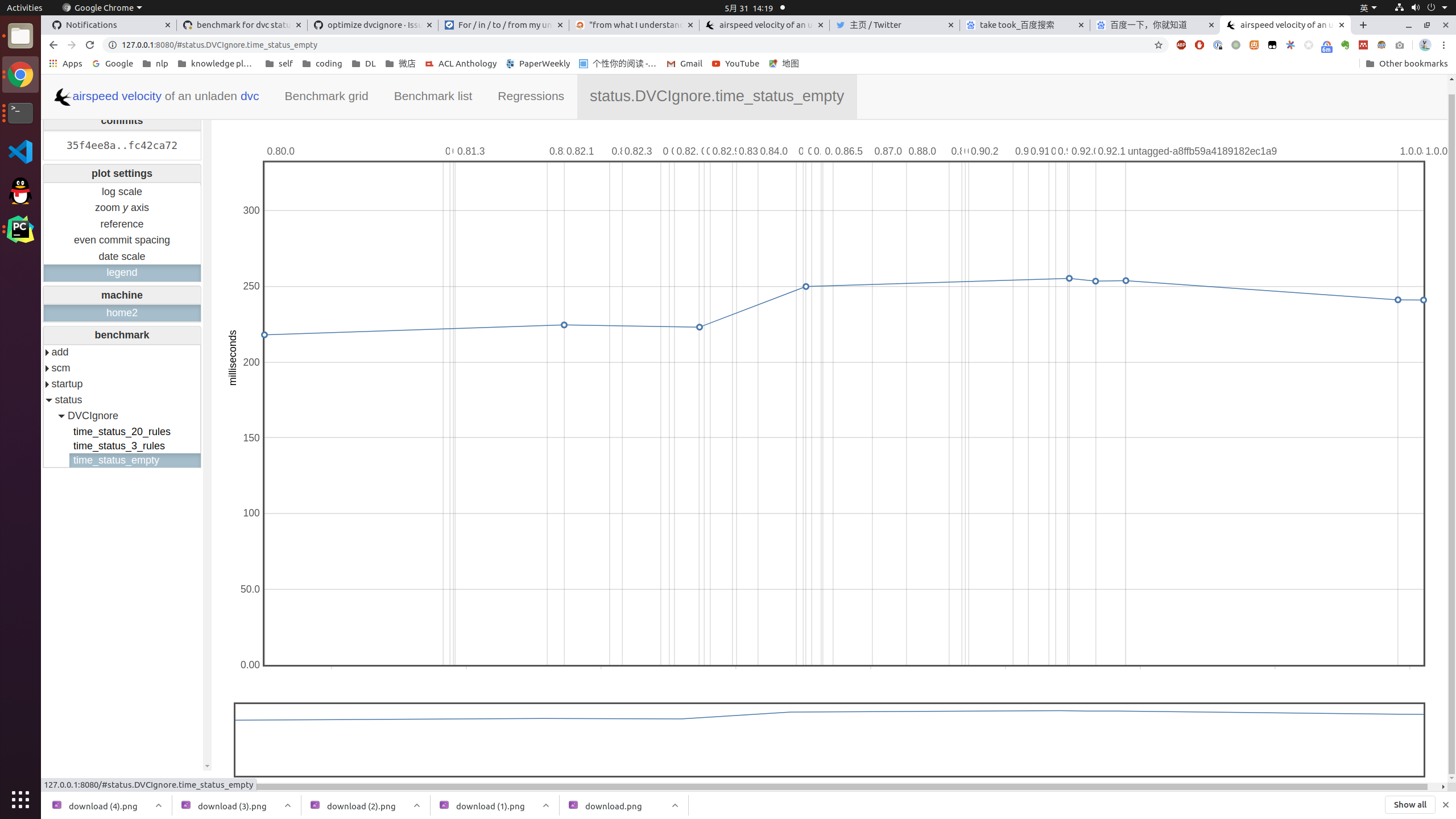
Empty ignore rules file with 10k files tracked
These results matches |
A new test with 3 ignore files with 10 rules compare to one file with 30 rules
|
Add one more test 1 ignore file with 30 rules compare to 3 ignore file with 10 rules each. 1 file 30 rules 3 file each has 10 rules |
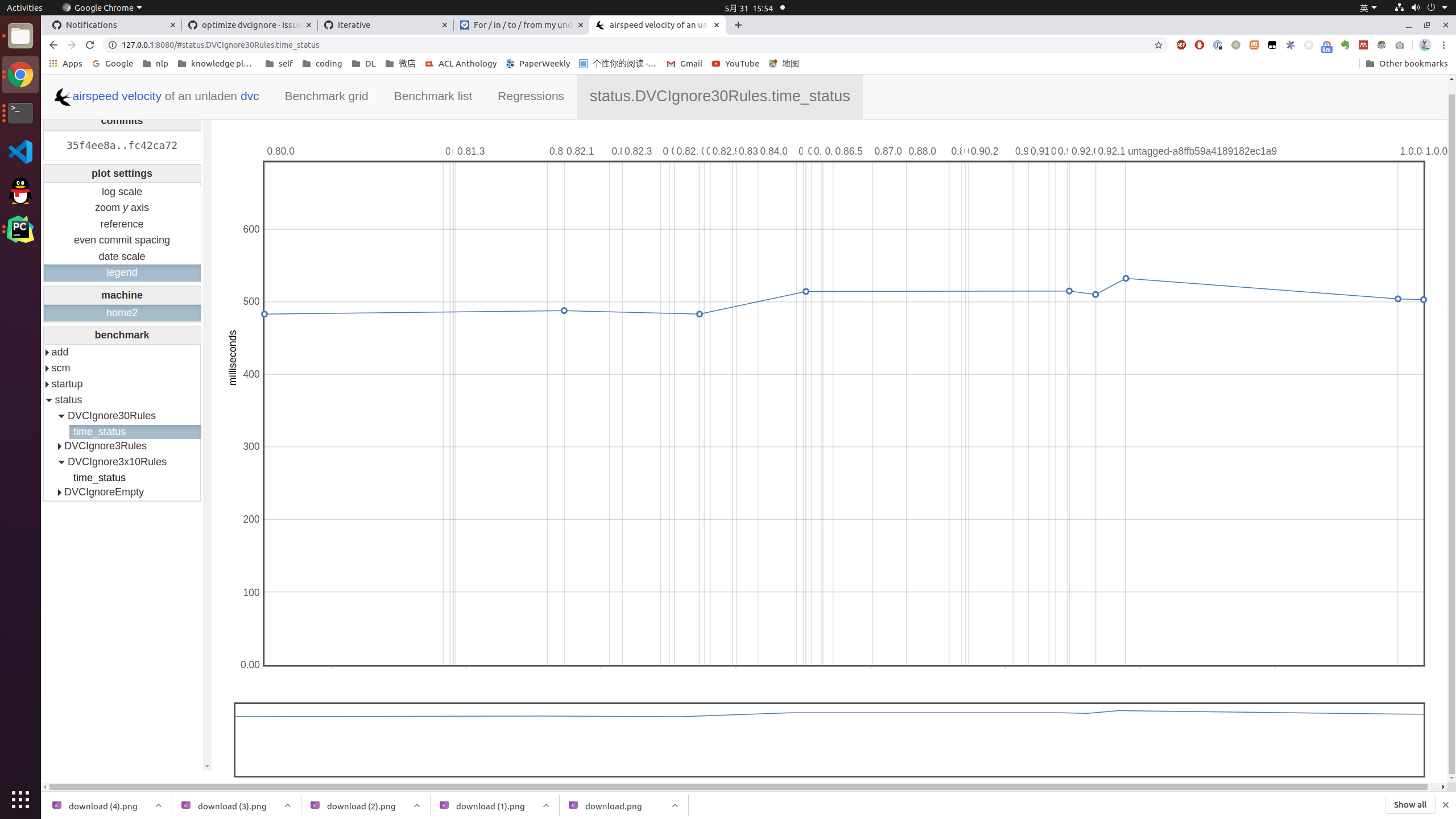
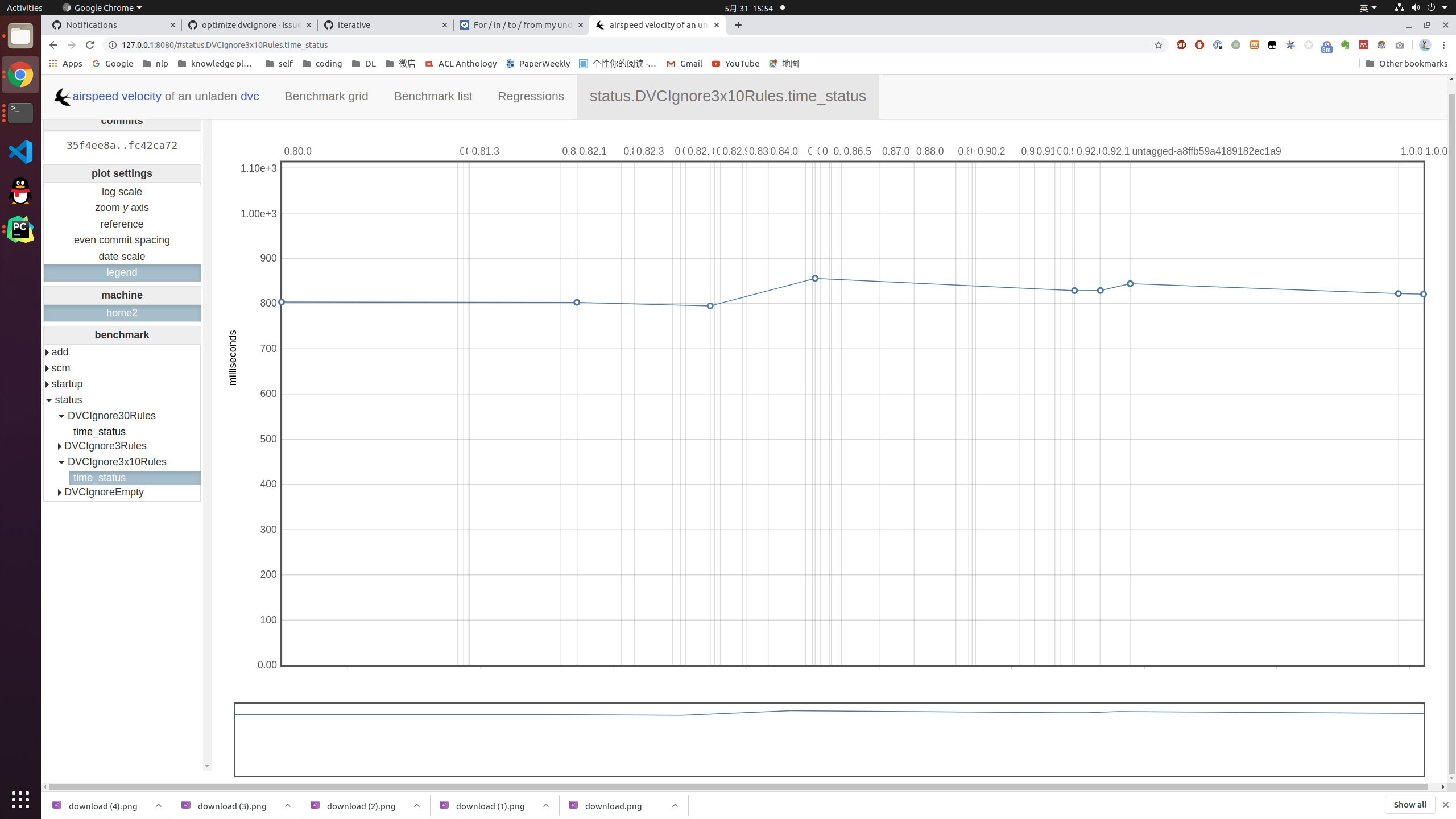
|
Please wait for a moment.
|
The |
|
@karajan1001 The problem with it is that this method writes pickled setup result to disk, and loads it upon next execution of benchmark. In case of DVC, that does not make sense as we are operating on a directory/repository which changes state during benchmark execution. |
Yes, our setup is of paths and files, not python in-memory objects. Currently, the whole bench takes 10 minutes on my computer, only a quarter compared to the first edition. There is only one problem remains that each |
|
@karajan1001 |
Thank you @pared you gave me the right answer. According to ASV And I tested that in deleting |
|
@karajan1001 also, I created #33, not sure whether this profiling makes sense, maybe we should do it only when we notice degradation in performance. |
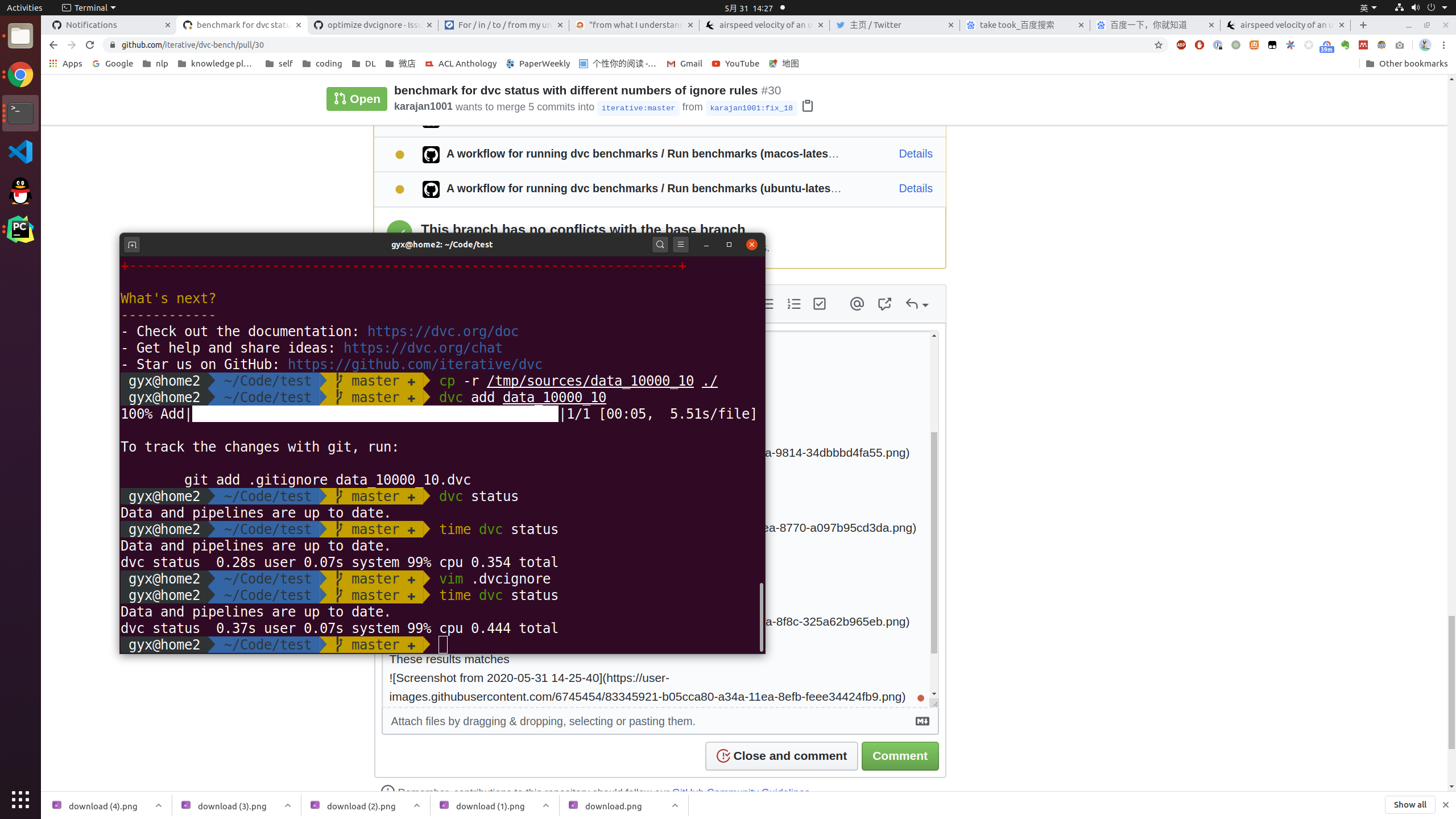
| ) | ||
| assert main(["add", "data", "--quiet"]) == 0 | ||
| shutil.copytree(dataset_path, "data/data") | ||
| # calculating md5 |
|
Now that I think about it, shouldn't we just have a single benchmark, with, multiple ignore rules? I mean having 0, 3 and 30 seems to me like creating tests to compare The point of I would consider leaving 30 rules case as is, removing 3 rules use case and moving 0 cases to What do you think @karajan1001? |
Sorry for the late reply, I agreed with this.
Yes, the zero 30 rules comparing 3 rules can tell us how the time cost grows with the increase of |
Please take a note of @efiop comment under the profile issue. We can leave the profiles, in order to have analysis materials if something goes south. |
@pared @efiop |
|
I agree, to see the detailed difference in case 3 vs 30, we would need to compare charts for both tests. And the main point of this repo is to fulfill #8, which will be hard to programmatically define in case of comparing 2 benchmarks. So let's get rid of it for now? |
|
@karajan1001 great change! Thank you very much! |
20 ignore rules with 10k files tracked
3 ignore rules with 10k files tracked
Empty ignore rules file with 10k files tracked