Add blog about auto tuning for all hardware platforms #21
Add blog about auto tuning for all hardware platforms #21tqchen merged 17 commits intotvmai:masterfrom merrymercy:master
Conversation
|
@eqy Can you do a round of review if you have time? |
 eqy
left a comment
eqy
left a comment
There was a problem hiding this comment.
just a bunch of nits, overall great work on this blog post
really nice to see the big picture milestone done
| - tvm | ||
| --- | ||
|
|
||
| How to optimize the performance of deep neural network on a diverse range of hardware platforms is still a hard |
There was a problem hiding this comment.
Optimizing deep neural network performance on a diverse range of hardware platforms...
| How to optimize the performance of deep neural network on a diverse range of hardware platforms is still a hard | ||
| problem for AI developers. In terms of system support, we are facing a many-to-many problem here: | ||
| deploying trained models from multiple frontends (e.g. Tensorflow, ONNX, MXNet) to multiple | ||
| hardware platforms (e.g. CPU, GPU, Accelerators). On the most performance critical part of |
There was a problem hiding this comment.
The most performance critical part of this problem is obtaining high performance kernel implementations...
| this problem is how to get high performance kernel implementation for growing model | ||
| architectures and hardware platforms. | ||
|
|
||
| To address this challenge, TVM takes a full stack compiler approach. Combining code generator and auto-tuner in TVM, |
There was a problem hiding this comment.
TVM combines code generation and auto-tuning to generate kernels... , obtaining state-of-the-art inference performance including...
| and obtain the state-of-the-art inference performance on hardware platforms including | ||
| ARM CPUs, Intel CPUs, Mali GPUs, NVIIDA GPUs and AMD GPUs. | ||
|
|
||
| In this blog post, I will show the workflow of automatic kernel optimization in TVM compiler stack and |
|
|
||
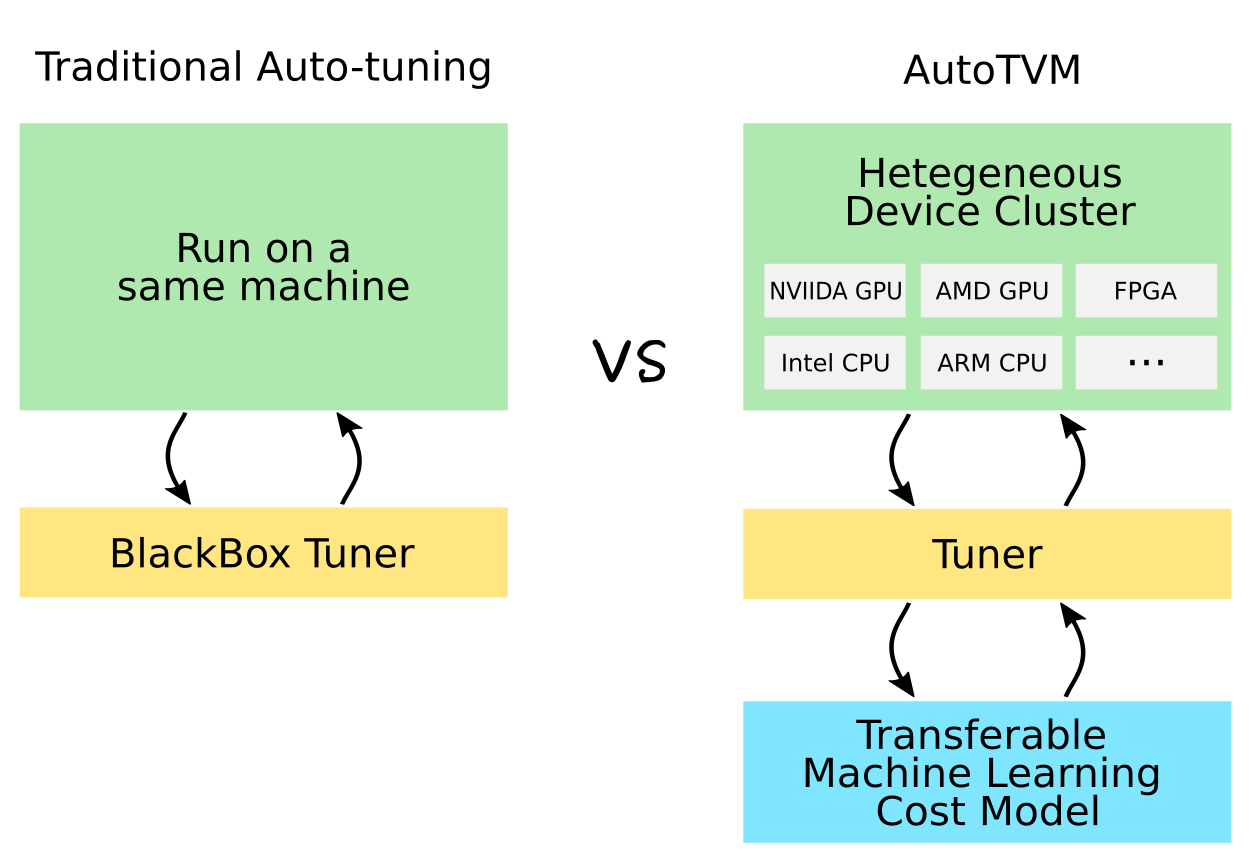
| Kernel optimization in TVM is done in an iterative loop fashion. | ||
| As shown in Figure 1, the automatic kernel optimization takes a neural network (typically in computational graph representation) | ||
| from frontend frameworks as input, and generates kernels for all the operators in this network. |
There was a problem hiding this comment.
... for all operators in the network.
|
|
||
| Finally let we take a look at AMD GPU. TVM supports OpenCL and [ROCm](https://rocm.github.io/) backend. We found ROCm is better since | ||
| it is more specialized for AMD GPUs. In terms of baseline, [MIOpen](https://github.com/ROCmSoftwarePlatform/MIOpen) is a vendor provided | ||
| kernel library. We integrate its kernel implementation in TVM graph runtime. |
There was a problem hiding this comment.
TVM's graph runtime integrates its kernel implementations (maybe clarify that this is optional and not relied upon for generating optimized code)
| it is more specialized for AMD GPUs. In terms of baseline, [MIOpen](https://github.com/ROCmSoftwarePlatform/MIOpen) is a vendor provided | ||
| kernel library. We integrate its kernel implementation in TVM graph runtime. | ||
|
|
||
| We didn't do any specific optimization for AMD GPU. Instead, all computation definition/schedule code for NVIDIA GPU is directly reused. As for the results, TVM is a little bit slower then MIOpen in most cases. |
There was a problem hiding this comment.
In this case, we reuse ... from NVIDIA GPUs
As a result, TVM ... , (but maybe mention that there is room for improvement)
| | | | ||
|
|
||
| * Note 1: Out of memory on this board. | ||
| * Note 2: We didn't tune some small networks on GPU due to time limit. TVM can use its fallback mechanism to compile them but the performance is not guaranteed. |
There was a problem hiding this comment.
... due to time contraints...
When profiling data is not available... TVM can use fallback code generation (but competitive performance is not guaranteed in this scenario).
|
|
||
| * Note 1: Out of memory on this board. | ||
| * Note 2: We didn't tune some small networks on GPU due to time limit. TVM can use its fallback mechanism to compile them but the performance is not guaranteed. | ||
| So their results are omitted here. |
| [NVIDIA/AMD GPU](https://docs.tvm.ai/tutorials/autotvm/tune_nnvm_cuda.html) | ||
| are all available. Try tuning for your custom network and hardware devices. | ||
|
|
||
| For Intel CPU, right now it is under refactor, but you can take a look at the |
There was a problem hiding this comment.
(Intel CPU is currently being refactored...
|
Thanks! Review comments are addressed. Learned a lot about writing. |
|
|
Also maybe the comparison figures are better in landscape mode vs the current vertical mode |
I think is ready for publish. I changed the date to Oct. 3. |
|
OK, some final comments:
|
| With an expressive code generator and an efficient search algorithm, we are able to | ||
| generate kernels that are comparable to heavily hand-optimized ones. | ||
| Since programmer time is expensive and machine time is getting cheaper, | ||
| we believe the auto-tuning with real hardware and data in the loop will be the standard workflow |
There was a problem hiding this comment.
auto-tuning-> automatic program optimization
| ### NVIDIA GPU | ||
|
|
||
| On NVIDIA GPU, [CuDNN](https://developer.nvidia.com/cudnn) and [TensorRT](https://developer.nvidia.com/tensorrt) are two vendor-provided libraries for training and inference respectively. Since we focus on inference, | ||
| we run our benchmark in the unbatched setting. Another tensor compiler [PlaidML](https://github.com/plaidml/plaidml) is also reported as baseline. |
There was a problem hiding this comment.
we also include PlaidML as a baseline as there is a previous benchmark of it compared against a pre-AutoTVM version of TVM.
|
Fixed with up-to-date preview http://lmzheng.net/posts/2018/10/auto-tune-all |
preview http://lmzheng.net/posts/2018/10/auto-tune-all
Depends on apache/tvm#1796