ARROW-11843: [C++] Provide async Parquet reader #9620
Conversation
05f8c14 to
d4f60f4
Compare
|
CC @westonpace here as well. |
 westonpace
left a comment
westonpace
left a comment
There was a problem hiding this comment.
I might be wrong but I don't think this will quite work as written. Let me know if I've misunderstood.
cpp/src/parquet/arrow/reader.h
Outdated
There was a problem hiding this comment.
Answering your question I agree it would be better to have AsyncGenerator<RecordBatch> for consistency with the other readers. You can use MakeVectorGenerator to get AsyncGenerator<AsyncGenerator<RecordBatch>>. Then apply MakeConcatMapGenerator to the result to get to AsyncGenerator<RecordBatch>
cpp/src/parquet/arrow/reader.h
Outdated
There was a problem hiding this comment.
Would the scan task be the thing providing the row_group_indices?
There was a problem hiding this comment.
Yes, currently scan tasks know which row group index they correspond to. As part of this we may want to make scan tasks less granular than a single row group as discussed.
cpp/src/parquet/arrow/reader.cc
Outdated
There was a problem hiding this comment.
Hmm, historically that hasn't been the precedent for the generators. They keep an ownership stake in their resources. Is there some reason the generator can't have a shared pointer to the reader?
Consider the dataset scanning example. The scan tasks will be asked for a generator and the scanner will keep track of the generator but the scanner will have no idea what the reader is. Who is keeping track of the reader there? What if the scanner simply discarded the scan task after it got a generator from it.
There was a problem hiding this comment.
Note that it's true for the RecordBatchReader for Parquet as well; if you look at ParquetScanTask in dataset/file_parquet.cc, there's a similar note there. I think it's solely because we don't have enable_shared_from_this for the Parquet readers, I'm not sure if there's a reason why we omit that.
There was a problem hiding this comment.
Ok, I might be breaking this. The current Scanner::ToTable keeps the scan task alive while it iterates the batches...
ARROW_ASSIGN_OR_RAISE(auto batch_it, scan_task->Execute());
ARROW_ASSIGN_OR_RAISE(auto local, batch_it.ToVector());
state->Emplace(std::move(local), id);
However, the async version does not...
ARROW_ASSIGN_OR_RAISE(auto batch_gen, scan_task->ExecuteAsync());
return CollectAsyncGenerator(std::move(batch_gen))
.Then([state, id](const RecordBatchVector& rbs) -> util::optional<bool> {
state->Emplace(rbs, id);
return true;
});
There was a problem hiding this comment.
I can go ahead and copy the scan task into the Then callback to preserve its lifetime but can you add a comment to ScanTask explaining this requirement?
There was a problem hiding this comment.
I think that's supposed to be ok: iterating the scan task should implicitly keep the scan task alive, what I meant is that the scan task is explicitly keeping the Parquet reader alive.
cpp/src/parquet/arrow/reader.cc
Outdated
There was a problem hiding this comment.
This will be a problem. I think this task will block (I'm assuming ReadRowGroupsImpl is synchronous and blocking?) Blocking tasks should not be on the CPU pool. You could put it on the I/O pool but that isn't necessarily ideal either as it complicates sizing the I/O pool.
Ideally you want something like reader_->PreBuffer(row_groups, ...).Then(NonBlockingReadRowGroupsImpl).
I think you might kind of get away with it because the task they are waiting on is on the I/O thread pool (I assume the prebuffering tasks are on the I/O pool) so you won't have the nested deadlock problem.
However, it will not have ideal performance. If you are reading a bunch of files you will have some CPU threads tied up waiting that could be doing work.
There was a problem hiding this comment.
Ah, ok - I was envisioning that the caller would explicitly buffer beforehand (since we had been talking about splitting up ScanTask in that way) but we can have this manage buffering internally as well. (Either way, either the IPC reader or the Parquet reader will need some refactoring to meet Datasets' needs.)
There was a problem hiding this comment.
Ok, if you plan to do that buffering elsewhere then this is fine. I guess I misunderstood then. So the point in breaking things into tasks here is to allow for parallelism?
There was a problem hiding this comment.
Yes, this is to allow for parallelism when scanning a Parquet file. Though as I think about it, maybe this isn't necessary? We can do the parallelism at the scan task level already.
There was a problem hiding this comment.
Maybe we can hold this until ARROW-7001 is through and then we can see what exactly we need to be reentrant to get the pipeline we want.
|
(FWIW, I'm currently reworking this so that it gives just |
d4f60f4 to
4ffac4e
Compare
|
What I pushed is still not quite what I want. Ideally, we'd be able to ask the read cache for a future that finishes when all I/O for the given row group has completed. That way, we can then kick off a decoding task. On master, currently, you just spawn a bunch of tasks that block and wait for I/O and then proceed (wasting threads), and in this PR, we have hijinks to manually pre-buffer each row group separately (wasting the effectiveness of pre-buffering). That is, we should be able to say and this will let us coalesce read ranges across row groups while only performing work on the CPU pool when it's truly ready. Also, the range cache will have to be swappable for something that just does normal file I/O for the non-S3 case so that local file scans are still reasonable. |
|
Ok, something wonky is going on here, but… I confirmed that both benchmarks read the same number of rows/columns, but this still seems rather unbelievable/there must be some sort of measurement error. |
|
The benchmark discrepancy is simply because the generator was putting each row group on its own thread. The difference goes away if we don't force transfer onto a background thread. (snipped when I realized I had benchmarked the wrong code for this PR) |
|
Okay, now that I've actually checked out the right branch… So long as pre-buffering is enabled, this PR in conjunction with ARROW-7001 is either a big win (for S3) or no effect (locally). Hence I'd argue we should just always enable pre-buffer. (The reason is that without refactoring the Parquet reader heavily, without enabling pre-buffer, the generator is effectively synchronous. I could go through and do the refactor, but pre-buffering gives us an 'easy' way to convert the I/O to be async. If we want, we could change the read range cache to optionally be lazy, which would effectively be the same as refactoring the Parquet reader.) Also, this changes the ParquetScanTask so that it manages intra-file concurrency internally. Hence, ParquetFileFragment only needs to generate one scan task now and doesn't have to do anything complicated around pre-buffering.
|
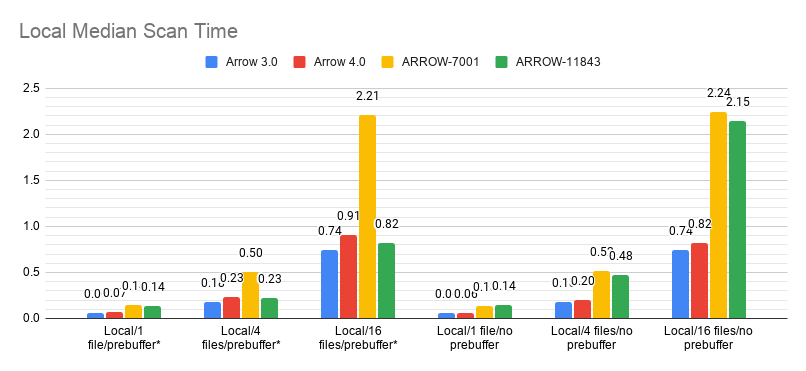
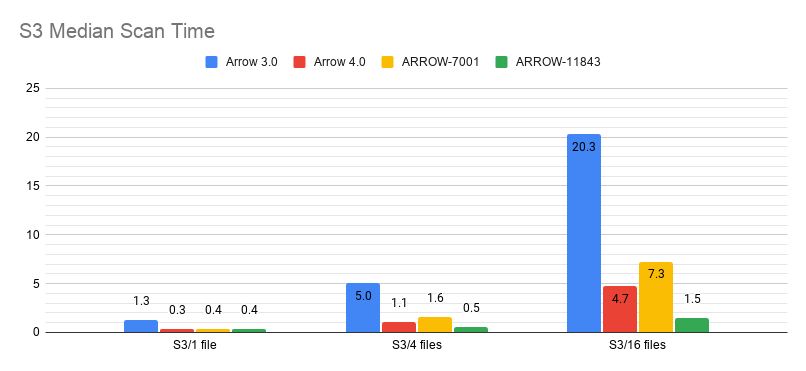
|
Properly implementing OpenAsync mostly fixes the discrepancy between prebuffer/no prebuffer on local files, so it seems most of the bottleneck there was just synchronously opening files.
|
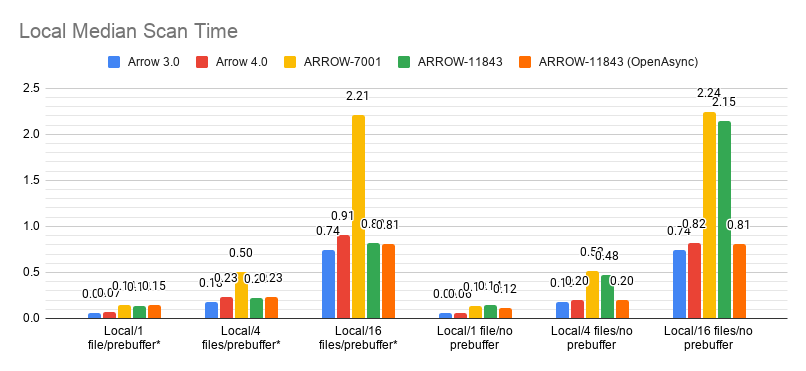
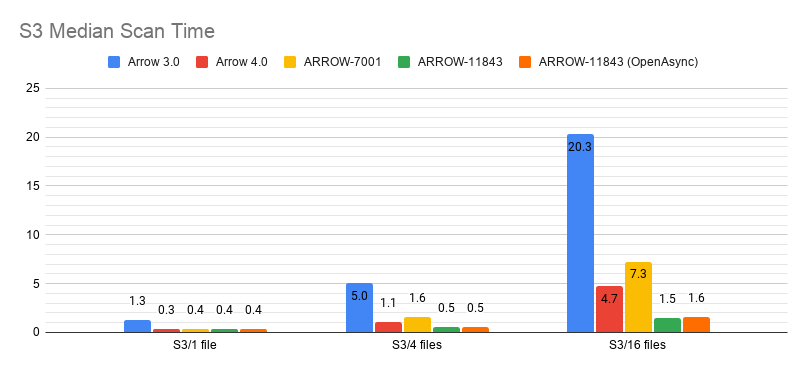
|
Ah, this exposes a deadlock in Python; now that we're using ReadAsync, if the underlying file is backed by Python, we'll deadlock over the GIL. Probably PyReadableFile needs to override ReadAsync. |
dd7a2ad to
c3e05ab
Compare
dccaf78 to
51fbc61
Compare
|
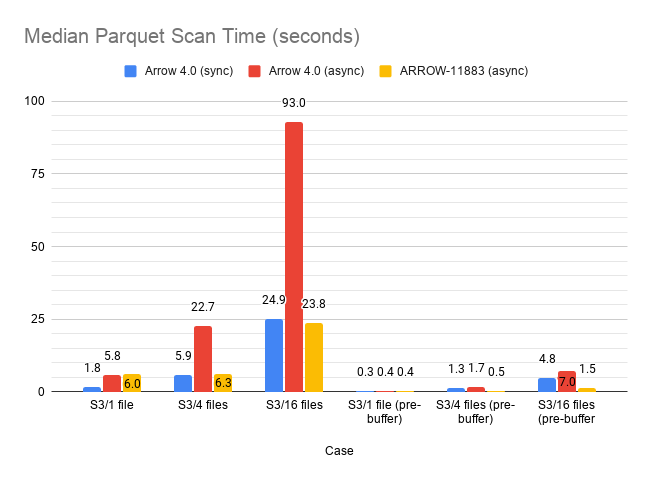
Apart from the non-pre-buffered single-file case, this brings us back on par with or improves upon the threaded scanner.
|
51fbc61 to
6ebbc7c
Compare
|
I'm also unable to replicate the failed Parquet encryption test on Windows. This PR already changes things to explicitly close the file handle, but I do feel like it's flakier than before. |
6ebbc7c to
d7732a3
Compare
westonpace
left a comment
There was a problem hiding this comment.
Just checking my understanding: This approach does all of the decryption and decoding on the I/O pool? I think that's fine since prebuffering is already creating a sort of dedicated I/O thread so we don't have to worry about decryption/decoding leaving the next read idle.
There was a problem hiding this comment.
I'm a little bit surprised this works at all honestly. Futures aren't really compatible with move-only types. I thought you would have gotten a compile error. This reminded me to create ARROW-12559. As long as this works I think you're ok. There is only one callback being added to reader_fut and you don't access the value that gets passed in as an arg here.
There was a problem hiding this comment.
In this case it works since Future internally heap-allocates its implementation, and yes, this is rather iffy, but works since this is the only callback. I'll add a TODO referencing ARROW-12259.
There was a problem hiding this comment.
I don't think we need to look at enable_parallel_column_conversion anymore since we're async?
There was a problem hiding this comment.
While benchmarking I noticed it got stuck due to this, so there's still nested parallelism coming in somewhere - I'll try to figure this out.
There was a problem hiding this comment.
Ah, actually, that makes sense. It would get stuck here: https://github.com/lidavidm/arrow/blob/parquet-reentrant/cpp/src/parquet/arrow/reader.cc#L959
ParallelFor does a blocking wait.
There was a problem hiding this comment.
We could add ParallelForAsync which returns a Future but that can be done in a follow-up.
There was a problem hiding this comment.
This could be a nice win for async in the HDD/SSD space (still recommending a follow-up PR).
There was a problem hiding this comment.
I fixed this and added a TODO for ARROW-12597.
cpp/src/arrow/io/caching.cc
Outdated
There was a problem hiding this comment.
/*lazy=*/false? I'm not really sure what the rules are for those inline names.
There was a problem hiding this comment.
Note I split this out into ARROW-12522/#10145 so I'll fix things there and rebase here.
cpp/src/arrow/io/caching.cc
Outdated
There was a problem hiding this comment.
&*it -> it unless I'm missing something
There was a problem hiding this comment.
This is turning the iterator type into an actual pointer.
There was a problem hiding this comment.
Ah, ok, a new trick for me to learn then :)
cpp/src/arrow/io/caching.cc
Outdated
There was a problem hiding this comment.
GetFuture is not a very clear name. I'm not sure what a better one would be. Maybe GetOrIssueRead?
cpp/src/parquet/arrow/reader.cc
Outdated
There was a problem hiding this comment.
I don't know the rules around PARQUET_CATCH_EXCEPTIONS but will it be a problem that ReadOneRowGroup runs (presumably) outside of this guard?
There was a problem hiding this comment.
It just expands to a try { } catch. However I'll audit these again…I dislike working in this module because we're mixing exceptions/Status and the OpenAsync work has just exacerbated that problem a lot.
There was a problem hiding this comment.
Yes, I haven't really had to think through those problems yet since exceptions are a bug everywhere else. It may be there are utilities we could add to the async code to help here. Feel free to create JIRAs and assign them to me if that is the case.
cpp/src/parquet/arrow/reader.cc
Outdated
There was a problem hiding this comment.
Naming nit: Maybe DecodeRowGroup?
cpp/src/parquet/arrow/reader.cc
Outdated
There was a problem hiding this comment.
I could be sold on using Item for brevity since it is constrained to this file but maybe Batches or Items instead of Item?
cpp/src/parquet/file_reader.cc
Outdated
There was a problem hiding this comment.
Does this function throw exceptions? It looks to me like that got changed when it changed to future.
There was a problem hiding this comment.
I'm going to try and rework what's here as mixing exceptions/Status/Future is painful + confusing.
cpp/src/parquet/file_reader.cc
Outdated
There was a problem hiding this comment.
Is this all to allow unique_ptr to work? If so, maybe add a todo comment reference ARROW-12559
 lidavidm
left a comment
lidavidm
left a comment
There was a problem hiding this comment.
Thanks for the review. Yes, the assumption is that parsing/decrypting the footer is cheap enough that it can be done inline. However now that you point it out, I don't think this is always the case (notably, I think Parquet is superlinear in the number of columns - or at least the implementation is - as there have been bug reports filed in the past from people with 1000-10000 columns) so I'll have to test that as well.
cpp/src/arrow/python/io.cc
Outdated
There was a problem hiding this comment.
The issue is when the main thread holds the GIL and calls back into libarrow, and then libarrow tries to call back into Python. This is OK if it's all on the same thread but not if it's on different threads. Really, this is an implementation error (any such bindings in pyarrow should release the GIL) but I remember it bit me somewhere during this PR.
cpp/src/parquet/arrow/reader.cc
Outdated
There was a problem hiding this comment.
It just expands to a try { } catch. However I'll audit these again…I dislike working in this module because we're mixing exceptions/Status and the OpenAsync work has just exacerbated that problem a lot.
cpp/src/parquet/file_reader.cc
Outdated
There was a problem hiding this comment.
I'm going to try and rework what's here as mixing exceptions/Status/Future is painful + confusing.
cpp/src/arrow/io/caching.cc
Outdated
There was a problem hiding this comment.
Note I split this out into ARROW-12522/#10145 so I'll fix things there and rebase here.
There was a problem hiding this comment.
In this case it works since Future internally heap-allocates its implementation, and yes, this is rather iffy, but works since this is the only callback. I'll add a TODO referencing ARROW-12259.
cpp/src/parquet/arrow/reader.cc
Outdated
There was a problem hiding this comment.
I'll change the API to have the user pass in the pointer. I'd rather have shared_from_this but I guess that won't work since it's typically used as a unique_ptr.
|
By the way, if it's easier, I can split the generator/OpenAsync/ScanBatchesAsync parts of this PR from each other. I think the OpenAsync part deserves some extra scrutiny in any case. |
d7732a3 to
7592eb7
Compare
|
This is now rebased on top of ARROW-12522 / #10145. I've reworked ParseMetadata so that the synchronous and asynchronous paths are truly synchronous/asynchronous, and to avoid mixing error handling methods (all parsing code uses exceptions, and the asynchronous path catches them and converts to Status). |
8ccda2b to
b8b605d
Compare
|
Sorry to bother you @emkornfield, but would you have time to review the changes here under src/parquet/reader.{cc,h}, since it refactors the footer parsing? Otherwise, I'll ask Antoine to take a look when he's back from leave. (I know there's a lot of other stuff in this PR, which Weston has looked through already.) |
1cd7e5b to
1c923ae
Compare
|
@pitrou would you have time to review the Parquet reader parts of this PR? Particularly where the footer reading code has been refactored. |
cpp/src/parquet/file_reader.cc
Outdated
There was a problem hiding this comment.
I don't understand this comment. Where is the workaround?
There was a problem hiding this comment.
The workaround is using AddCallback and marking a future complete manually instead of using Then.
cpp/src/parquet/file_reader.cc
Outdated
There was a problem hiding this comment.
This is not async, rename this function? For example ParseMetadataBuffer.
cpp/src/parquet/file_reader.cc
Outdated
There was a problem hiding this comment.
footer_buffer and footer_read_size don't seem used here?
cpp/src/parquet/arrow/reader.h
Outdated
There was a problem hiding this comment.
Should explain whether the executor is meant for IO or CPU work.
cpp/src/parquet/arrow/reader.cc
Outdated
cpp/src/parquet/arrow/reader.cc
Outdated
There was a problem hiding this comment.
Can you open a JIRA to reuse @westonpace 's work to always transfer the future? (we don't want CPU-heavy Parquet decoding to happen on an IO thread)
There was a problem hiding this comment.
So you always have to pass columns explicitly?
There was a problem hiding this comment.
Yes, I figured this is a lower-level API. We could add overloads to ease this.
There was a problem hiding this comment.
This doesn't seem to actually check the contents read from file. Could you do that?
There was a problem hiding this comment.
I've adjusted the test to check equality below.
|
Also, can you avoid using the misleading term "reentrant" here? I don't think there is any reentrant code path in this PR. |
7269cd7 to
6d1acfa
Compare
|
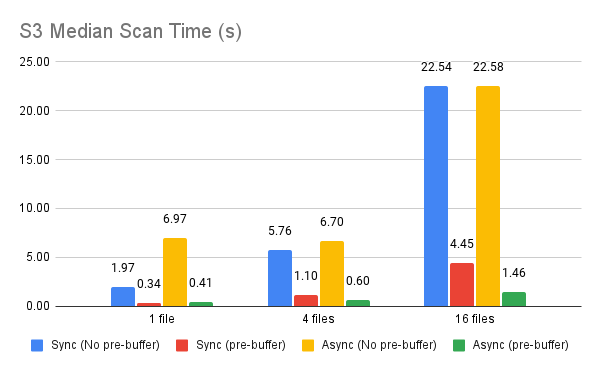
I re-tested S3 and also compared against the threaded reader with pre-buffering. I also corrected a logic error in file_parquet.cc that was leading to us needlessly spawning a thread. I also ran Conbench on the EC2 instance. It seems with that dataset, async doesn't make much of a difference. (Note that the bucket is in a different zone than my instance, though both are in the same region.) Threaded/pre-buffer: Async/pre-buffer: |
|
Rebased, will merge. Thank you! |
|
Travis-CI build at https://travis-ci.com/github/pitrou/arrow/builds/228224255 |
This provides an async Parquet reader where the unit of concurrency is a single row group.