[Feature] compaction quickly for small data import #9791 #9804
Conversation
|
Could you provide some test result for this feature? |
ok |
1.merge small versions of rowset as soon as possible to increase the import frequency of small version data 2.small version means that the number of rows is less than config::small_compaction_rowset_rows default 1000
1.merge small versions of rowset as soon as possible to increase the import frequency of small version data 2.small version means that the number of rows is less than config::small_compaction_rowset_rows default 1000
1.merge small versions of rowset as soon as possible to increase the import frequency of small version data 2.small version means that the number of rows is less than config::small_compaction_rowset_rows default 1000
1.merge small versions of rowset as soon as possible to increase the import frequency of small version data 2.small version means that the number of rows is less than config::small_compaction_rowset_rows default 1000
1.merge small versions of rowset as soon as possible to increase the import frequency of small version data 2.small version means that the number of rows is less than config::small_compaction_rowset_rows default 1000
1.merge small versions of rowset as soon as possible to increase the import frequency of small version data 2.small version means that the number of rows is less than config::small_compaction_max_rows default 10000
1.merge small versions of rowset as soon as possible to increase the import frequency of small version data 2.small version means that the number of rows is less than config::small_compaction_max_rows default 10000
1.merge small versions of rowset as soon as possible to increase the import frequency of small version data 2.small version means that the number of rows is less than config::small_compaction_max_rows default 10000
|
Can you provide some test data about how often this feature can be imported with and without it |
|
will there be any side effect for normal compaction performance, if there are many stream load and with not small data? |
maybe, because small compaction use the same lock with cc compaction, so small compaction may stop cc compaction for one tablet at this round , but small compaction finished very quickly usually less then 1s , cc compaction maybe excute next round |
so,it should be optional choice for user to use this optimization, may be better? |
1.merge small versions of rowset as soon as possible to increase the import frequency of small version data 2.small version means that the number of rows is less than config::small_compaction_max_rows default 10000
ok |
|
PR approved by at least one committer and no changes requested. |
|
PR approved by anyone and no changes requested. |
* compaction quickly for small data import #9791 1.merge small versions of rowset as soon as possible to increase the import frequency of small version data 2.small version means that the number of rows is less than config::small_compaction_rowset_rows default 1000
Proposed changes
Issue Number: close #9791
Problem Summary:
A table frequently imports a small amount of data. Doris generates a version for each imported data. If these versions are not merged in time, two problems will occur
For this reason, we hope to merge the imported versions faster. The simplest way is to increase the number of CC pool thread numbers . However, this may lead to too high io of the entire node, because the CC task may select rowsets with a large amount of data
So We hope to merge some rowsets as soon as possible without adding disk IO
Therefore, we choose rowset with small data rowset to merge first. The definition of small data rowset is that the imported rows are smaller than config:: quick compaction_ max_ rows
To achieve this goal
we add a new thread pool for small rowset compaction. This thread pool only selects rowsets with small data rowsets for merging. The time to trigger merging is as follows:
config parameter
Test
1.we create a table, try to see the quick compaction cost of different rows with centern rowsets
here is the result
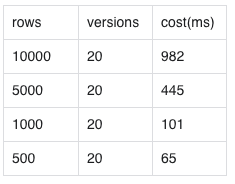
2. test import small data performance with high frequency
start 30 threads ,every thread import 100 batch, every batch included 500-1000 rows, the result:
we can concluded that
3.test one be import max qps with small data and compare with quick compaction
[without quick compaction]
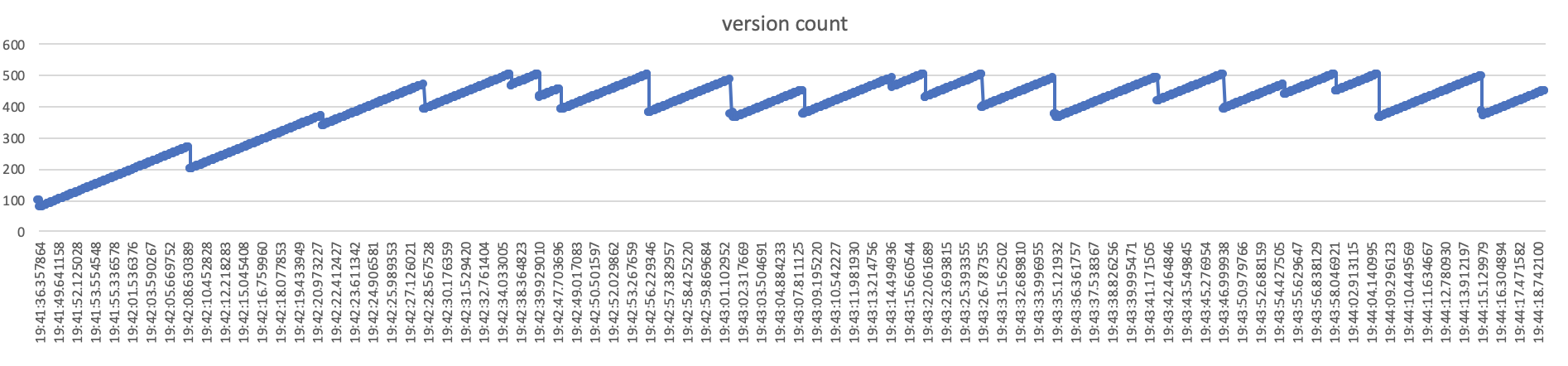
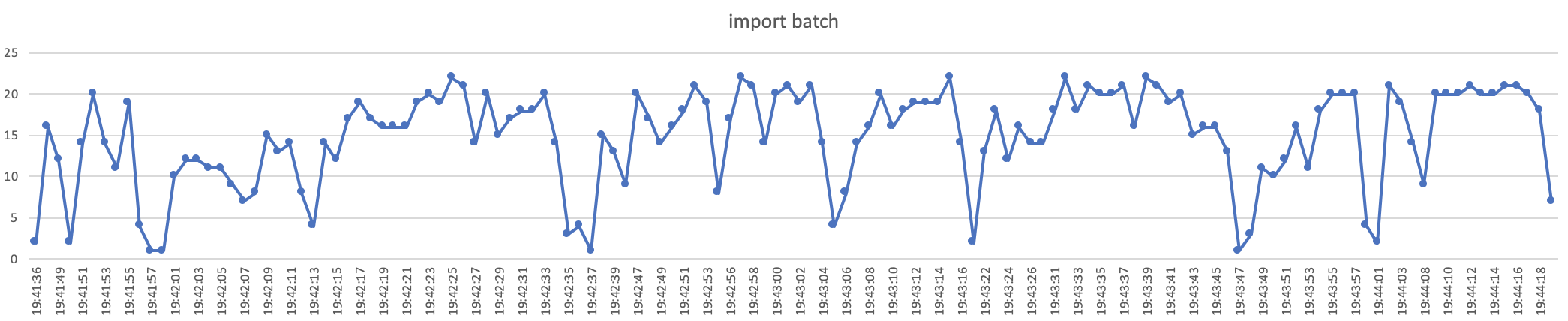
start 2 threads ,every thread import 100 batch, every batch included 500-1000 rows
we can concluded that
[with quick compaction]
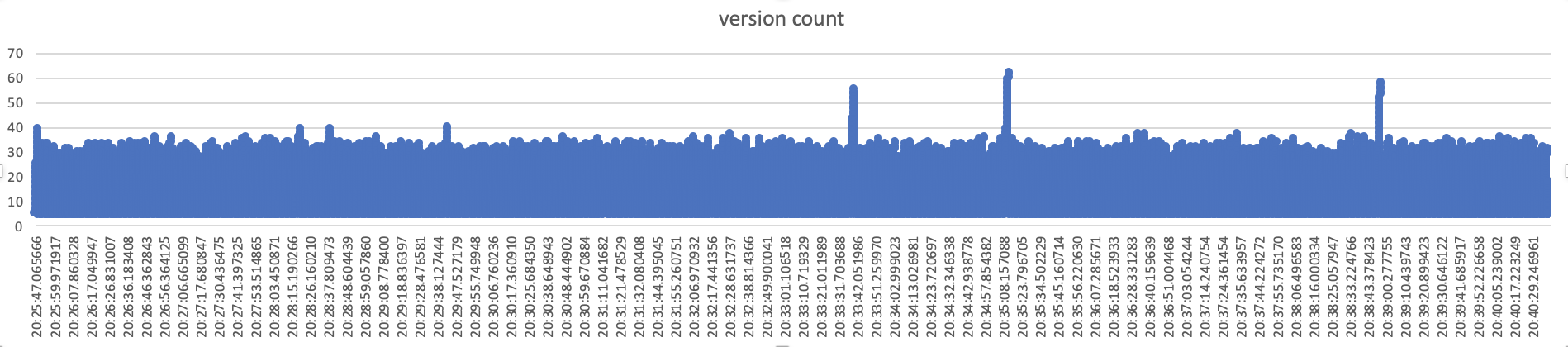
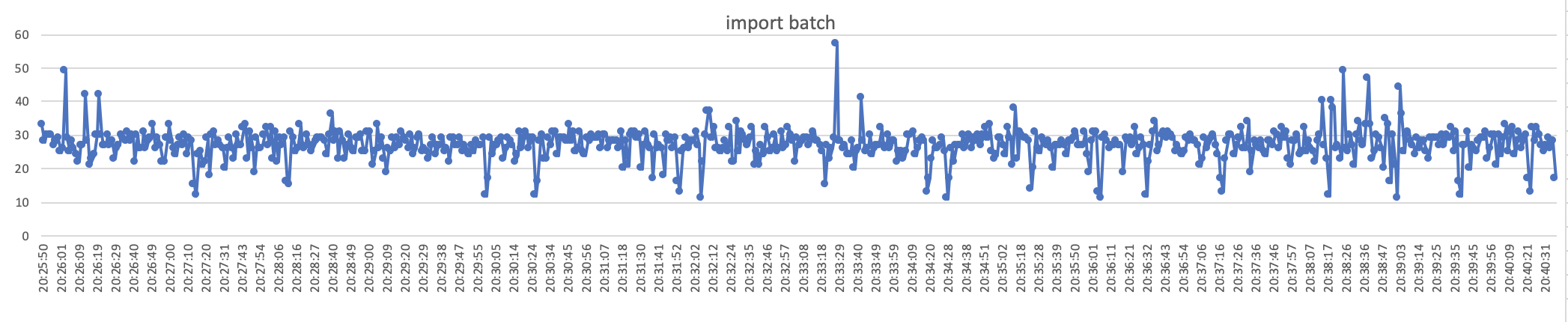
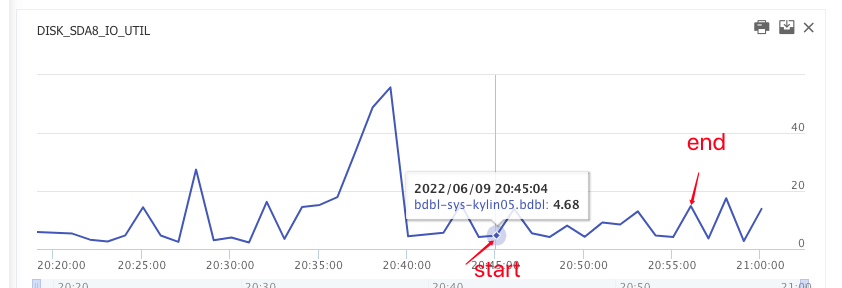
start 30 threads ,every thread import 1000 batch, every batch included 500-1000 rows
we can concluded that
conclusion
Checklist(Required)
Further comments
If this is a relatively large or complex change, kick off the discussion at dev@doris.apache.org by explaining why you chose the solution you did and what alternatives you considered, etc...