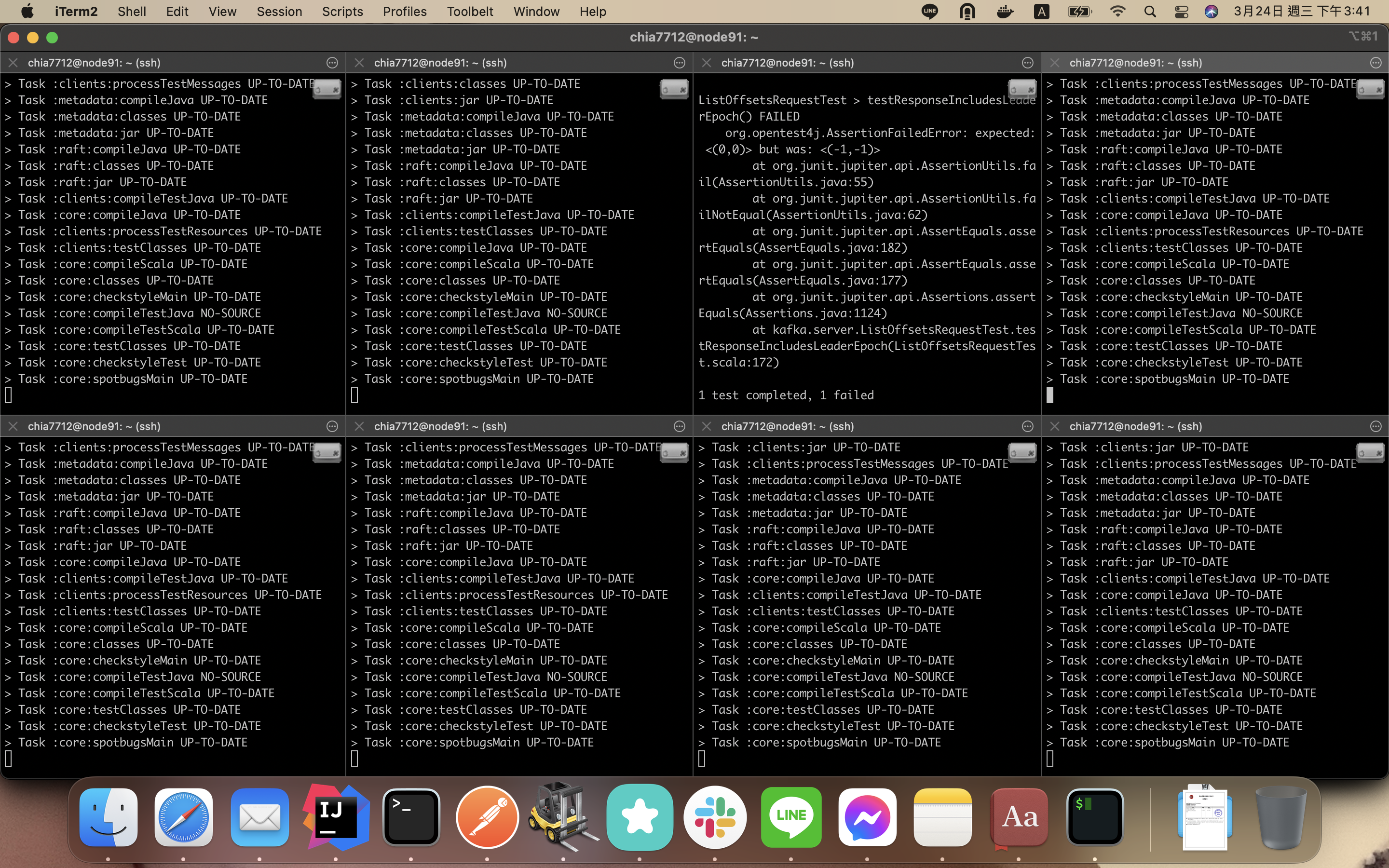
KAFKA-12384: stabilize ListOffsetsRequestTest#testResponseIncludesLeaderEpoch#10389
KAFKA-12384: stabilize ListOffsetsRequestTest#testResponseIncludesLeaderEpoch#10389chia7712 merged 8 commits intoapache:trunkfrom
Conversation
 dengziming
left a comment
dengziming
left a comment
There was a problem hiding this comment.
This is nice, should we trigger the jenkins build multiple times to verify that the flaky test is fixed.
|
@dengziming thanks for your review!
sure. I also loop |
|
@chia7712 Have you been able to reproduce the flaky test locally? I tried few times and I never could... |
yep. It requires a "slow" machine to make "slow" sync between leader and followers. I open 8 containers to loop that test on my local and it can reproduce the error effectively.
|
|
@chia7712 awesome! |
|
merge trunk to trigger QA again. |
|
unrelated failure. will merge trunk to trigger QA again. |
| val partitionToLeader = TestUtils.createTopic(zkClient, topic, numPartitions = 1, replicationFactor = 3, servers) | ||
| val topicConfig = new Properties | ||
| // make sure we won't lose data when force-removing leader | ||
| topicConfig.setProperty(TopicConfig.MIN_IN_SYNC_REPLICAS_CONFIG, "2") |
There was a problem hiding this comment.
Is this required? Even with min isr 1, we still require all in sync replicas to ack for acks=all. How many brokers do we have in the test?
There was a problem hiding this comment.
IIRC, acks=all means “all in-sync replicas” (rather than “all replicas”) have to receive record. In other words, produce request can be completed after one replica has received the record if mini ISR is one. When we shutdown the server with mini replica=1, the successful record may be NOT synced with other broker (there are 3 brokers totally). In short , the data could get lost after we shutdown current leader.
There was a problem hiding this comment.
Yeah, but if you have 3 brokers and you shutdown one of them, you should still have 2 brokers in the ISR. Are you saying that we are shrinking the ISR to 1 in this test? That would be unexpected.
There was a problem hiding this comment.
Are you saying that we are shrinking the ISR to 1 in this test? That would be unexpected.
No, I did not observe such accident. Maybe I misunderstood the log before and my assumption is not happen (loop it 1000 times). will revert this change.
|
@ijuma any suggestions? This test is still flaky :( |
 showuon
left a comment
showuon
left a comment
There was a problem hiding this comment.
@chia7712 , thanks for the fix. LGTM. Please also update the status in KAFKA-12384. Thank you.
oh, sorry that I did not notice the existent ticket. will update the jira :) |
|
unrelated error. merge trunk to trigger QA again |
|
@chia7712 Is the test still flaky with the latest changes? |
yep. I loop this patch 100 times and all pass |
* apache-github/trunk: KAFKA-10769 Remove JoinGroupRequest#containsValidPattern as it is dup… (apache#9851) KAFKA-12384: stabilize ListOffsetsRequestTest#testResponseIncludesLeaderEpoch (apache#10389) KAFKA-5146: remove Connect dependency from Streams module (apache#10131)
issue: https://issues.apache.org/jira/browse/KAFKA-12384
The root cause is that we don't wait new leader to sync hw with follower so sending request to get offset could encounter
OFFSET_NOT_AVAILABLEerror.Committer Checklist (excluded from commit message)