Conversation
|
CIs don't complain here. I am surprised. @mathurinm can you report if this branch https://github.com/CEA-COSMIC/ModOpt/tree/develop fixes the issue? |
|
cc @sfarrens |
|
This issue should have been fixed in CEA-COSMIC/ModOpt#189. |
|
The solvers themselves work now, but they break benchopt since they make arrays non writeable, and sklearn and celer's cython code does not like it: |
|
Maybe it's worthy to get someone from modopt to help here, because their solvers seem not bad at all: |
 agramfort
left a comment
agramfort
left a comment
There was a problem hiding this comment.
otherwise at the end of the run of modopt do:
X.flags.writeable = true
y.flags.writeable = true
to revert what modopt does internally
Co-authored-by: Alexandre Gramfort <alexandre.gramfort@m4x.org>
Co-authored-by: Alexandre Gramfort <alexandre.gramfort@m4x.org>
|
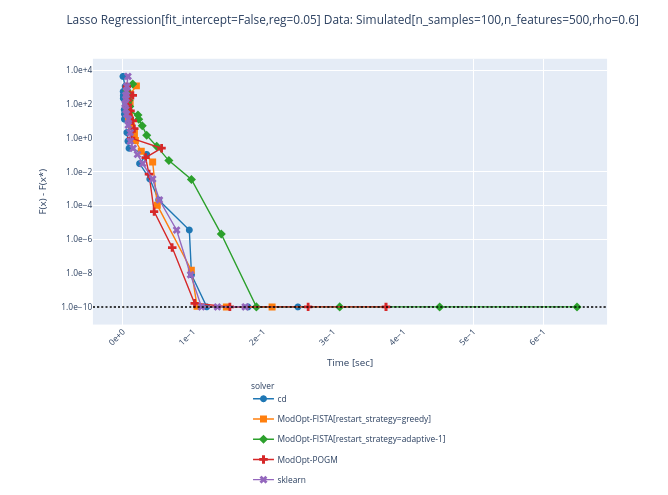
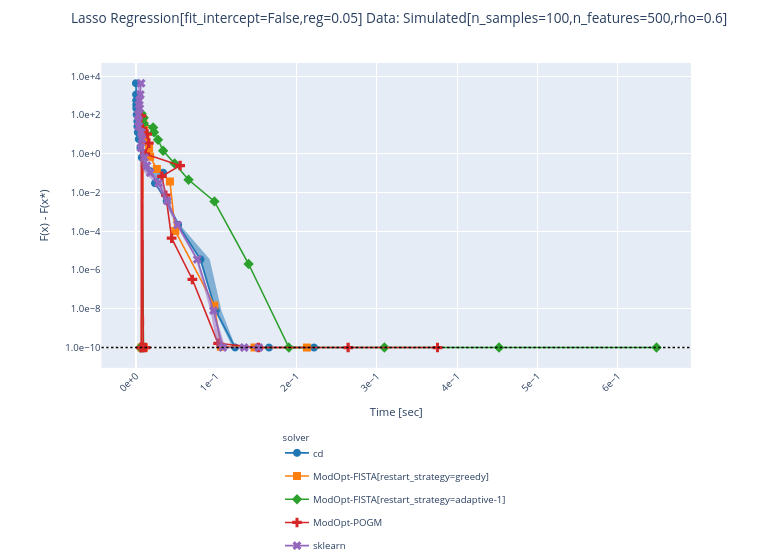
OK for 1 rep: probably a warm restart issue |
|
Indeed, there is no |
|
thanks for the pointer @tomMoral, resetting For FISTA, I don't know, even for 1 run I get a divergence for lambda_max /2: |
|
@tbng can you take over this PR ? It seems the divergence is caused by |
Sure, no problem -- just to be sure: does this mean fix this param and rerun the whole benchmark? |
|
Yes, just to fix the param and check that the modopt solvers behave nicely, for example running them along with |
|
The benchmark when setting
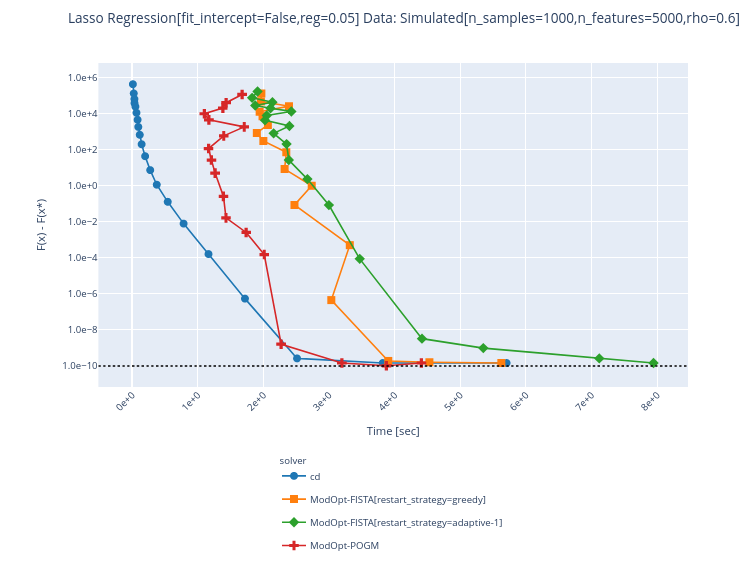
ping @zaccharieramzi I guess? Edit: actually in this case the red curve converge (although slow) until the very last time stepwhich is also confusing |
|
I managed to avoid the divergence in Fista restart-adaptive by increasing the value of initial beta_param (or \gamma in Algorithm 4 of the citation). However, it is quite slow to converge running benchmark with 5 repetitions. @zaccharieramzi do you think this is consistent with what you've observed for ModOpt-Fista-Adaptive-1 (red line?) |
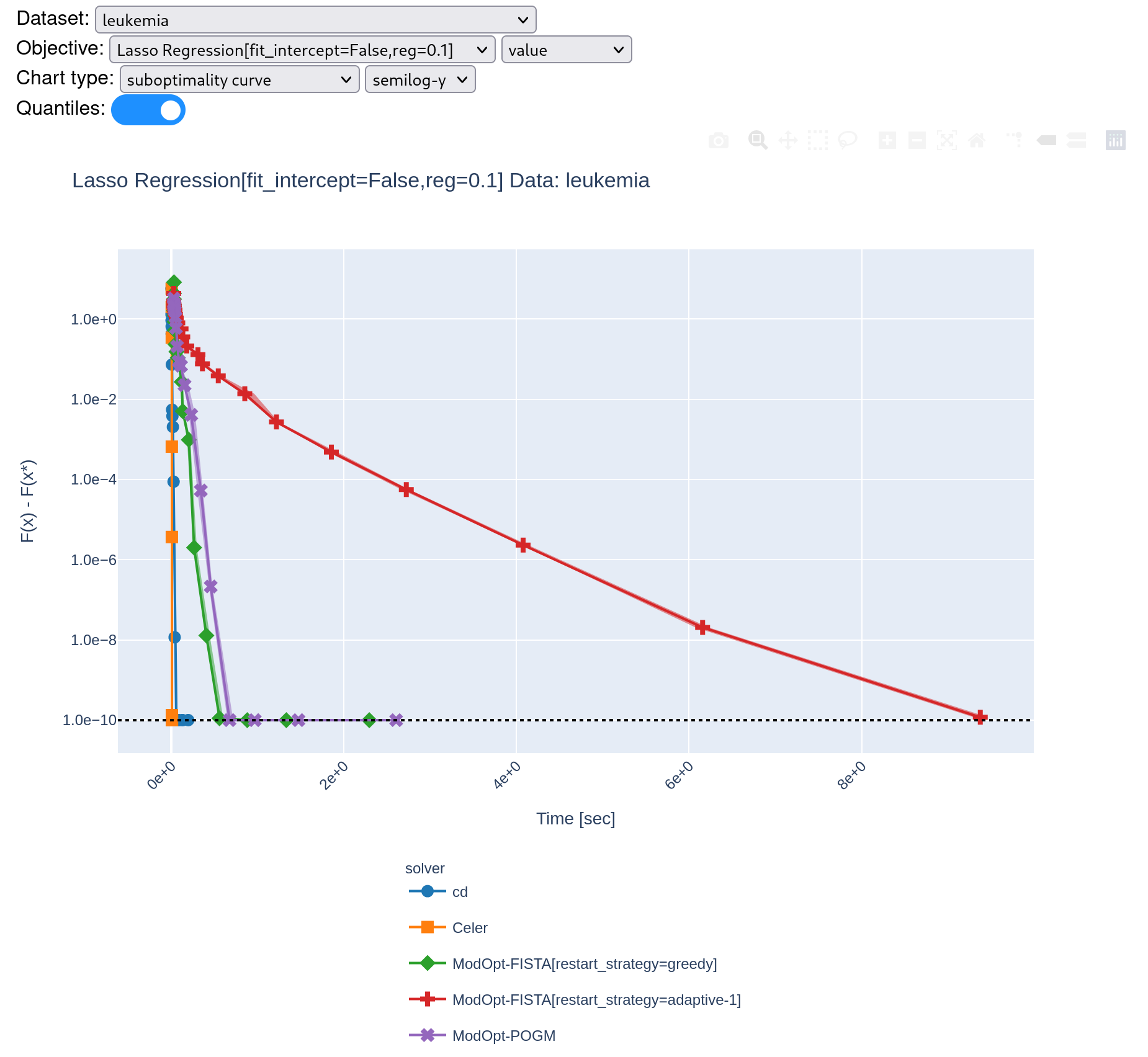
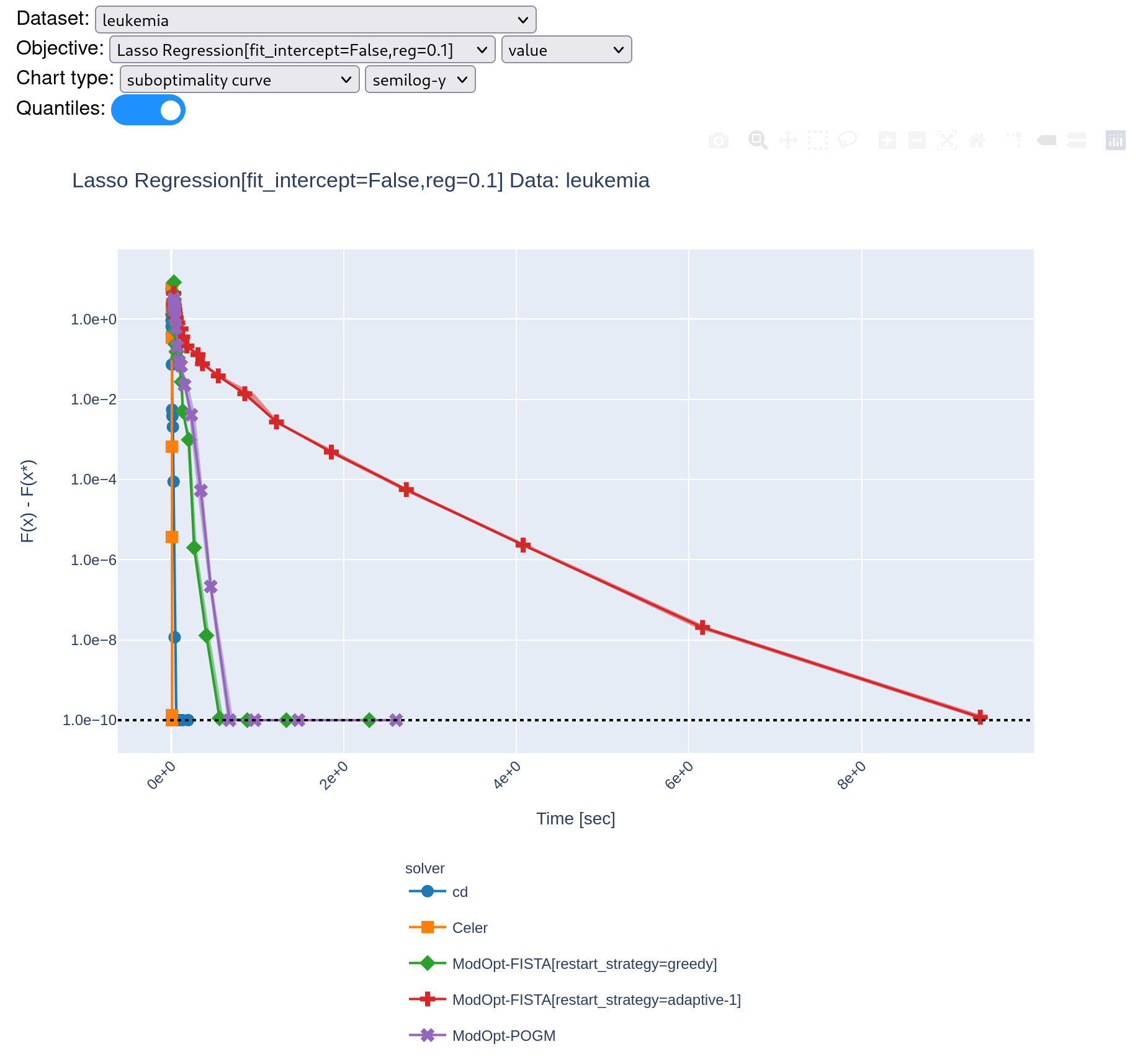
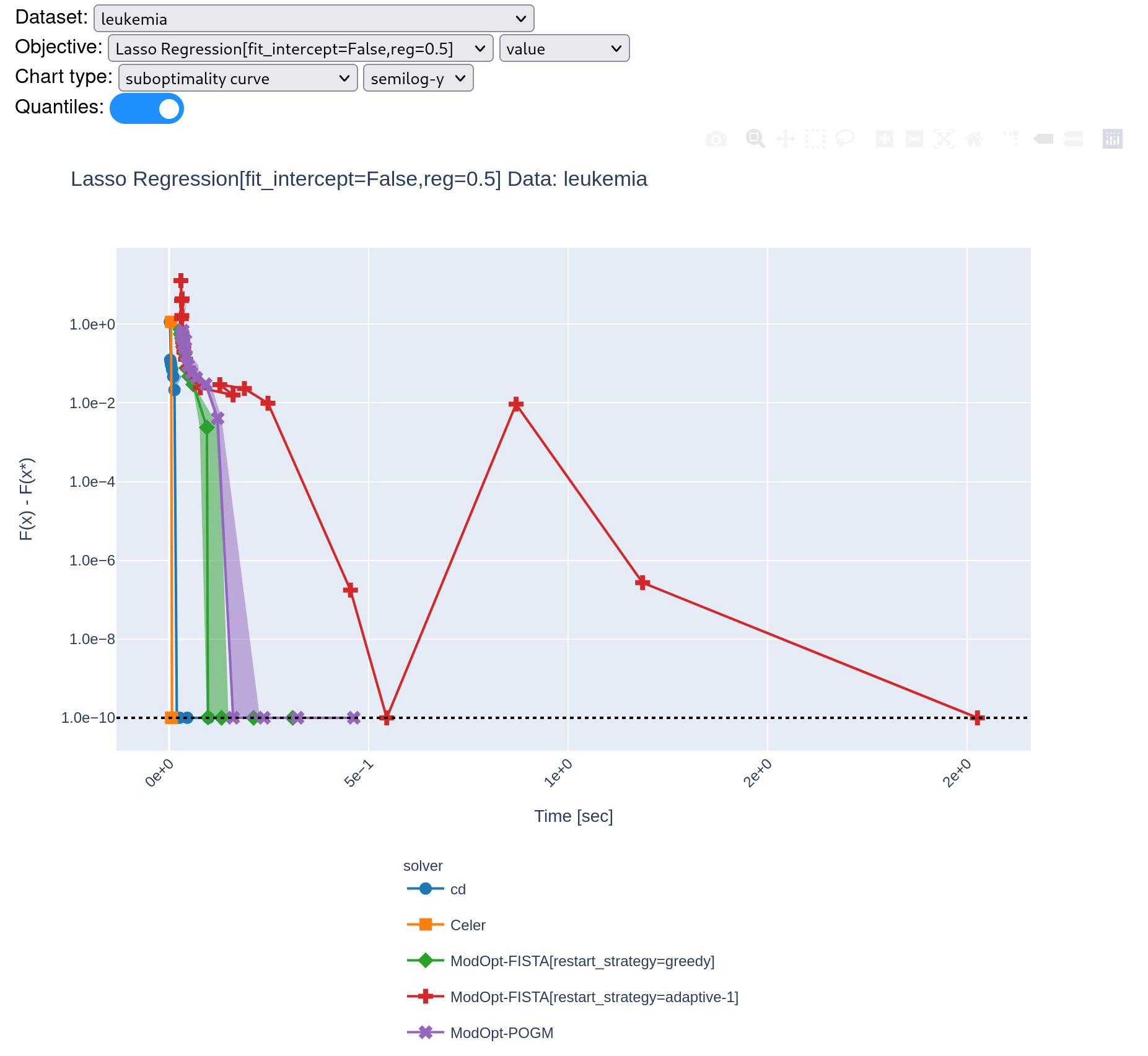
|
Hi @tbng , Indeed according to this: https://hal.inria.fr/hal-02298569/document, FISTA with adaptive restart is rather slow compared to the best performers. |
|
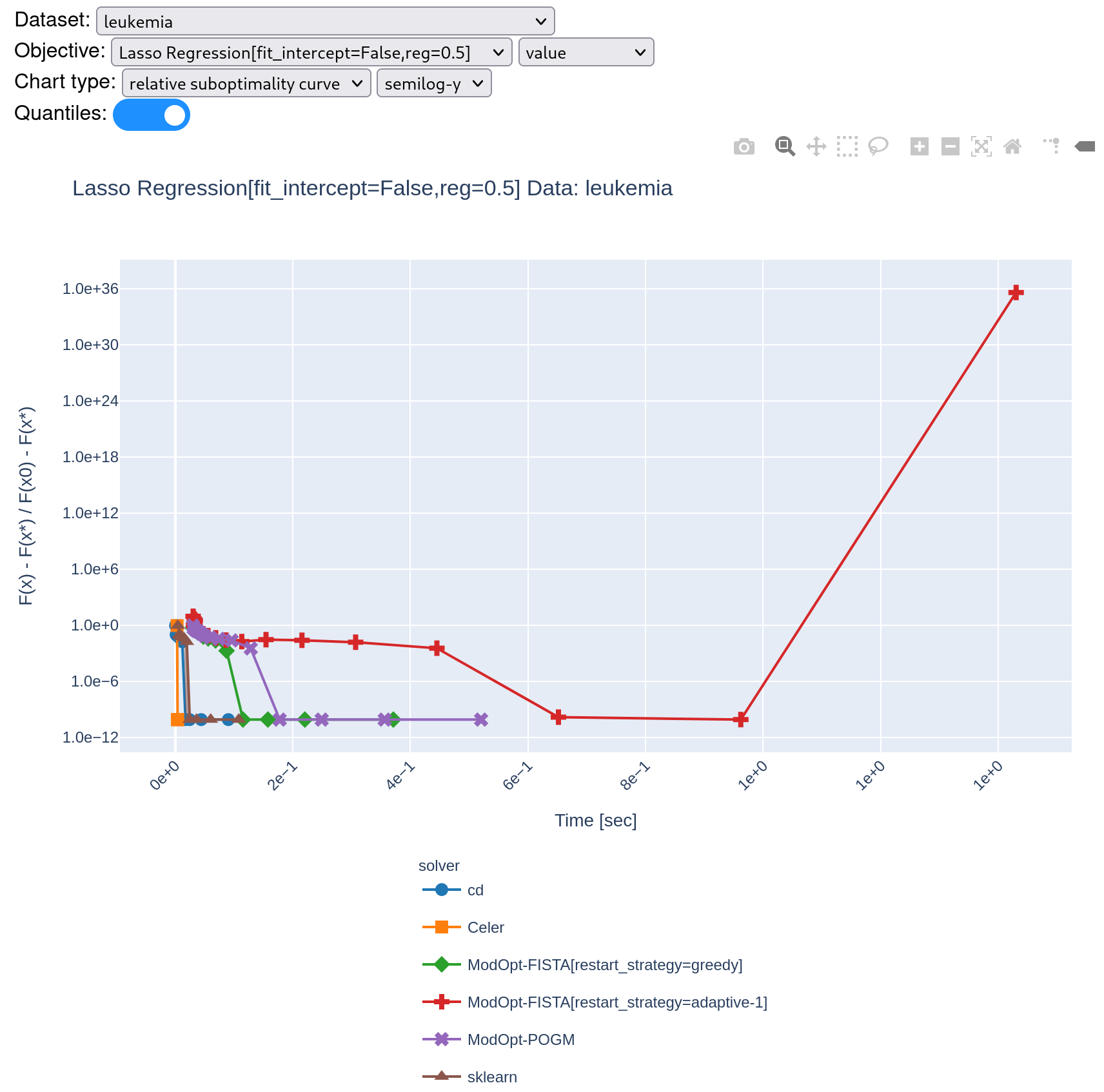
Hi @tbng did you push all of your changes or did I miss something? I still get divergence:
Even when it converges, it looks like something is wrong given the time it takes: Greedy also diverges on other data... : |
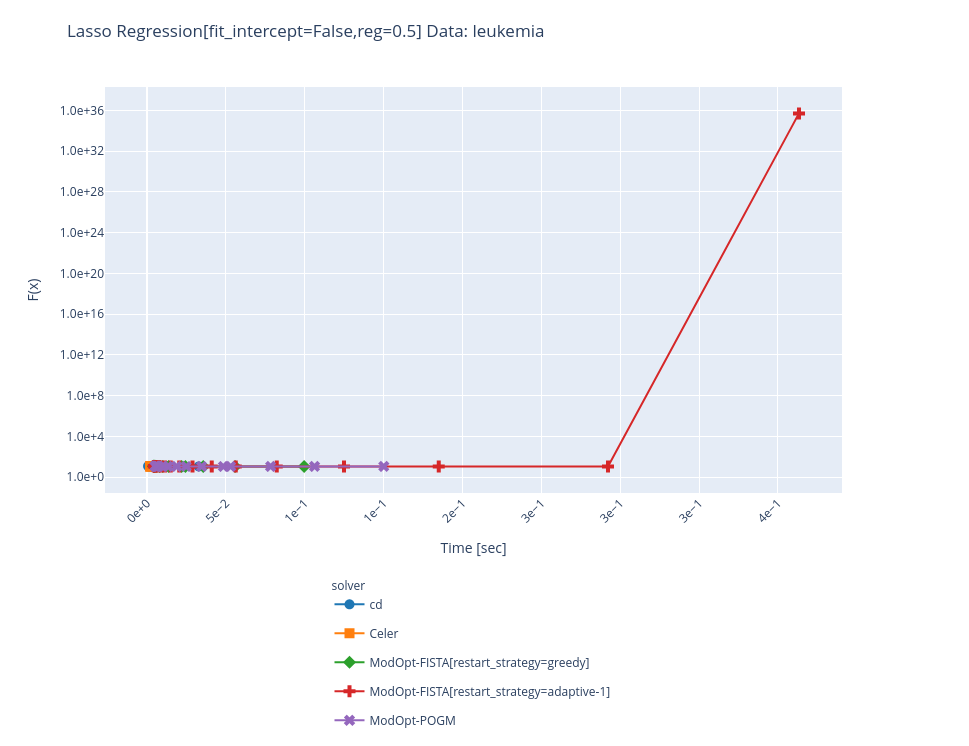
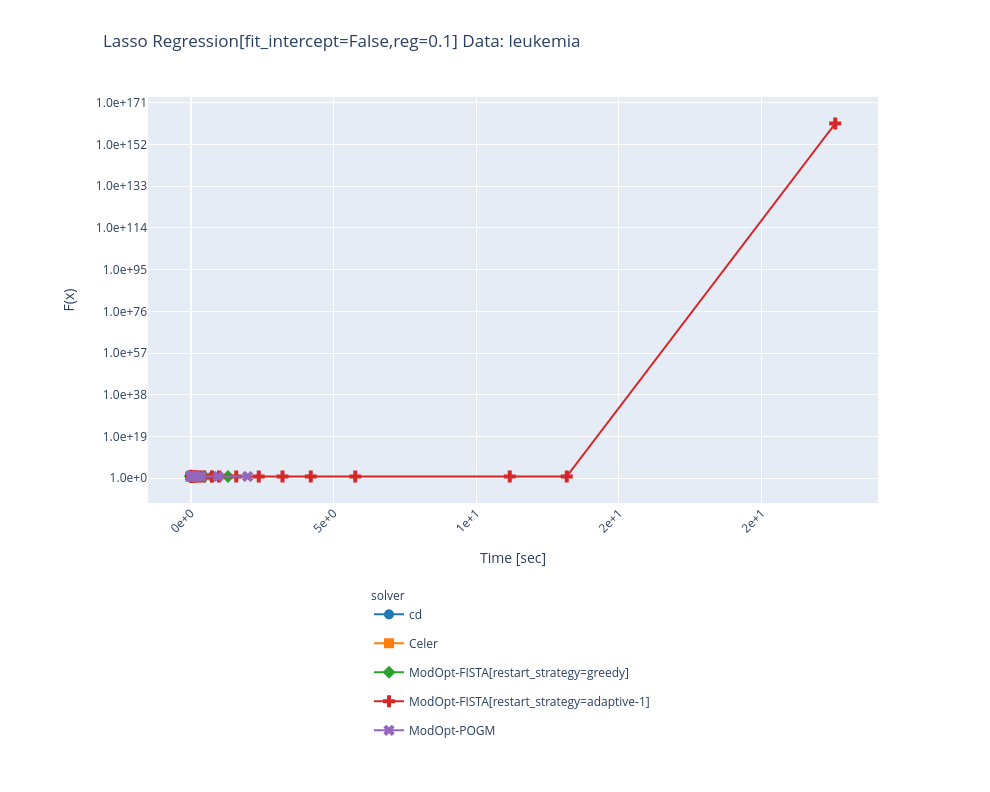
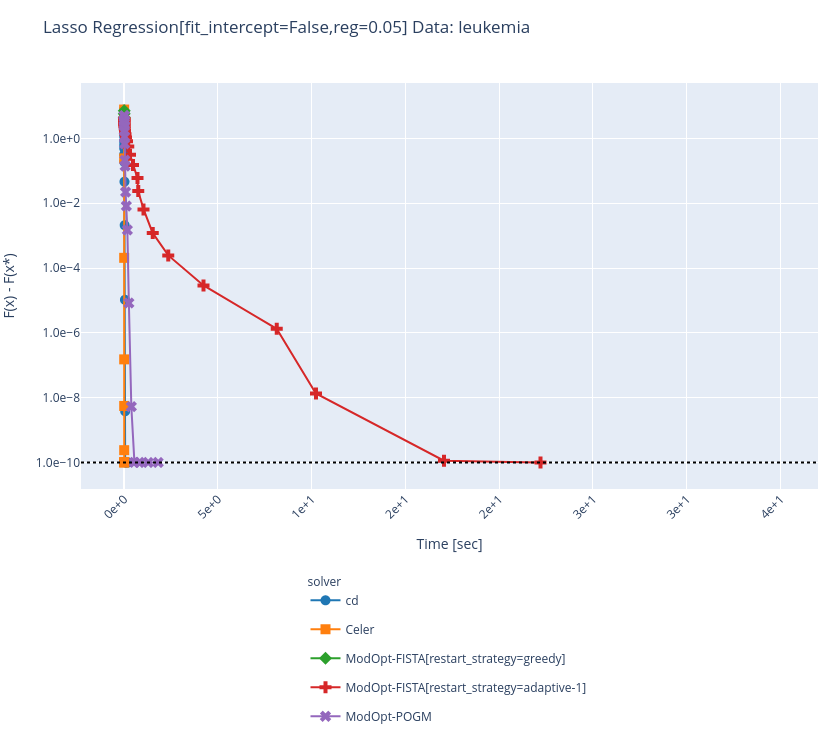
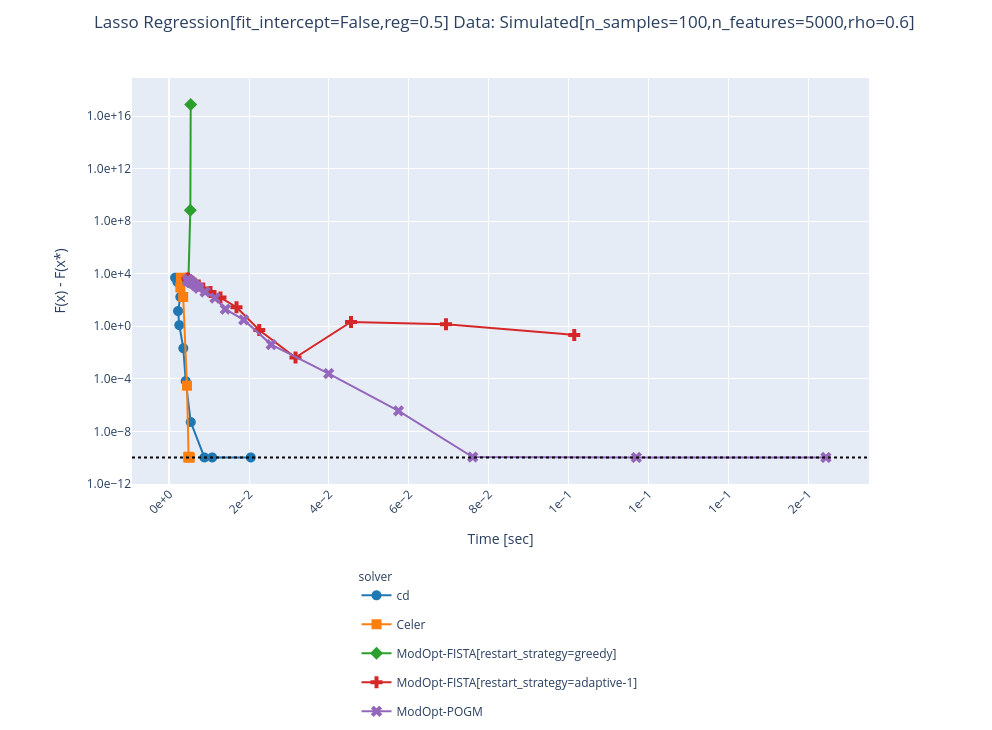
Sorry I could not push to this PR ! But what I did is just change the parameter But from some exchange I think @mathurinm has arrived at much better results + filing issues : CEA-COSMIC/ModOpt#221 |
|
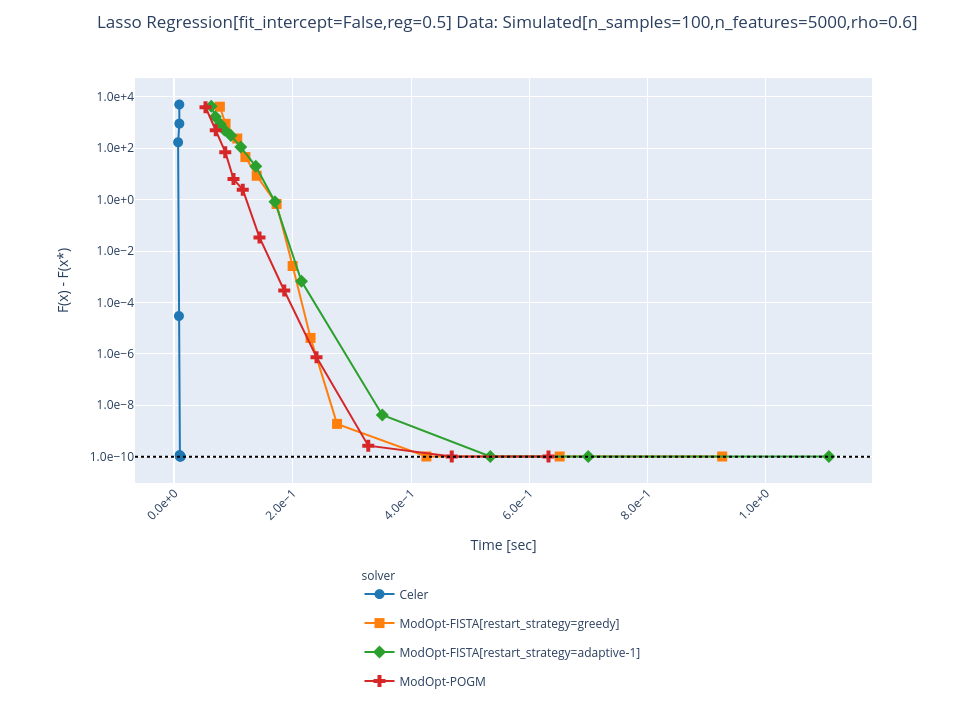
@agramfort a few curves:
|
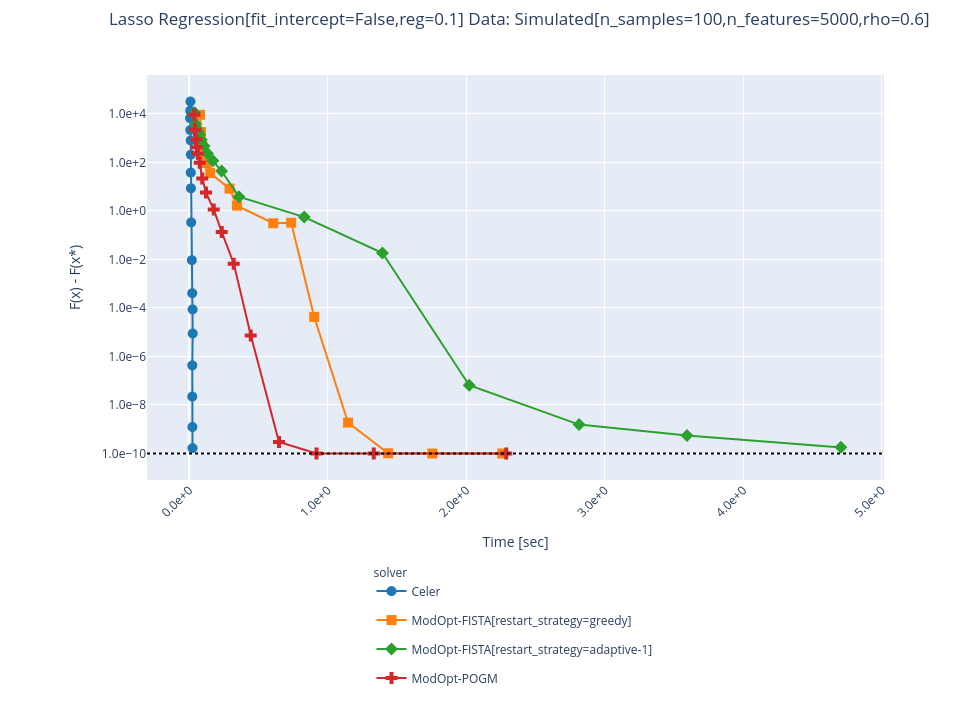
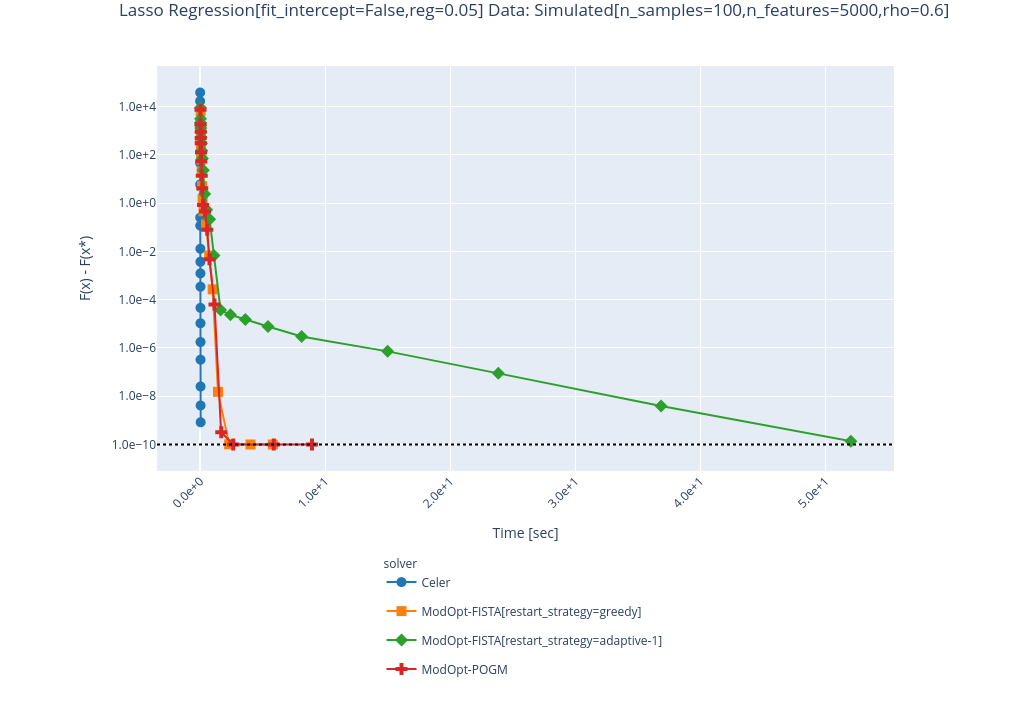
solvers/modopt_fista.py
Outdated
| else: | ||
| def op(w): | ||
| return self.X @ w | ||
| # TODO implement correct gradient if fit_intercept |
There was a problem hiding this comment.
Isn't the correcct gradient has been defined for the fit_intercept case from line 66-68?
There was a problem hiding this comment.
@tbng that's the "prediction"/forward step (X @ w). I have implemented the gradient (trans_op) too now.
|
I have added support for fit_intercept: |
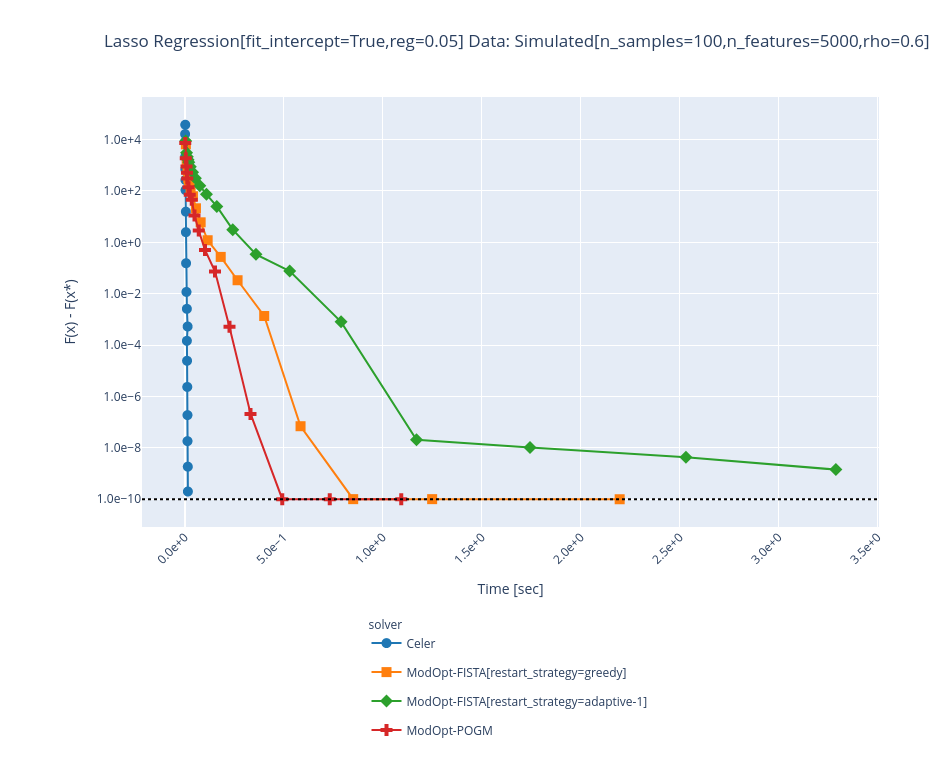
|
thx @mathurinm |
once #44 is merged, this will allow to readd the modopt solvers as they were before removal.