CSSM231 experiments
In this brainteaser, a salesman has to travel to, say, eight cities scattered all over a map. He must visit each city once, but once he leaves a city he cannot visit it again, even just to pass through on his way somewhere else. Unfortunately, the cities have convoluted roads between them, so it’s not obvious in what order to visit.)
Sam Kean, from The Violinist's Thumb
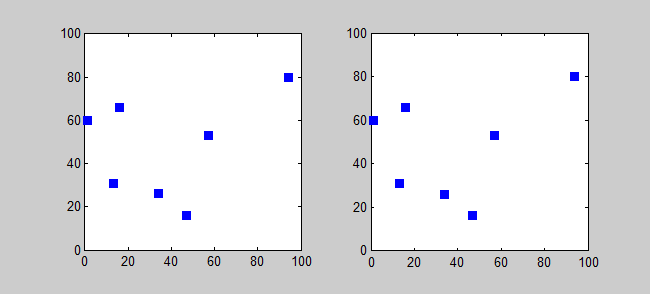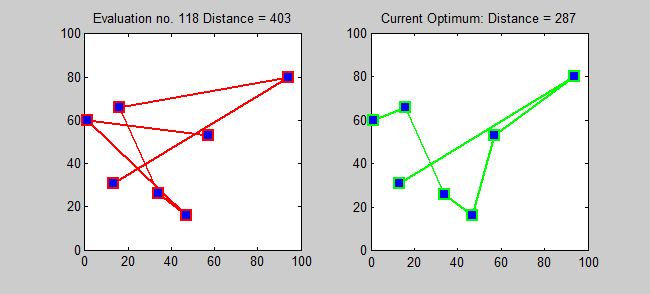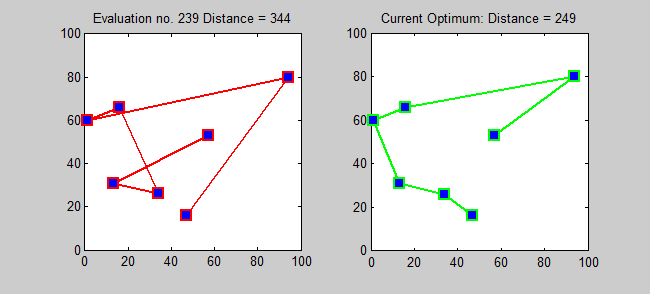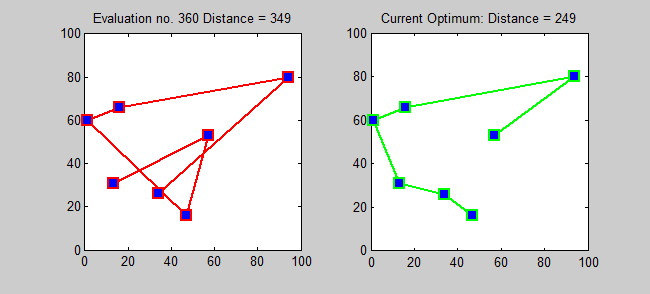
- How would you solve this problem using a computer?
- is there an algorithm to solve this problem? (brute force!)
- How does a binary computer architecture make this harder?
- Can you imagine a parallel approach?
- Where could we find a parallel computer? (DNA!)
A computer running processes in parallel could solve this problem more efficiently than a serialized von Neumann architecture. DNA solves problems in parallel. Let's demonstrate that DNA will solve the problem more efficiently than an everyday computer.
- how do we measure efficiency?
- are they well matched?
- how do we calculate the power of the two computers?
- dense storage (bases spaced every 0.35 nanometer, 3.5 Angstroms)
- enormously parallel
- energy efficient
To see how DNA could possibly solve this problem, consider a hypothetical example. First thing, you’d make two sets of DNA snippets. All are single-stranded. The first set consists of the eight cities to visit, and these snippets can be random A-C-G-T strings: Sioux Falls might be AGCTACAT, Kalamazoo TCGACAAT. For the second set, use the map. Every road between two cities gets a DNA snippet. However—here’s the key—instead of making these snippets random, you do something clever. Say Highway 1 starts in Sioux Falls and ends in Kalamazoo. If you make the first half of the highway’s snippet the A/T and C/G complement of half of Sioux Falls’s letters, and make the second half of the highway’s snippet the A/T and C/G complement of half of Kalamazoo’s letters, then Highway 1’s snippet can physically link the two cities:

After encoding every other road and city in a similar way, the calculation begins. You mix a pinch of all these DNA snippets in a test tube, and presto change-o, one good shake computes the answer: somewhere in the vial will be a longer string of (now) double-stranded DNA, with the eight cities along one strand, in the order the salesman should visit, and all the connecting roads on the complementary strand.
Of course, that answer will be written in the biological equivalent of machine code (GCGAGACGTACGAATCC…) and will need deciphering. And while the test tube contains many copies of the correct answer, free-floating DNA is unruly, and the tube also contains trillions of wrong solutions—solutions that skipped cities or looped back and forth endlessly between two cities. Moreover, isolating the answer requires a tedious week of purifying the right DNA string in the lab. So, yeah, DNA computing isn’t ready for Jeopardy. Still, you can understand the buzz. One gram of DNA can store the equivalent of a trillion CDs, which makes our laptops look like the gymnasium-sized behemoths of yesteryear. Plus, these “DNA transistors” can work on multiple calculations simultaneously much more easily than silicon circuits. Perhaps best of all, DNA transistors can assemble and copy themselves at little cost.
By placing a few grams of every DNA city and street in a test tube and allowing the natural bonding tendencies of the DNA building blocks to occur, the DNA bonding created over 10,000,000,000
Keep the paths that exhibit the following properties:
- The path must start at city A and end at city G.
- Of those paths, the correct paths must pass through all 7 cities at least once.
- The final path must contain each city in turn.
- generate random paths in the graph
- remove all the paths that do not start in the vertex Vin and do not end in the vertex Vout.
- remove all the paths that do not involve exactly n vertices.
- for each of the n vertices v, remove all the paths that do not involve vertex v.
- incorrect assumption that the procedure is error-free
- DNA solution is entirely structural
Larry Gonick cartoon

