compute_approx_kl for NaiveExperienceMaker maybe incorrect.
As motion in Approximating KL Divergence
$$ KL[q,p] = \mathbb{E}_{x\sim q}[\log\frac{q(x)}{p(x)}] $$
let
$$ r = \frac{p(x)}{q(x)} $$
note that, x is sample from distribution q.
Then
$$ KL_{approx}[q,p] = \mathbb{E}_{x\sim q}[-\log(r) + (r-1) ] $$
In paper Training language models to follow instructions with human feedback, object for actor , (e.i. reward of experience , ignore loss_ptx)
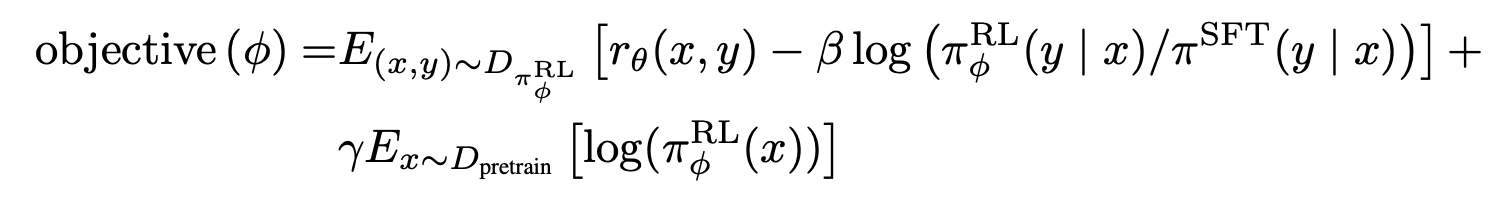
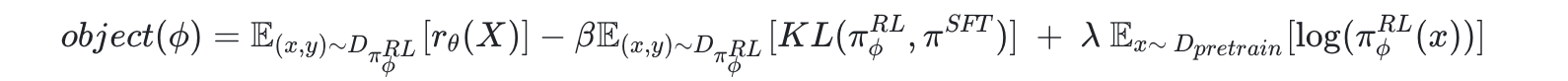
So for computing KL, samples are sampled from actor model e.i $\pi^{RL}_\phi$, instead of $\pi^{SFT}$
KL in the object should be $KL[\pi^{RL}, \pi^{SFT}] =KL[q,p]$ , and $r$ of KL_approx should be $\frac{\pi^{SFT}(x)}{\pi^{RL}_\phi(x)}$
While on the coati.models.utils.compute_approx_kl
log_ratio = log_probs - log_probs_base
and log_probs and log_probs_base correspond to actor_model and sft_model respectively.
This should be modify to
log_ratio = log_probs_base - log_probs
compute_approx_kl for
NaiveExperienceMakermaybe incorrect.As motion in Approximating KL Divergence
let
note that, x is sample from distribution q.
Then
In paper Training language models to follow instructions with human feedback, object for actor , (e.i. reward of experience , ignore loss_ptx)
So for computing KL, samples are sampled from actor model e.i$\pi^{RL}_\phi$ , instead of $\pi^{SFT}$
KL in the object should be$KL[\pi^{RL}, \pi^{SFT}] =KL[q,p]$ , and $r$ of KL_approx should be $\frac{\pi^{SFT}(x)}{\pi^{RL}_\phi(x)}$
While on the
coati.models.utils.compute_approx_kland log_probs and log_probs_base correspond to actor_model and sft_model respectively.
This should be modify to