Conversation
 wu-sheng
left a comment
wu-sheng
left a comment
There was a problem hiding this comment.
I suggest move this to optional plugin and add a document for this. Because this plugin should only work when agent installed in ElasticSearch server side, right?
|
The situation on the server side is more complicated than SolrJ. It will put the trace id into Solr MDC. Then Solr logs it in SLOW logger or where you want to by Log4j configuration file.
|

|
@wu-sheng yes, it works in Solr Server, likes ElasticSearch server-side. |
| * [transport-client](https://github.com/elastic/elasticsearch/tree/master/client/transport) 5.2.x-5.6.x | ||
| * [SolrJ](https://lucene.apache.org/solr) 7.0.0-7.7.1 | ||
| * [Solr](https://github.com/apache/lucene-solr) 7.0.0-7.7.1 | ||
| * [SolrJ](https://github.com/apache/lucene-solr/tree/master/solr/solrj) 7.0.0-7.7.1 |
There was a problem hiding this comment.
Add Solr Server and versions as a subtype here.
| * [Elasticsearch](https://github.com/elastic/elasticsearch) | ||
| * [transport-client](https://github.com/elastic/elasticsearch/tree/master/client/transport) 5.2.x-5.6.x | ||
| * [SolrJ](https://lucene.apache.org/solr) 7.0.0-7.7.1 | ||
| * [Solr](https://github.com/apache/lucene-solr) 7.0.0-7.7.1 |
|
Could you explain more about how many spans created for each request? And what are they? |
|
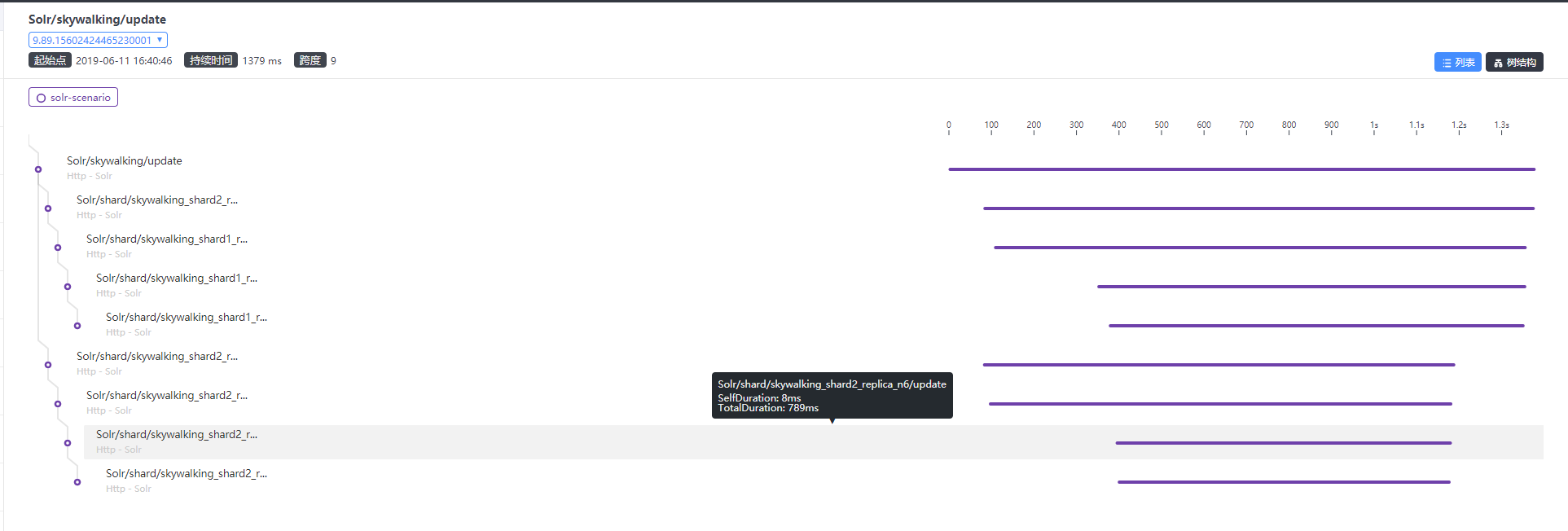
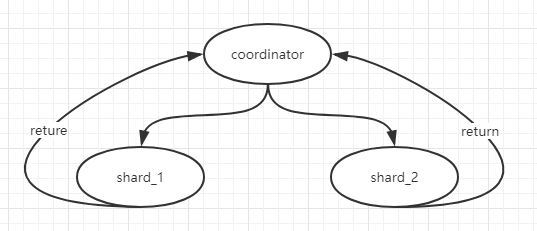
Here is a screenshot of solr collection. Obviously, it consists of 2 shards with 2 replicas per shard.
In query, we omit the replicas. One shard become a coordinator, when it receives a query from user. Because it is has a part of data in collection, It launch a request and send to others shards. Then coordinator have to merge the result that comes from all shards. In real scenario, it has serveral stages in usually.
In update, the documents need to be routed and send to corresponding shard. Then shard will copy it to they replicas. |

|
Solr is a distributed database. |
|
@kezhenxu94, Do you have anything else for the explaination? |
|
OK. I think it is clear enough for the Solr server. Then let's talk about how this goes in topology and trace.
I think the decision is based on the answers of the above questions. |
|
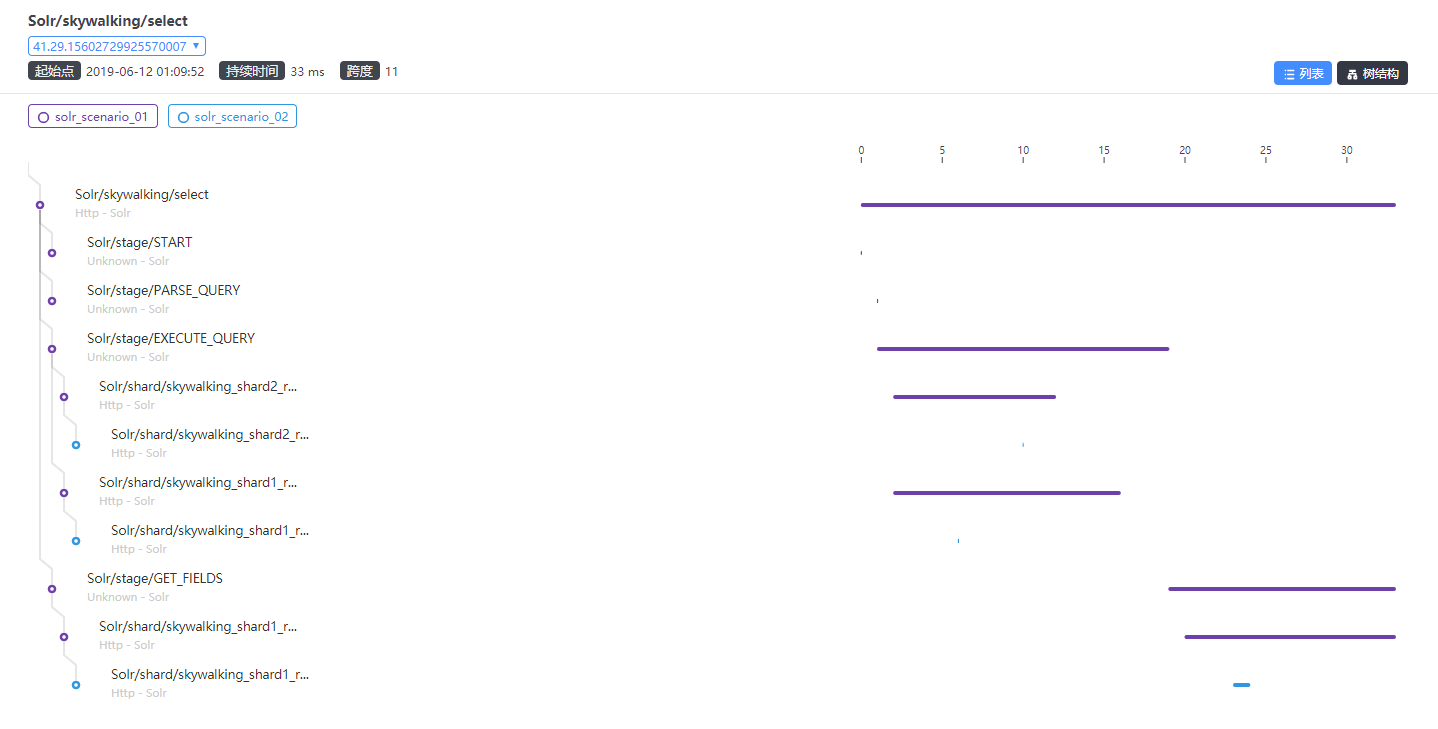
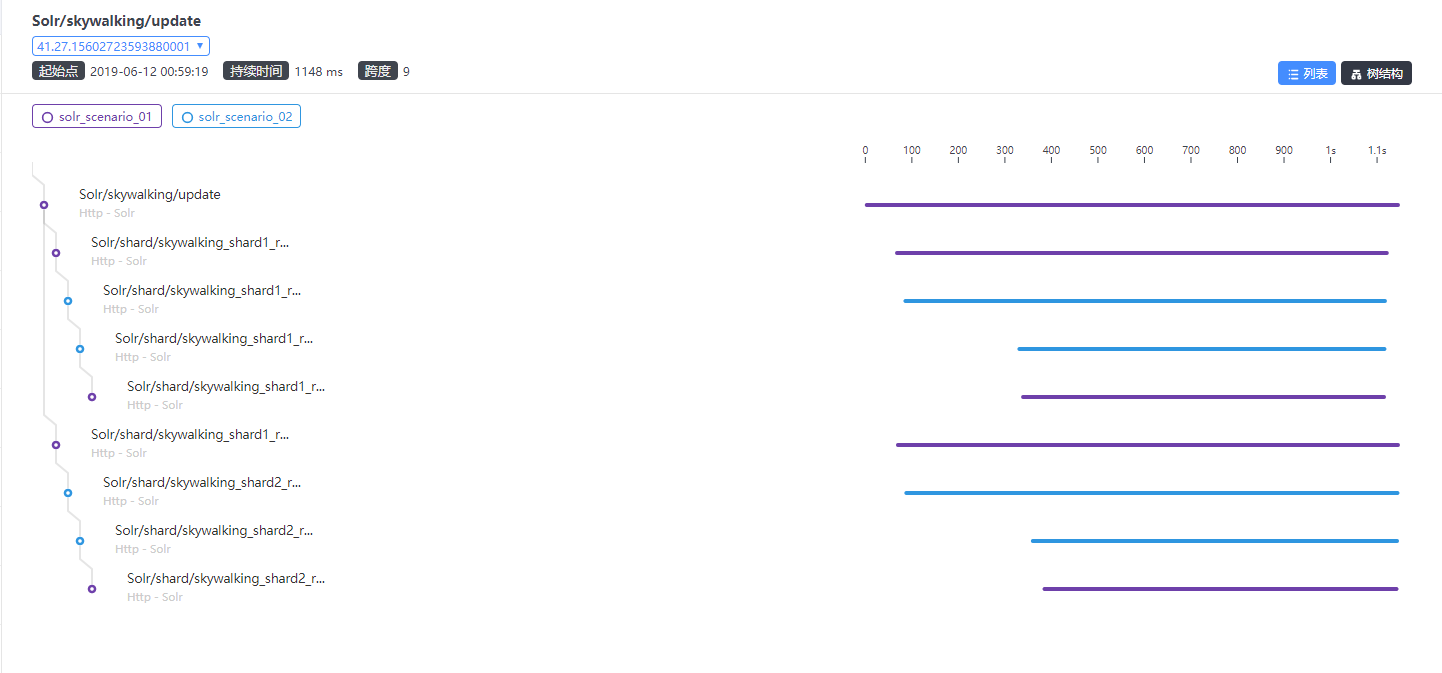
@wu-sheng , Sorry, I have a mistake that I configured the
|
|
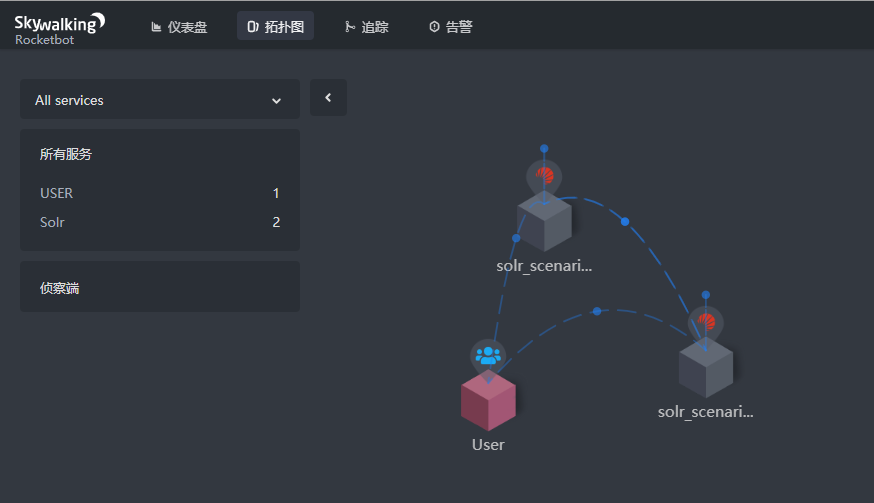
@TinyAllen I noticed in this case, there are instances of one service calling each others, the topology shows a little strange, please take a look. |
|
@dmsolr If the client SolrJ is instrumented, do the topology and metrics still make sense? I notice you are identifying the different shard as different service? Then which peer is SolrJ using? Such as Solr server nodes are |
@wu-sheng The peer of SolrJ Plugin may not be always the same since there're something like 'load balancing' in the request. The SolrJ would contact the zookeeper first to get a Solr node and then send the request to that node (afterwards the request may require communication between Solr nodes such as aggregation), the request may not always be routed to the same node. Am I right? @dmsolr |
|
Great, @kezhenxu94 . |
| @Override | ||
| public Object afterMethod(EnhancedInstance objInst, Method method, Object[] allArguments, Class<?>[] argumentsTypes, | ||
| Object ret) throws Throwable { | ||
| if (method.getName().equals("finishStage")) { |
There was a problem hiding this comment.
i'm a bit confused about if (method.getName().equals("distributedProcess")) in before method and if (method.getName().equals("finishStage")) { in after method
this two method name should be same.but this logic judgment is not
There was a problem hiding this comment.
This span start at distributedProcess() and stop at finishStage().
But I'm pretty sure they always come in pairs.
|
|
||
| @Override | ||
| public void handleMethodException(EnhancedInstance objInst, Method method, Object[] allArguments, Class<?>[] argumentsTypes, Throwable t) { | ||
| if (ContextManager.isActive()) { |
There was a problem hiding this comment.
!request.getPath().startsWith(SKIP_ADMIN_PREF) should be here
There was a problem hiding this comment.
Yes, I notice that. Maybe it is not required. In usually, there is no active span which matches this condition here. (Unless other interceptors create.)
That there is a active span in context, not matter of who created, logs the exception when it is in the method with catching exception. I think.
Could you test about SolrJ plugin works with one node Solr server and multiple nodes cluster? Especially for Topology. I highly doubt the topology will make sense if you do so when APP with Solr cluster. |
|
I have tried it seems like ok.
|
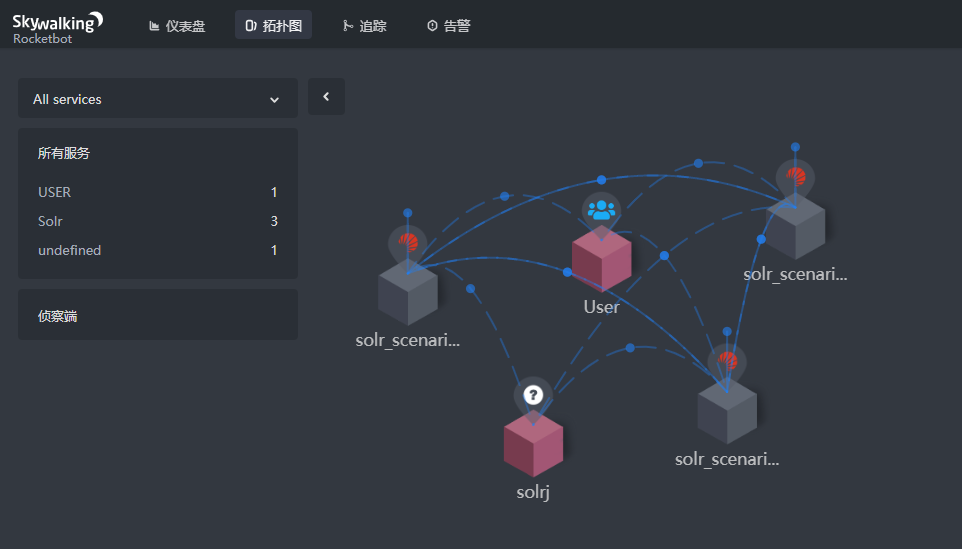
|
What is the user accessing all nodes? Maybe because you are using browser access Solr server? |
|
Yes, I accessed all the nodes through the browser. |
|
OK, if no peer looks like |
|
cc #2871 |
|
SolrJ plugin has been reverted, have to, because it breaks the agent. |
|
FAILURE |
|
Refer to this link for build results (access rights to CI server needed): |
|
|
You need to fix conflict first. |
|
The PR has delayed for long time, so I works in a new branch. This branch lose some commits. Could I close this and open another PR? |
|
move to #3002 |
Please answer these questions before submitting pull request
Why submit this pull request?
Bug fix
New feature provided
Improve performance
Related issues
[Agent] Provide plugin for Solr-7.x #2501