aws: changing default EBS type on masters to gp3.#5239
aws: changing default EBS type on masters to gp3.#5239openshift-merge-robot merged 1 commit intoopenshift:masterfrom
Conversation
To clarify in this exact case if we were to use gp3 as IPI default it would be 20% lower cost? |
@hexfusion yes, it will be 20% lower cost. Currently the default IPI is 120 GiB of gp2 (baseline of 360 IOPS [burst up to 3k] and 128MiB/s throughput*), with gp3 the baseline IOPS will be increased 10x to 3,000 and throughput to will decrease a bit to 125 MiB/s) '* The throughput limit is between 128 MiB/s and 250 MiB/s, depending on the volume size. Volumes smaller than or equal to 170 GiB deliver a maximum throughput of 128 MiB/s. Volumes larger than 170 GiB but smaller than 334 GiB deliver a maximum throughput of 250 MiB/s if burst credits are available. EBS doc |
|
gp3 gp2 aws-e2e seems to show very similar storage metrics. perf and scale team will try some more tests next week. But if we save 20% then we can weigh that against perf changes. |
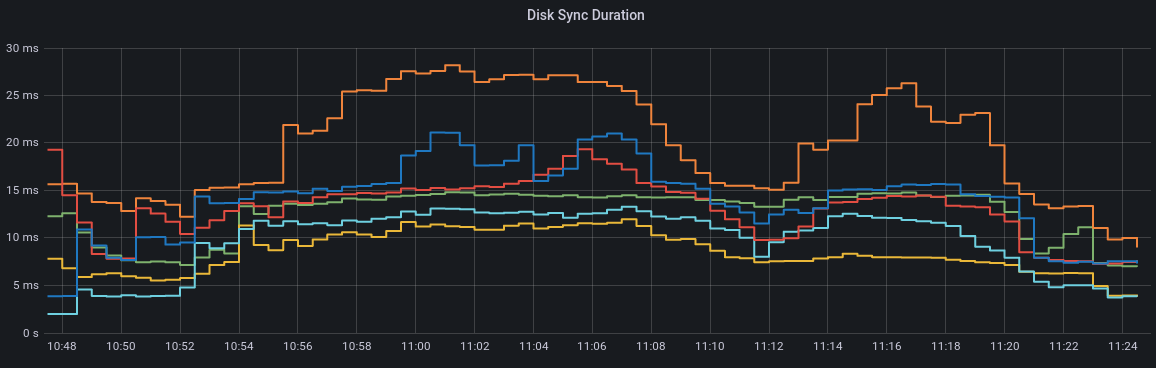
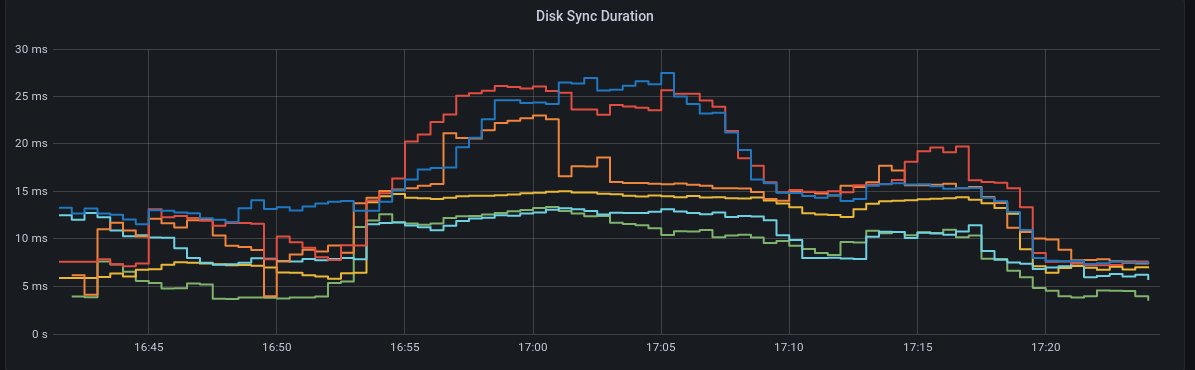
|
The above is a mixture of fsync and backend commit so I have separated those. fsync p99 gp2 backend commit p99 gp3 backend commit p99 gp2 |
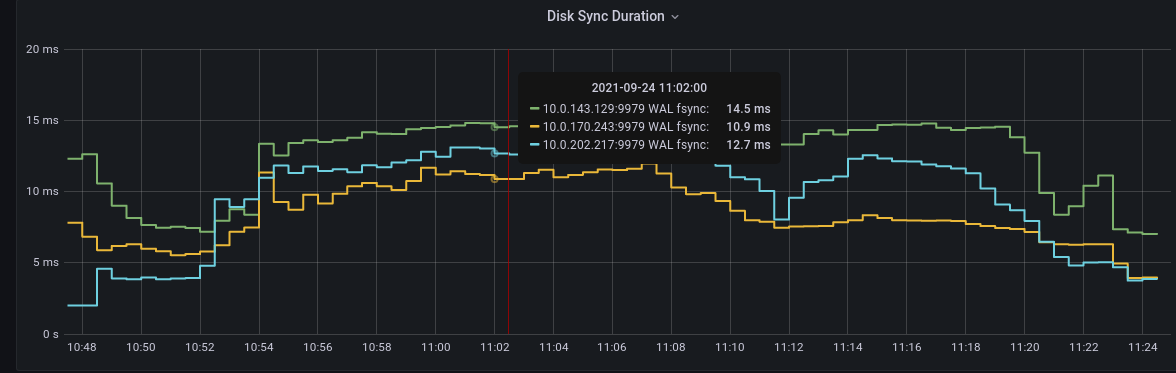
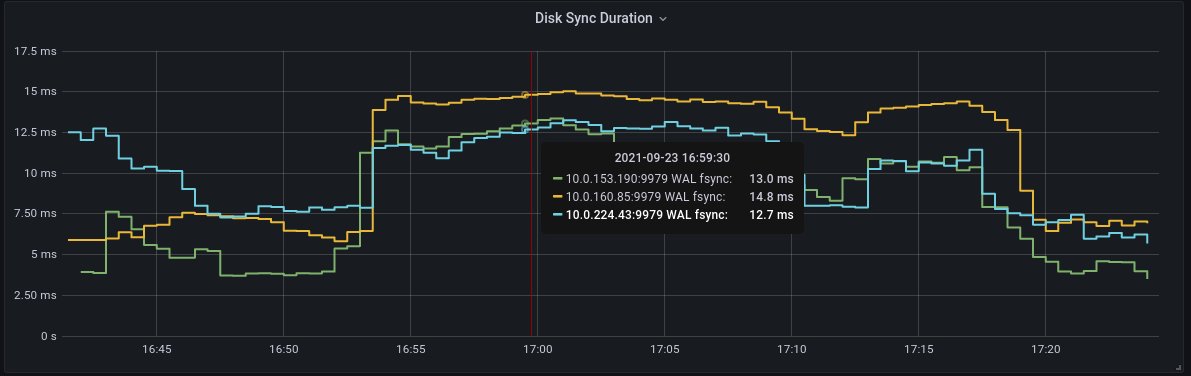
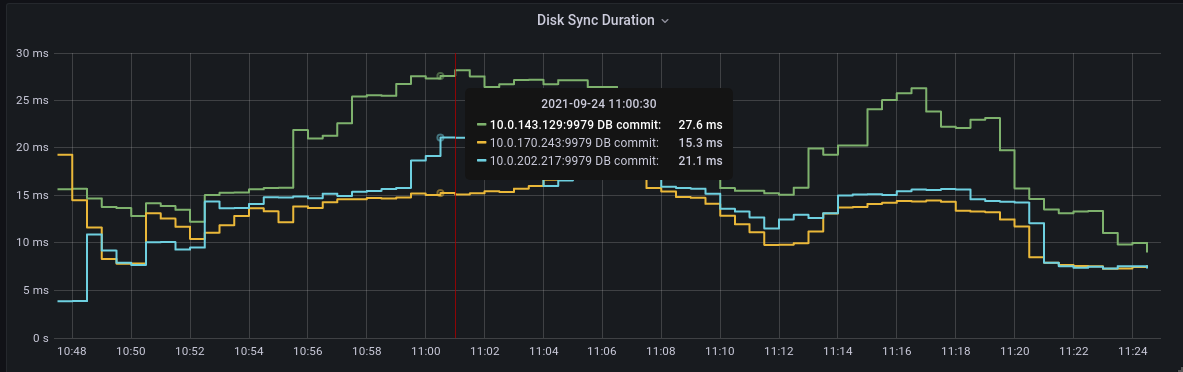
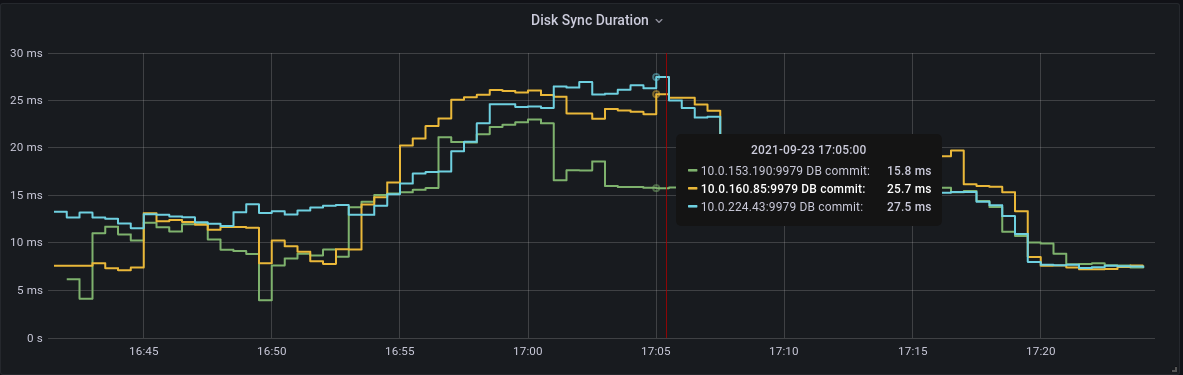
|
@hexfusion yeah, the perf should be similar, no much perceptions in a fresh cluster, but as described in the study case, in a stress scenario (gp2 with no burst credits) gp3 should be much faster and more resilient than gp2. |
|
/retest |
Bump AWS-SDK to minimal version to support gp3 volumes, required to PR to change the default on IPI, WIP on openshift#5239
Add basic gp3 validation on provider to support to change the default control plane volumes on AWS IPI. The basic support means that this change will only make the terraform validate gp3 volumes. The full support should allow to add parameters like volume IOPS and throughput, that is completely new in General Pourpose volumes (introduced in gp3) - and not covereed here as it need more changes on this openshift's fork. References: - openshift/installer#5239 - openshift/installer#5328
Add basic gp3 validation on the provider to support changing the default control-plane volumes on AWS IPI. The basic support means that this change will only make the terraform validate gp3 volumes. The full support should allow adding parameters like volume IOPS and throughput, which is completely new in General Purpose volumes (introduced in gp3) - and not covered here as it needs more changes on this openshift's fork. References: - openshift/installer#5239 - openshift/installer#5328
Depends: - [ ] aws-sdk-go bump to v1.35.37 : openshift#11 References: - upstream support starts on release v3.22.0: hashicorp#16517 - change default vol type on openshift installer: openshift/installer#5239
Add basic support to gp3 volumes on EC2. The full support was introduced on upstream release v3.22.0. This is a second option, without bump SDK to v1.35.37, as described on the PR openshift#12 References: - upstream support starts on release v3.22.0: hashicorp#16517 - change default vol type on openshift installer: openshift/installer#5239
Bump AWS SDK to v1.35.37 to support gp3 volume type. Required to change the default volumes on control-plane, reference: - openshift#5239
Bump terraform-provider-aws to pseudo v2.67.0-openshift-2 to minimal support gp3 volume type. This commit should be updated when the fork's PR will be merged and the new tag 'v2.67.0-openshift-2' is created on the correct repo. Dependency: - openshift/terraform-provider-aws#10 Required to change the default volumes on control-plane, reference: - openshift#5239
Add basic support to gp3 volumes on EC2. The full support was introduced on upstream release v3.22.0. This is a second option, without bump SDK to v1.35.37, as described on the PR openshift#12 References: - upstream support starts on release v3.22.0: hashicorp#16517 - change default vol type on openshift installer: openshift/installer#5239
|
/retest-required Please review the full test history for this PR and help us cut down flakes. |
3 similar comments
|
/retest-required Please review the full test history for this PR and help us cut down flakes. |
|
/retest-required Please review the full test history for this PR and help us cut down flakes. |
|
/retest-required Please review the full test history for this PR and help us cut down flakes. |
|
It seems to be the same flake we've got on #5373 , reported on hashicorp/terraform-provider-aws#16142 . |
|
/retest-required Please review the full test history for this PR and help us cut down flakes. |
6 similar comments
|
/retest-required Please review the full test history for this PR and help us cut down flakes. |
|
/retest-required Please review the full test history for this PR and help us cut down flakes. |
|
/retest-required Please review the full test history for this PR and help us cut down flakes. |
|
/retest-required Please review the full test history for this PR and help us cut down flakes. |
|
/retest-required Please review the full test history for this PR and help us cut down flakes. |
|
/retest-required Please review the full test history for this PR and help us cut down flakes. |
|
@mtulio: The following tests failed, say
Full PR test history. Your PR dashboard. DetailsInstructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository. I understand the commands that are listed here. |
|
/retest-required Please review the full test history for this PR and help us cut down flakes. |
5 similar comments
|
/retest-required Please review the full test history for this PR and help us cut down flakes. |
|
/retest-required Please review the full test history for this PR and help us cut down flakes. |
|
/retest-required Please review the full test history for this PR and help us cut down flakes. |
|
/retest-required Please review the full test history for this PR and help us cut down flakes. |
|
/retest-required Please review the full test history for this PR and help us cut down flakes. |
no longer makes sense to use gp2. See openshift/installer#5239 for motivations.
…_iam, infra.aws.destory and infra.aws.destroy_iam, so that they can be used by external controllers. This is a SQUASH. Signed-off-by: Joshua Packer <jpacker@redhat.com> Convert hosted-cluster-config-operator into subcommand of CPO This commit removes the discrete hosted-cluster-config-operator (HCCO) binary and moves it to become a subcommand of control-plane-operator (CPO). Architectural discussions have led to the conclusion that the logic of HCCO can be incorporated into the CPO itself, since the programs are developed and versioned in lockstep, coexist in the control plane namespace, and have very similar scopes of access and responsibility. Eventually the HCCO could be part of the CPO process itself, but this commit takes an incremental step towards that end by relocating the code and removing the HCCO image. There are two immediate benefits: 1. The control plane image that we incorporate into the OCP payload will become smaller (by shedding the 75MB HCCO binary). 2. The HCCO code will be closer to its final destination (a subpackage of CPO). A future commit can merge HCCO logic into the CPO process and then remove all the associated workload management code for HCCO (SA, role, deployment, etc.). Fix update loops in hosted cluster config operator Before this commit, the CPO was not passing the enable-ci-debug-output flag to the hosted cluster config operator, so we were not detecting update loops in CI. There were a few items causing update loops. This PR enables loop dection for the hosted cluster config operator and fixes resources that were causing update loops. cpo: awsprivatelink: adopt existing Endpoints by tag Packageserver: Wait for availability of catalogsource api This change: * Extends the availability prober to be able to check for a specific resource * Uses that in the packageserver for the catalogsource api * Removes it's exception in the EnsureNoCrashingPods verification Ref https://issues.redhat.com/browse/HOSTEDCP-238 Improve logging for route 53 record clean up Always log something, rather than only logging when there was no error to make sure issues can be debugged. Add support for control plane operator deployed from an OCP payload This commit adds support for deploying the control-plane-operator from an OCP payload. To enable this, the hypershift-operator has been updated to inspect the release specified by a HostedCluster and, if a `hypershift` image is present in the release metadata, that image will be used for the control-plane-operator. Otherwise all the prior lookup behavior remains the same, so the code should be compatible with all existing use cases and should work transparently when an OCP payload containing hypershift is specified. This commit also fixes the token minter, availability prober, and the socks proxy deployments to ensure they are deployed by default from the hypershift image instead of the control-plane-operator's image, as those components are versioned independently of the control plane. A new control-plane-operator `--token-minter-image` flag was added to support this. Finally, this commit reduces the control plane image to include only the control-plane-operator, which is the single component which will be shipped in the OCP payload. MGMT-8604: add Agent Namespace to hostedCluster Agent Platform: Add agent CRDs Add Agent CAPI deployment Update bugzilla component to hypershift Allow installing multiplatform ocp image Fix control plane teardown race with token secret finalization Before this commit, the token controller used finalizers on ignition payload secrets to ensure the token controller's internal cache could be purged upon deleting the underlying secret for the token/payload. This causes the ignition server process to race with namespace termination to clean up the finalizer. When the ignition server process loses the race, the ignition secrets can remain orphaned in the control plane namespace with finalizers that will never be removed, resulting in HostedClusters being stuck deleting. This commit eliminates the race by removing the use of finalizers entirely on the ignition payload secrets. Instead of relying on a finalizer to do internal cleanup, the token cache now internally tracks the secret name from which a given token is derived. With that additional context, the token controller can now reconcile its internal cache when secrets are deleted by simply purging any tokens associated with the a secret which no longer exists. In addition to the above, any additional potential gaps (e.g. a missed delete event, etc.) should eventually resolve as all cache entries have a TTL. Given the extremely small amount of information being stored to begin with (maybe a couple of ignition payloads per NodePool per control plane), this seems like a reasonable best-effort approach. Fix route53 wildcard entry cleanup For public zones, the wildcard entry name was wrong, it has the cluster name as a component and that can not be derived from the zone name. For private zones, it was needlessly complicated, the wildcard entry is simply '*.apps.' + zoneNameWithTrailingDotStripped. zoneNameWithTrailingDotStripped is the same as clusterName + "." + baseDomain, but by directly using the zone name it will work even if the basedomain argument is incorrect. Update scheduler configuration version The version of the configuration that the scheduler requires changed from v1beta1 to v1beta2 with openshift/cluster-kube-scheduler-operator#386 This PR updates the code that generates the configuration to use the new version. Add control plane image to the OCP payload This commit labels the control plane image for inclusion into the official OCP payload image. As of this commit, the control plane image will be shipped with OCP 4.10+ as an OpenShift component. Add missing CAPI provider image overrides This commit adds support for overriding CAPI provider images per HostedCluster via annotations for consistency with the other components which already support overrides. Adds overrides for kubevirt, agent, and AWS. e2e: Dump artifacts if test namespace deletion takes too long This commit updates the e2e scaffolding so that artifacts are dumped if a test's namespace takes too long to be deleted, which usually means there's some kind of teardown lifecycle bug to investigate. Having the state after the point of failure is useful for debugging. docs: Minor update to in-cluster development registry login steps Before this commit, the in-cluster development docs used an `oc registry login` command which could sometimes log the user in to the cluster's internal instead of external registry if the prior steps to enable the external registry hadn't yet completed. This commit updates the login command to make sure the registry login always targets the external registry route. replace default usage of gp2 with gp3 no longer makes sense to use gp2. See openshift/installer#5239 for motivations. feat: Set default security context user for vanilla kube Co-authored-by: gsrajpal <gagandeep.rajpal@ibm.com> add API doc for instance profile field Add generated API docs to `make verify` target This commit updates the `make verify` step to incorporate API docs generation verification by ensuring changes to API types or manual edits to the generated file will cause presubmit build failures. oidc: generate OIDC documents directly docs: add region flag to the `create cluster` example in getting-started Previously, the flow of the getting started guide made it easy to mistakenly create a management cluster and a hosted cluster in different regions. Fix this by adding region flag to the create cluster command. Change func name and add comments for easier code review Signed-off-by: Joshua Packer <jpacker@redhat.com> replace m4.large default with m5.large There is no reason to ever use m4 over m5. m4's are more expensive because it's legacy hardware. m5 is cheaper and better. Updated docs and comments that referred to m5-large too. Crate cluster: Fix --wait panicing with a NPD We changed the create command to Create the HostedCluster rather than ServerSide applying it to make sure it errors if a HostedCluster of that name already exists. Unfortunately, the deserializer clears the TypeMeta field when doing anything other than the serverside apply, so the code that looked at the object kind after the Create to find the HostedCluster will never find anything. Fix it by storing the HostedCluster before doing the Create call. Prevent accidental cluster deletion Before this commit, the hosted cluster controller treated a missing hostedcluster the same as a deleted one. This is incorrect, because any cache or other transient weirdness from the apiserver for a hostedcluster which actually still exists will result in that cluster being accidentally destroyed. Absence of the hostedcluster being reconciled isn't the same as deletion intent. This commit fixes the problem by short-circuiting reconciliation if the requested hostedcluster doesn't exist. If on a subsequent event the resource can be fetched, we'll reconcile it as usual. If we continue to get queued events for a resource the apiserver says isn't found, that could be some other cache or connectivity issue we want to surface and resolve. What we should not do is infer a deletion event from it. Refactor code to reconcile Machine templates This unifies the code to reconcile platform machine templates. Move AWS code into its own file. Additionally this changes existing behaviour to update existing templates in-place rather than creating a new one and rotate. Initially rotation was used to not preclude us from leveraging MachineDeployments rollback ability. This seems unlikey so this PR drops that behaviour which also solves the problem of having to clean up old Machine templates. Add the `--timeout` to the hypershift create cli When adding the `--wait` option to the hypershift create cluster command, if something went wrong, the command will stuck forever. This PR adds the `--timeout` option, so the user can limit the time the command is running. Signed-off-by: Nahshon Unna-Tsameret <nunnatsa@redhat.com> Move Ingress Operator into management cluster to speed up creation This change moves the Ingress Operator into the management cluster in order to speed up cluster creation. I did two testruns with this, in the first it took 698 seconds, in the second 642 seconds to create a cluster. This is about two minutes faster than the fastest run we currently have from CI (14.2 minutes/852 seconds). use NLB for public KAS service type LoadBalancer Add a ClusterVersionSucceeding condition to HostedCluster This commit adds a `ClusterVersionSucceeding` condition to HostedCluster which tracks the `Failing` condition of the hosted cluster's `ClusterVersion` resource. This condition provides additional context about the health of the hosted cluster in the steady state and during release version rollouts. During a rollout, information about individual operator rollout status will be surfaced through this new condition. Fix kube scheduler health/liveness probes In 4.10, the scheduler uses a secure port for its healthz endpoint and it changed the default port that it listens on. In this change we specify the secure port and use that same port for liveness and readiness probes. NodePool CLI: change NodePool CLI to have platform sub command Change the NodePool CLI to be platform aware This change is done as part of the multy platform support, to allow the CLI to provide platform specific UX where needed e2e: Fix periodic tests This commit fixes various e2e issues, and makes the full test suite work again (i.e. the periodics). * Before this commit, the periodic setup code was deploying the "previous" release version passed to the e2e options and then waiting for the "latest" version, causing rollouts to block forever. This is now fixed and made more clear by having the global test setup default clusters to using the "latest" release, and code which wants to do an upgrade must explicitly set options to deploy the "previous" release. * The TestAWSCreateCluster test has been deleted as everything it was doing is covered (and more extensively) by TestUpgradeControlPlane. * Minor fix: before this commit when e2e namespace teardown times out, artifacts were being dumped even when no artifacts directory was specified. Now the dump only happens when an artifacts directly is provided. Add OIDC bucket and region to hypershift-operator-oidc-provider-s3-credentials The `Deployment` generated by `hypershift install` includes OIDC bucket and region information directly as container args. Having those fields in a configmap/secret makes the generated `Deployment` reusable as the config information can be supplied by external processes. This patch modifies the generated s3 credentials secret `hypershift-operator-oidc-provider-s3-credentials` to include the OIDC bucket name and region and sources them into the operator deployment as ENV vars, so they can be interpolated into the container args. This way the deployment generated by `hypershift install` does not contain OIDC configuration data directly but offloads that to the secret. If `--oidc-storage-provider-s3-*` parameter are supplied to `hypershift install` the `Deployment` will change like this ``` *************** *** 23797,23802 **** ! - --oidc-storage-provider-s3-bucket-name=bucket ! - --oidc-storage-provider-s3-region=reg --- 23797,23802 ---- ! - --oidc-storage-provider-s3-bucket-name=$(MY_OIDC_BUCKET) ! - --oidc-storage-provider-s3-region=$(MY_OIDC_REGION) *************** *** 23807,23810 **** --- 23807,23820 ---- env: - name: MY_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace + - name: MY_OIDC_BUCKET + valueFrom: + secretKeyRef: + key: bucket + name: hypershift-operator-oidc-provider-s3-credentials + - name: MY_OIDC_REGION + valueFrom: + secretKeyRef: + key: region + name: hypershift-operator-oidc-provider-s3-credentials ``` and the `Secret` will change like this ``` apiVersion: v1 kind: Secret .... data: + bucket: YnVja2V0 credentials: XXXXXXX + region: cmVn ``` Signed-off-by: Gerd Oberlechner <goberlec@redhat.com> create none honors base-domain Make token-minter more resilient to failures Before this commit, most failure conditions resulted in the token-minter process exiting, which can cause process restart churn under transient conditions like the API server not yet being available or a kubeconfig secret not yet being created. This commit makes the process always retry failed operations until signalled to quit. In addition, the process now uses the `log` package so log output contains timestamps. e2e: Fix cluster dump issues Fixes stdout/stderr output capture from `oc adm` which was broken due to inadvertant stream reassignment on the exec.Cmd. Add options to AgentMachineTemplate - Add Agent options to Nodepool which get copied to AgentMachineTemplates - Make a generic method to list MachineTemplates for deletion on all platforms Fix typo in README This one really bothers me. create agent honors base-domain Limit route53 record permissions to the clusters hostedzones This changes the policies that grant route53 access to only allow managing records in the clusters hosted zones. The ListHostedZones is still unscoped, as it can not be scoped to a specific zone. Ref https://issues.redhat.com/browse/HOSTEDCP-299 Missing GroupVersion on AgentCluster Make kubeadmin optional Fix CLI --timeout flag Before this commit, the --timeout flag to `create cluster` didn't work due to some bug with its stateful approach which I haven't debugged. Instead, this commit just refactors the timeout handling to simply be stateless and propagate a timeout context from each command's Run() method which is trivial enough to just duplicate wherever needed.
This is WIP validation to support gp3 as default on IPI, due to the benefits compared to gp2.
Overview of improvements of gp3 compared to gp2:
More details on the study case on SPLAT-253.
Blockers / dependencies (vendors update):
aws-gp3 support: update vendor aws-sdk-go and terraform-provider-aws #5373