[logs] Aggregates long lines when tailing in a k8s env - part #1#6265
[logs] Aggregates long lines when tailing in a k8s env - part #1#6265
Conversation
5164e89 to
262d561
Compare
262d561 to
10b9ae7
Compare
 ogaca-dd
left a comment
ogaca-dd
left a comment
There was a problem hiding this comment.
LGTM. I am not familiar with this code and so requesting another review might be a good idea. In particular, it is hard to track the logic of rawDataLen.
Note: Test failed.
10b9ae7 to
19d6b97
Compare
The logic behind |
 truthbk
left a comment
truthbk
left a comment
There was a problem hiding this comment.
Looks good to me! Just a couple of questions, and maybe a before and after benchmark after the changes to the pipeline would be nice to get a sense of the impact due to new allocations.
| } | ||
|
|
||
| if parser.SupportsPartialLine() { | ||
| lineParser = NewSingleLineParser(parser, lineHandler) |
There was a problem hiding this comment.
Am I missing something? These two lines in the if and else blocks are identical?
There was a problem hiding this comment.
They are, the subsequent PR add an alternate path cf. #6266
| if err != nil { | ||
| log.Debug(err) | ||
| } | ||
| p.lineHandler.Handle(NewMessage(content, status, input.rawDataLen, timestamp)) |
There was a problem hiding this comment.
I'm not entirely sure, but I feel like the new pipeline (which is way cleaner by the way) might be a little heavier on the allocations side. Any chance we could benchmark or profile the two approaches - just to get a sense of potential performance/memory impact?
There was a problem hiding this comment.
I totally agree that it is likely to be a bit (I will try to find out how much and share numbers) slower. Initially I thought about having some kind of fast path dropping unnecessary step (like the no-op parser) on certain condition. However in the current code base it would have either end up in something a bit hacky, or IMHO a too big change for a single PR. After thinking about the second option I tried to write the current PR a step to a more generic pipeline that would ultimately look like :
[decoder]-(*Message)-> step #1 -(*Message)-> [...] -(*Message)->step #n -(*Message)->[output/forwarder]
So only mandatory block for a given source would then be instantiated, with a unique type circulating between blocks and then we won't get useless allocation for blocks that wouldn't ever be instantiated, and in that extend we should be able, for base cases (like flat file tailing, noop parser, no multiline log), to keep the same performance as we have today.
One "new" block we could implement once that's done ; there have been (surprisingly) a high number of request to support utf-16 encoded log, I think if we rework the pipeline, we could then have an "encoding" block usable for all log sources easily, only enabled based on a to-be-defined config knob value.
This is really opened for discussion, I was about to start an RFC on the topic with the idea of streamlining the logs processing pipeline to describe & discuss what's written above.
There was a problem hiding this comment.
Interested on this RFC!
|
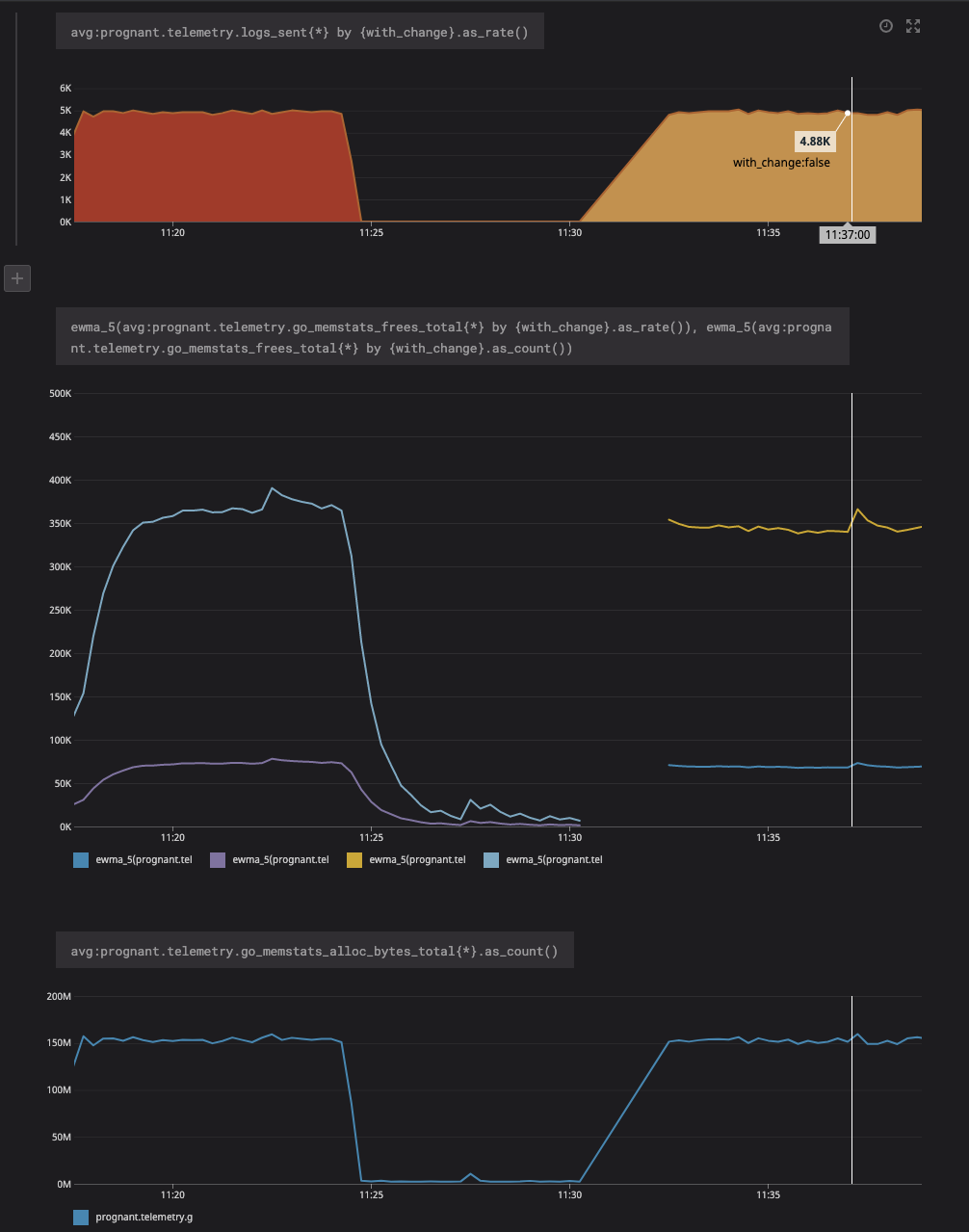
Small benchmark (ec2 t2.medium single file on a ramdisk, set offset to 0 in registry to tail it from the beginning) metrics emitted with this PR are on the left, metrics emitted with master branch are on the right: Overall the processed log per second seems to be stable, the total memory footprint is stable. There is logically a bit more allocations (around 5-7% from what I can tell). |
6ff1b7b to
08291d4
Compare
5fcedcf to
e41caf9
Compare
e41caf9 to
9d94385
Compare
9d94385 to
93b8256
Compare
What does this PR do?
It isolates the parsing logic in the log pipeline (when tailing from file):
It changes
by
Motivation
Make room for additional parsing+buffering logic to support split lines (usecase: log tailing in a k8s environment with explicit tailing from file, lines are split in 16k chunks) and keeps other feature intact.
Additional Notes
It will add a slight overhead.
See subsequent PR #6266 for the release note.
Describe your test plan
Existing UT adjusted.
New UT.
IRL tests.